{"title":"临床文献语料库-真实的,翻译的和合成的替代品,以及分类的领域代理:语料库设计多样性的调查,重点是德语文本数据。","authors":"Udo Hahn","doi":"10.1093/jamiaopen/ooaf024","DOIUrl":null,"url":null,"abstract":"<p><strong>Objective: </strong>We survey clinical document corpora, with a focus on German textual data. Due to rigid data privacy legislation in Germany, these resources, with only few exceptions, are stored in protected clinical data spaces and locked against clinic-external researchers. This situation stands in stark contrast with established workflows in the field of natural language processing, where easy accessibility and reuse of (textual) data collections are common practice. Hence, alternative corpus designs have been examined to escape from data poverty. Besides machine translation of English clinical datasets and the generation of synthetic corpora with fictitious clinical contents, several types of domain proxies have come up as substitutes for real clinical documents. Common instances of close proxies are medical journal publications, therapy guidelines, drug labels, etc., more distant proxies include medical contents from social media channels or online encyclopedic medical articles.</p><p><strong>Methods: </strong>We follow the PRISM (Preferred Reporting Items for Systematic reviews and Meta-analyses) guidelines for surveying the field of German-language clinical/medical corpora. Four bibliographic databases were searched: PubMed, ACL Anthology, Google Scholar, and the author's personal literature database.</p><p><strong>Results: </strong>After PRISM-conformant identification of 362 hits from the 4 bibliographic systems, the screening process yielded 78 relevant documents for inclusion in this review. They contained overall 92 different published versions of corpora, from which 71 were truly unique in terms of their underlying document sets. Out of these, the majority were clinical corpora-46 real ones from which 32 were unique, 5 translated ones (3 unique), and 6 synthetic ones (3 unique). As to domain proxies, we identified 18 close ones (16 unique) and 17 distant ones (all of them unique).</p><p><strong>Discussion: </strong>There is a clear divide between the large number of non-accessible real clinical German-language corpora and their publicly accessible substitutes: translated or synthetic datasets, close or more distant proxies. So, at first sight, the data bottleneck seems broken. Intuitively, yet, differences in genre-specific writing style, lexical or terminological diction, and required medical background expertise in this typological space are also obvious. This raises the question how valid alternative corpus designs really are. A systematic, empirically grounded yardstick for comparing real clinical corpora with those suggested substitutes and proxies is missing until now.</p><p><strong>Conclusion: </strong>The extreme sparsity of real clinical corpora in almost all non-Anglo-American countries worldwide, Germany in particular, has triggered an active search for alternative, publicly accessible data resources laid out in this survey. However, the utility of these substitutes compared with real clinical corpora and their semantic and genre-specific distance to real clinical corpora is still under-researched so that their value remains to be assessed properly. Furthermore, corpus descriptions are often incomplete with respect to relevant descriptional attributes. This paper bundles these observations and proposes a template for a so-called corpus card to improve adequate corpus documentation.</p>","PeriodicalId":36278,"journal":{"name":"JAMIA Open","volume":"8 3","pages":"ooaf024"},"PeriodicalIF":3.4000,"publicationDate":"2025-05-14","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12077144/pdf/","citationCount":"0","resultStr":"{\"title\":\"Clinical document corpora-real ones, translated and synthetic substitutes, and assorted domain proxies: a survey of diversity in corpus design, with focus on German text data.\",\"authors\":\"Udo Hahn\",\"doi\":\"10.1093/jamiaopen/ooaf024\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><strong>Objective: </strong>We survey clinical document corpora, with a focus on German textual data. Due to rigid data privacy legislation in Germany, these resources, with only few exceptions, are stored in protected clinical data spaces and locked against clinic-external researchers. This situation stands in stark contrast with established workflows in the field of natural language processing, where easy accessibility and reuse of (textual) data collections are common practice. Hence, alternative corpus designs have been examined to escape from data poverty. Besides machine translation of English clinical datasets and the generation of synthetic corpora with fictitious clinical contents, several types of domain proxies have come up as substitutes for real clinical documents. Common instances of close proxies are medical journal publications, therapy guidelines, drug labels, etc., more distant proxies include medical contents from social media channels or online encyclopedic medical articles.</p><p><strong>Methods: </strong>We follow the PRISM (Preferred Reporting Items for Systematic reviews and Meta-analyses) guidelines for surveying the field of German-language clinical/medical corpora. Four bibliographic databases were searched: PubMed, ACL Anthology, Google Scholar, and the author's personal literature database.</p><p><strong>Results: </strong>After PRISM-conformant identification of 362 hits from the 4 bibliographic systems, the screening process yielded 78 relevant documents for inclusion in this review. They contained overall 92 different published versions of corpora, from which 71 were truly unique in terms of their underlying document sets. Out of these, the majority were clinical corpora-46 real ones from which 32 were unique, 5 translated ones (3 unique), and 6 synthetic ones (3 unique). As to domain proxies, we identified 18 close ones (16 unique) and 17 distant ones (all of them unique).</p><p><strong>Discussion: </strong>There is a clear divide between the large number of non-accessible real clinical German-language corpora and their publicly accessible substitutes: translated or synthetic datasets, close or more distant proxies. So, at first sight, the data bottleneck seems broken. Intuitively, yet, differences in genre-specific writing style, lexical or terminological diction, and required medical background expertise in this typological space are also obvious. This raises the question how valid alternative corpus designs really are. A systematic, empirically grounded yardstick for comparing real clinical corpora with those suggested substitutes and proxies is missing until now.</p><p><strong>Conclusion: </strong>The extreme sparsity of real clinical corpora in almost all non-Anglo-American countries worldwide, Germany in particular, has triggered an active search for alternative, publicly accessible data resources laid out in this survey. However, the utility of these substitutes compared with real clinical corpora and their semantic and genre-specific distance to real clinical corpora is still under-researched so that their value remains to be assessed properly. Furthermore, corpus descriptions are often incomplete with respect to relevant descriptional attributes. This paper bundles these observations and proposes a template for a so-called corpus card to improve adequate corpus documentation.</p>\",\"PeriodicalId\":36278,\"journal\":{\"name\":\"JAMIA Open\",\"volume\":\"8 3\",\"pages\":\"ooaf024\"},\"PeriodicalIF\":3.4000,\"publicationDate\":\"2025-05-14\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12077144/pdf/\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"JAMIA Open\",\"FirstCategoryId\":\"1085\",\"ListUrlMain\":\"https://doi.org/10.1093/jamiaopen/ooaf024\",\"RegionNum\":0,\"RegionCategory\":null,\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"2025/6/1 0:00:00\",\"PubModel\":\"eCollection\",\"JCR\":\"Q2\",\"JCRName\":\"HEALTH CARE SCIENCES & SERVICES\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"JAMIA Open","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.1093/jamiaopen/ooaf024","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2025/6/1 0:00:00","PubModel":"eCollection","JCR":"Q2","JCRName":"HEALTH CARE SCIENCES & SERVICES","Score":null,"Total":0}
Clinical document corpora-real ones, translated and synthetic substitutes, and assorted domain proxies: a survey of diversity in corpus design, with focus on German text data.
Objective: We survey clinical document corpora, with a focus on German textual data. Due to rigid data privacy legislation in Germany, these resources, with only few exceptions, are stored in protected clinical data spaces and locked against clinic-external researchers. This situation stands in stark contrast with established workflows in the field of natural language processing, where easy accessibility and reuse of (textual) data collections are common practice. Hence, alternative corpus designs have been examined to escape from data poverty. Besides machine translation of English clinical datasets and the generation of synthetic corpora with fictitious clinical contents, several types of domain proxies have come up as substitutes for real clinical documents. Common instances of close proxies are medical journal publications, therapy guidelines, drug labels, etc., more distant proxies include medical contents from social media channels or online encyclopedic medical articles.
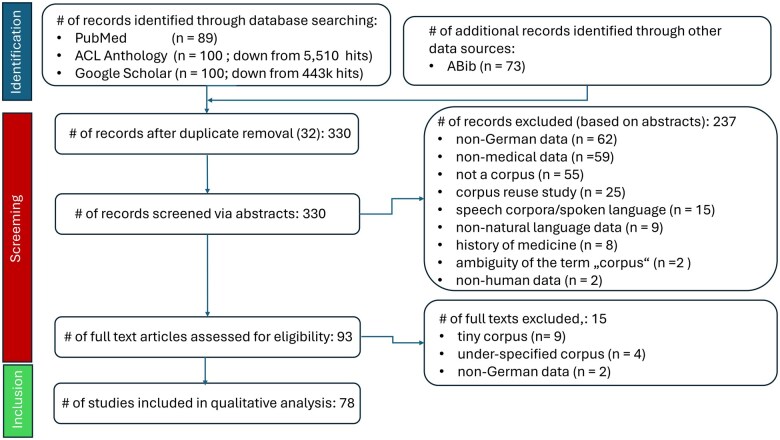
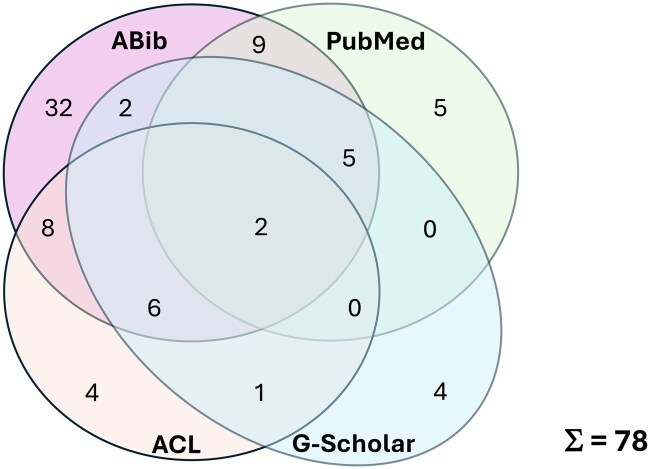
Methods: We follow the PRISM (Preferred Reporting Items for Systematic reviews and Meta-analyses) guidelines for surveying the field of German-language clinical/medical corpora. Four bibliographic databases were searched: PubMed, ACL Anthology, Google Scholar, and the author's personal literature database.
Results: After PRISM-conformant identification of 362 hits from the 4 bibliographic systems, the screening process yielded 78 relevant documents for inclusion in this review. They contained overall 92 different published versions of corpora, from which 71 were truly unique in terms of their underlying document sets. Out of these, the majority were clinical corpora-46 real ones from which 32 were unique, 5 translated ones (3 unique), and 6 synthetic ones (3 unique). As to domain proxies, we identified 18 close ones (16 unique) and 17 distant ones (all of them unique).
Discussion: There is a clear divide between the large number of non-accessible real clinical German-language corpora and their publicly accessible substitutes: translated or synthetic datasets, close or more distant proxies. So, at first sight, the data bottleneck seems broken. Intuitively, yet, differences in genre-specific writing style, lexical or terminological diction, and required medical background expertise in this typological space are also obvious. This raises the question how valid alternative corpus designs really are. A systematic, empirically grounded yardstick for comparing real clinical corpora with those suggested substitutes and proxies is missing until now.
Conclusion: The extreme sparsity of real clinical corpora in almost all non-Anglo-American countries worldwide, Germany in particular, has triggered an active search for alternative, publicly accessible data resources laid out in this survey. However, the utility of these substitutes compared with real clinical corpora and their semantic and genre-specific distance to real clinical corpora is still under-researched so that their value remains to be assessed properly. Furthermore, corpus descriptions are often incomplete with respect to relevant descriptional attributes. This paper bundles these observations and proposes a template for a so-called corpus card to improve adequate corpus documentation.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


