Noirrit Kiran Chandra, Antonio Canale, David B Dunson
{"title":"基于贝叶斯模型的聚类中的维数诅咒。","authors":"Noirrit Kiran Chandra, Antonio Canale, David B Dunson","doi":"","DOIUrl":null,"url":null,"abstract":"<p><p>Bayesian mixture models are widely used for clustering of high-dimensional data with appropriate uncertainty quantification. However, as the dimension of the observations increases, posterior inference often tends to favor too many or too few clusters. This article explains this behavior by studying the random partition posterior in a non-standard setting with a fixed sample size and increasing data dimensionality. We provide conditions under which the finite sample posterior tends to either assign every observation to a different cluster or all observations to the same cluster as the dimension grows. Interestingly, the conditions do not depend on the choice of clustering prior, as long as all possible partitions of observations into clusters have positive prior probabilities, and hold irrespective of the true data-generating model. We then propose a class of latent mixtures for Bayesian clustering (Lamb) on a set of low-dimensional latent variables inducing a partition on the observed data. The model is amenable to scalable posterior inference and we show that it can avoid the pitfalls of high-dimensionality under mild assumptions. The proposed approach is shown to have good performance in simulation studies and an application to inferring cell types based on scRNAseq.</p>","PeriodicalId":50161,"journal":{"name":"Journal of Machine Learning Research","volume":"24 ","pages":""},"PeriodicalIF":5.2000,"publicationDate":"2023-04-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC11999651/pdf/","citationCount":"0","resultStr":"{\"title\":\"Escaping The Curse of Dimensionality in Bayesian Model-Based Clustering.\",\"authors\":\"Noirrit Kiran Chandra, Antonio Canale, David B Dunson\",\"doi\":\"\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><p>Bayesian mixture models are widely used for clustering of high-dimensional data with appropriate uncertainty quantification. However, as the dimension of the observations increases, posterior inference often tends to favor too many or too few clusters. This article explains this behavior by studying the random partition posterior in a non-standard setting with a fixed sample size and increasing data dimensionality. We provide conditions under which the finite sample posterior tends to either assign every observation to a different cluster or all observations to the same cluster as the dimension grows. Interestingly, the conditions do not depend on the choice of clustering prior, as long as all possible partitions of observations into clusters have positive prior probabilities, and hold irrespective of the true data-generating model. We then propose a class of latent mixtures for Bayesian clustering (Lamb) on a set of low-dimensional latent variables inducing a partition on the observed data. The model is amenable to scalable posterior inference and we show that it can avoid the pitfalls of high-dimensionality under mild assumptions. The proposed approach is shown to have good performance in simulation studies and an application to inferring cell types based on scRNAseq.</p>\",\"PeriodicalId\":50161,\"journal\":{\"name\":\"Journal of Machine Learning Research\",\"volume\":\"24 \",\"pages\":\"\"},\"PeriodicalIF\":5.2000,\"publicationDate\":\"2023-04-01\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC11999651/pdf/\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Journal of Machine Learning Research\",\"FirstCategoryId\":\"94\",\"ListUrlMain\":\"\",\"RegionNum\":3,\"RegionCategory\":\"计算机科学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q1\",\"JCRName\":\"AUTOMATION & CONTROL SYSTEMS\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Journal of Machine Learning Research","FirstCategoryId":"94","ListUrlMain":"","RegionNum":3,"RegionCategory":"计算机科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"AUTOMATION & CONTROL SYSTEMS","Score":null,"Total":0}
Escaping The Curse of Dimensionality in Bayesian Model-Based Clustering.
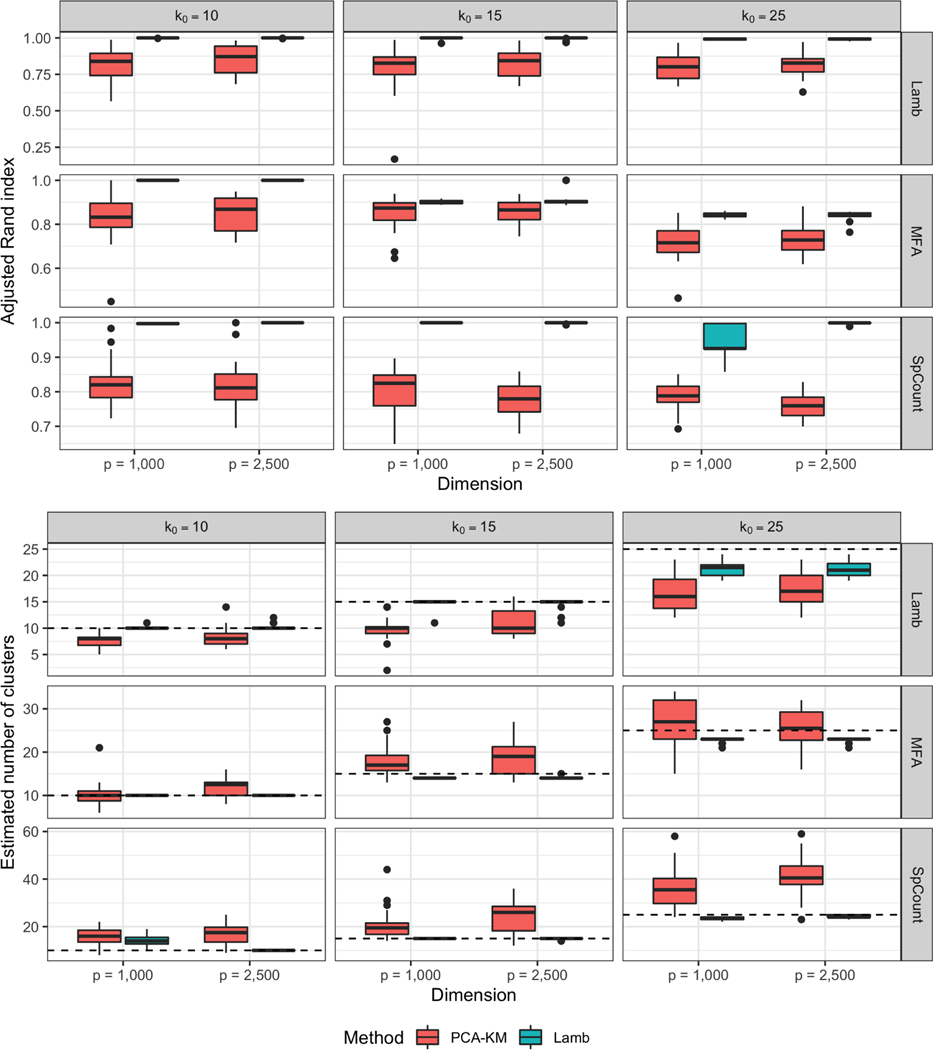
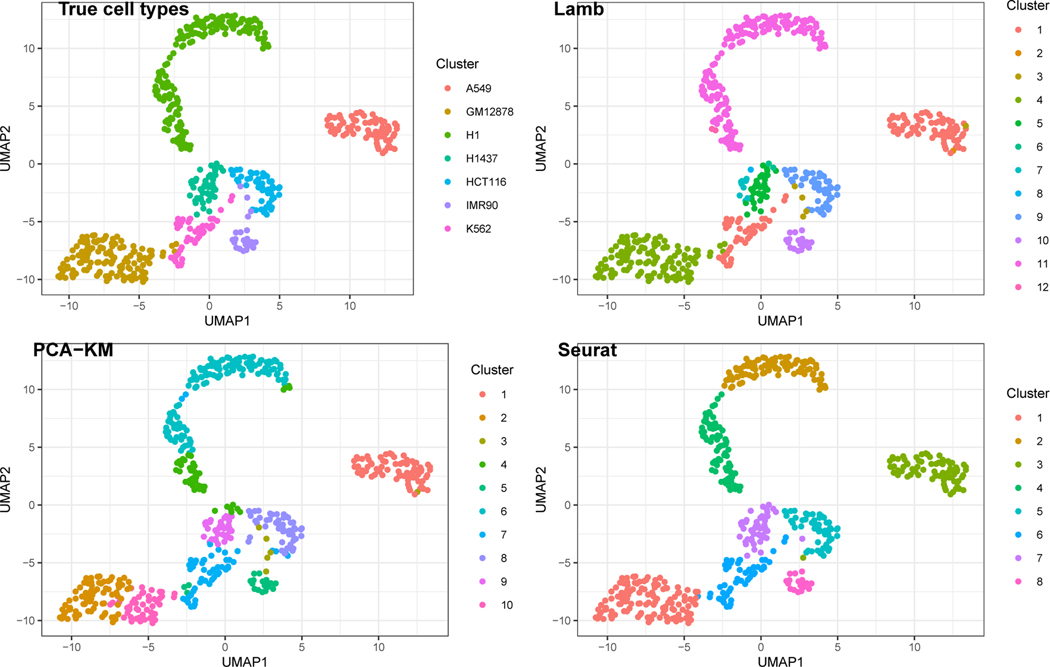
Bayesian mixture models are widely used for clustering of high-dimensional data with appropriate uncertainty quantification. However, as the dimension of the observations increases, posterior inference often tends to favor too many or too few clusters. This article explains this behavior by studying the random partition posterior in a non-standard setting with a fixed sample size and increasing data dimensionality. We provide conditions under which the finite sample posterior tends to either assign every observation to a different cluster or all observations to the same cluster as the dimension grows. Interestingly, the conditions do not depend on the choice of clustering prior, as long as all possible partitions of observations into clusters have positive prior probabilities, and hold irrespective of the true data-generating model. We then propose a class of latent mixtures for Bayesian clustering (Lamb) on a set of low-dimensional latent variables inducing a partition on the observed data. The model is amenable to scalable posterior inference and we show that it can avoid the pitfalls of high-dimensionality under mild assumptions. The proposed approach is shown to have good performance in simulation studies and an application to inferring cell types based on scRNAseq.
期刊介绍:
The Journal of Machine Learning Research (JMLR) provides an international forum for the electronic and paper publication of high-quality scholarly articles in all areas of machine learning. All published papers are freely available online.
JMLR has a commitment to rigorous yet rapid reviewing.
JMLR seeks previously unpublished papers on machine learning that contain:
new principled algorithms with sound empirical validation, and with justification of theoretical, psychological, or biological nature;
experimental and/or theoretical studies yielding new insight into the design and behavior of learning in intelligent systems;
accounts of applications of existing techniques that shed light on the strengths and weaknesses of the methods;
formalization of new learning tasks (e.g., in the context of new applications) and of methods for assessing performance on those tasks;
development of new analytical frameworks that advance theoretical studies of practical learning methods;
computational models of data from natural learning systems at the behavioral or neural level; or extremely well-written surveys of existing work.


 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


