Hossein Hassani, Mohammad Reza Entezarian, Sara Zaeimzadeh, Leila Marvian, Nadejda Komendantova
{"title":"大规模数据链接的过采样-欠采样策略。","authors":"Hossein Hassani, Mohammad Reza Entezarian, Sara Zaeimzadeh, Leila Marvian, Nadejda Komendantova","doi":"10.3389/fdata.2025.1542483","DOIUrl":null,"url":null,"abstract":"<p><p>Effective record linkage in big data, particularly in imbalanced datasets, is a critical yet highly challenging task due to the inherent complexity involved. This article utilizes an oversampling-undersampling strategy to address linkage imbalances, enabling more accurate and efficient record linkage within large-scale datasets. It tries to increase the instances of the minority class and decrease the dominance of the majority classes to try to reach a more balanced dataset that can be used for training and testing. Sensitivity testing was carried out by varying the training-test ratio and degree of imbalance.</p>","PeriodicalId":52859,"journal":{"name":"Frontiers in Big Data","volume":"8 ","pages":"1542483"},"PeriodicalIF":2.4000,"publicationDate":"2025-04-23","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12055850/pdf/","citationCount":"0","resultStr":"{\"title\":\"An oversampling-undersampling strategy for large-scale data linkage.\",\"authors\":\"Hossein Hassani, Mohammad Reza Entezarian, Sara Zaeimzadeh, Leila Marvian, Nadejda Komendantova\",\"doi\":\"10.3389/fdata.2025.1542483\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><p>Effective record linkage in big data, particularly in imbalanced datasets, is a critical yet highly challenging task due to the inherent complexity involved. This article utilizes an oversampling-undersampling strategy to address linkage imbalances, enabling more accurate and efficient record linkage within large-scale datasets. It tries to increase the instances of the minority class and decrease the dominance of the majority classes to try to reach a more balanced dataset that can be used for training and testing. Sensitivity testing was carried out by varying the training-test ratio and degree of imbalance.</p>\",\"PeriodicalId\":52859,\"journal\":{\"name\":\"Frontiers in Big Data\",\"volume\":\"8 \",\"pages\":\"1542483\"},\"PeriodicalIF\":2.4000,\"publicationDate\":\"2025-04-23\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12055850/pdf/\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Frontiers in Big Data\",\"FirstCategoryId\":\"1085\",\"ListUrlMain\":\"https://doi.org/10.3389/fdata.2025.1542483\",\"RegionNum\":0,\"RegionCategory\":null,\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"2025/1/1 0:00:00\",\"PubModel\":\"eCollection\",\"JCR\":\"Q3\",\"JCRName\":\"COMPUTER SCIENCE, INFORMATION SYSTEMS\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Frontiers in Big Data","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.3389/fdata.2025.1542483","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2025/1/1 0:00:00","PubModel":"eCollection","JCR":"Q3","JCRName":"COMPUTER SCIENCE, INFORMATION SYSTEMS","Score":null,"Total":0}
An oversampling-undersampling strategy for large-scale data linkage.
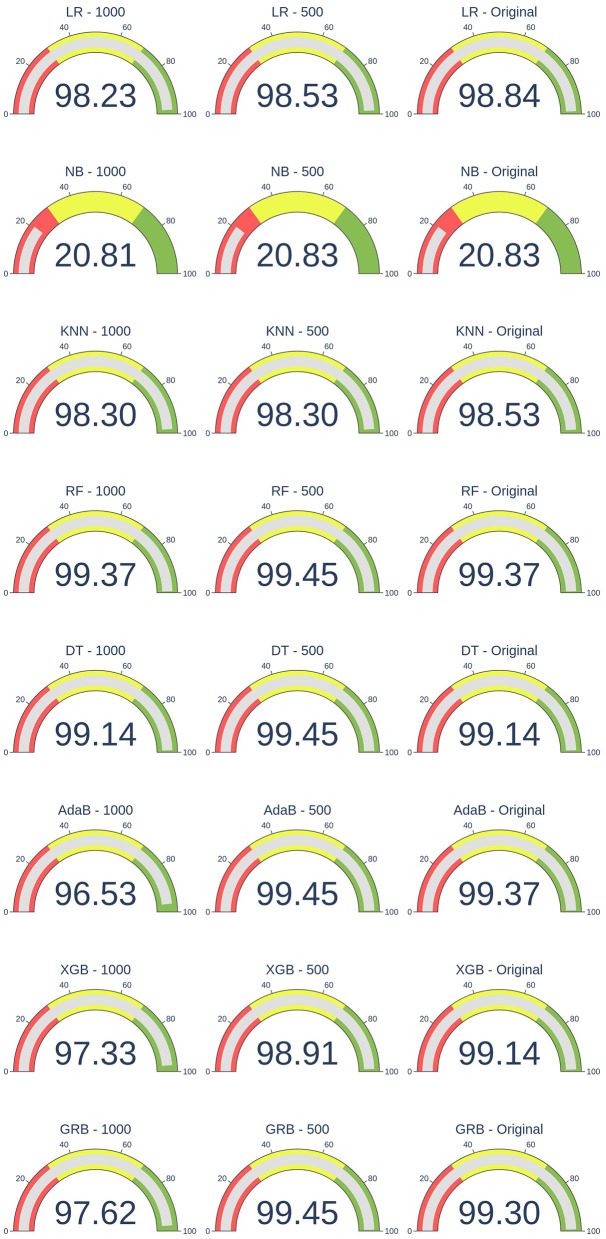
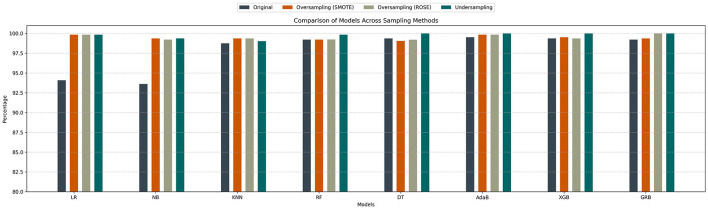
Effective record linkage in big data, particularly in imbalanced datasets, is a critical yet highly challenging task due to the inherent complexity involved. This article utilizes an oversampling-undersampling strategy to address linkage imbalances, enabling more accurate and efficient record linkage within large-scale datasets. It tries to increase the instances of the minority class and decrease the dominance of the majority classes to try to reach a more balanced dataset that can be used for training and testing. Sensitivity testing was carried out by varying the training-test ratio and degree of imbalance.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


