Ana Grilo, Catarina Marques, Maria Corte-Real, Elisabete Carolino, Marco Caetano
{"title":"评估ChatGPT对放疗相关患者询问反应的质量和可靠性:与GPT-3.5和GPT-4的比较研究","authors":"Ana Grilo, Catarina Marques, Maria Corte-Real, Elisabete Carolino, Marco Caetano","doi":"10.2196/63677","DOIUrl":null,"url":null,"abstract":"<p><strong>Background: </strong>Patients frequently resort to the internet to access information about cancer. However, these websites often lack content accuracy and readability. Recently, ChatGPT, an artificial intelligence-powered chatbot, has signified a potential paradigm shift in how patients with cancer can access vast amounts of medical information, including insights into radiotherapy. However, the quality of the information provided by ChatGPT remains unclear. This is particularly significant given the general public's limited knowledge of this treatment and concerns about its possible side effects. Furthermore, evaluating the quality of responses is crucial, as misinformation can foster a false sense of knowledge and security, lead to noncompliance, and result in delays in receiving appropriate treatment.</p><p><strong>Objective: </strong>This study aims to evaluate the quality and reliability of ChatGPT's responses to common patient queries about radiotherapy, comparing the performance of ChatGPT's two versions: GPT-3.5 and GPT-4.</p><p><strong>Methods: </strong>We selected 40 commonly asked radiotherapy questions and entered the queries in both versions of ChatGPT. Response quality and reliability were evaluated by 16 radiotherapy experts using the General Quality Score (GQS), a 5-point Likert scale, with the median GQS determined based on the experts' ratings. Consistency and similarity of responses were assessed using the cosine similarity score, which ranges from 0 (complete dissimilarity) to 1 (complete similarity). Readability was analyzed using the Flesch Reading Ease Score, ranging from 0 to 100, and the Flesch-Kincaid Grade Level, reflecting the average number of years of education required for comprehension. Statistical analyses were performed using the Mann-Whitney test and effect size, with results deemed significant at a 5% level (P=.05). To assess agreement between experts, Krippendorff α and Fleiss κ were used.</p><p><strong>Results: </strong>GPT-4 demonstrated superior performance, with a higher GQS and a lower number of scores of 1 and 2, compared to GPT-3.5. The Mann-Whitney test revealed statistically significant differences in some questions, with GPT-4 generally receiving higher ratings. The median (IQR) cosine similarity score indicated substantial similarity (0.81, IQR 0.05) and consistency in the responses of both versions (GPT-3.5: 0.85, IQR 0.04; GPT-4: 0.83, IQR 0.04). Readability scores for both versions were considered college level, with GPT-4 scoring slightly better in the Flesch Reading Ease Score (34.61) and Flesch-Kincaid Grade Level (12.32) compared to GPT-3.5 (32.98 and 13.32, respectively). Responses by both versions were deemed challenging for the general public.</p><p><strong>Conclusions: </strong>Both GPT-3.5 and GPT-4 demonstrated having the capability to address radiotherapy concepts, with GPT-4 showing superior performance. However, both models present readability challenges for the general population. Although ChatGPT demonstrates potential as a valuable resource for addressing common patient queries related to radiotherapy, it is imperative to acknowledge its limitations, including the risks of misinformation and readability issues. In addition, its implementation should be supported by strategies to enhance accessibility and readability.</p>","PeriodicalId":45538,"journal":{"name":"JMIR Cancer","volume":"11 ","pages":"e63677"},"PeriodicalIF":2.7000,"publicationDate":"2025-04-16","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12017613/pdf/","citationCount":"0","resultStr":"{\"title\":\"Assessing the Quality and Reliability of ChatGPT's Responses to Radiotherapy-Related Patient Queries: Comparative Study With GPT-3.5 and GPT-4.\",\"authors\":\"Ana Grilo, Catarina Marques, Maria Corte-Real, Elisabete Carolino, Marco Caetano\",\"doi\":\"10.2196/63677\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><strong>Background: </strong>Patients frequently resort to the internet to access information about cancer. However, these websites often lack content accuracy and readability. Recently, ChatGPT, an artificial intelligence-powered chatbot, has signified a potential paradigm shift in how patients with cancer can access vast amounts of medical information, including insights into radiotherapy. However, the quality of the information provided by ChatGPT remains unclear. This is particularly significant given the general public's limited knowledge of this treatment and concerns about its possible side effects. Furthermore, evaluating the quality of responses is crucial, as misinformation can foster a false sense of knowledge and security, lead to noncompliance, and result in delays in receiving appropriate treatment.</p><p><strong>Objective: </strong>This study aims to evaluate the quality and reliability of ChatGPT's responses to common patient queries about radiotherapy, comparing the performance of ChatGPT's two versions: GPT-3.5 and GPT-4.</p><p><strong>Methods: </strong>We selected 40 commonly asked radiotherapy questions and entered the queries in both versions of ChatGPT. Response quality and reliability were evaluated by 16 radiotherapy experts using the General Quality Score (GQS), a 5-point Likert scale, with the median GQS determined based on the experts' ratings. Consistency and similarity of responses were assessed using the cosine similarity score, which ranges from 0 (complete dissimilarity) to 1 (complete similarity). Readability was analyzed using the Flesch Reading Ease Score, ranging from 0 to 100, and the Flesch-Kincaid Grade Level, reflecting the average number of years of education required for comprehension. Statistical analyses were performed using the Mann-Whitney test and effect size, with results deemed significant at a 5% level (P=.05). To assess agreement between experts, Krippendorff α and Fleiss κ were used.</p><p><strong>Results: </strong>GPT-4 demonstrated superior performance, with a higher GQS and a lower number of scores of 1 and 2, compared to GPT-3.5. The Mann-Whitney test revealed statistically significant differences in some questions, with GPT-4 generally receiving higher ratings. The median (IQR) cosine similarity score indicated substantial similarity (0.81, IQR 0.05) and consistency in the responses of both versions (GPT-3.5: 0.85, IQR 0.04; GPT-4: 0.83, IQR 0.04). Readability scores for both versions were considered college level, with GPT-4 scoring slightly better in the Flesch Reading Ease Score (34.61) and Flesch-Kincaid Grade Level (12.32) compared to GPT-3.5 (32.98 and 13.32, respectively). Responses by both versions were deemed challenging for the general public.</p><p><strong>Conclusions: </strong>Both GPT-3.5 and GPT-4 demonstrated having the capability to address radiotherapy concepts, with GPT-4 showing superior performance. However, both models present readability challenges for the general population. Although ChatGPT demonstrates potential as a valuable resource for addressing common patient queries related to radiotherapy, it is imperative to acknowledge its limitations, including the risks of misinformation and readability issues. In addition, its implementation should be supported by strategies to enhance accessibility and readability.</p>\",\"PeriodicalId\":45538,\"journal\":{\"name\":\"JMIR Cancer\",\"volume\":\"11 \",\"pages\":\"e63677\"},\"PeriodicalIF\":2.7000,\"publicationDate\":\"2025-04-16\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12017613/pdf/\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"JMIR Cancer\",\"FirstCategoryId\":\"1085\",\"ListUrlMain\":\"https://doi.org/10.2196/63677\",\"RegionNum\":0,\"RegionCategory\":null,\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q2\",\"JCRName\":\"ONCOLOGY\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"JMIR Cancer","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.2196/63677","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q2","JCRName":"ONCOLOGY","Score":null,"Total":0}
Assessing the Quality and Reliability of ChatGPT's Responses to Radiotherapy-Related Patient Queries: Comparative Study With GPT-3.5 and GPT-4.
Background: Patients frequently resort to the internet to access information about cancer. However, these websites often lack content accuracy and readability. Recently, ChatGPT, an artificial intelligence-powered chatbot, has signified a potential paradigm shift in how patients with cancer can access vast amounts of medical information, including insights into radiotherapy. However, the quality of the information provided by ChatGPT remains unclear. This is particularly significant given the general public's limited knowledge of this treatment and concerns about its possible side effects. Furthermore, evaluating the quality of responses is crucial, as misinformation can foster a false sense of knowledge and security, lead to noncompliance, and result in delays in receiving appropriate treatment.
Objective: This study aims to evaluate the quality and reliability of ChatGPT's responses to common patient queries about radiotherapy, comparing the performance of ChatGPT's two versions: GPT-3.5 and GPT-4.
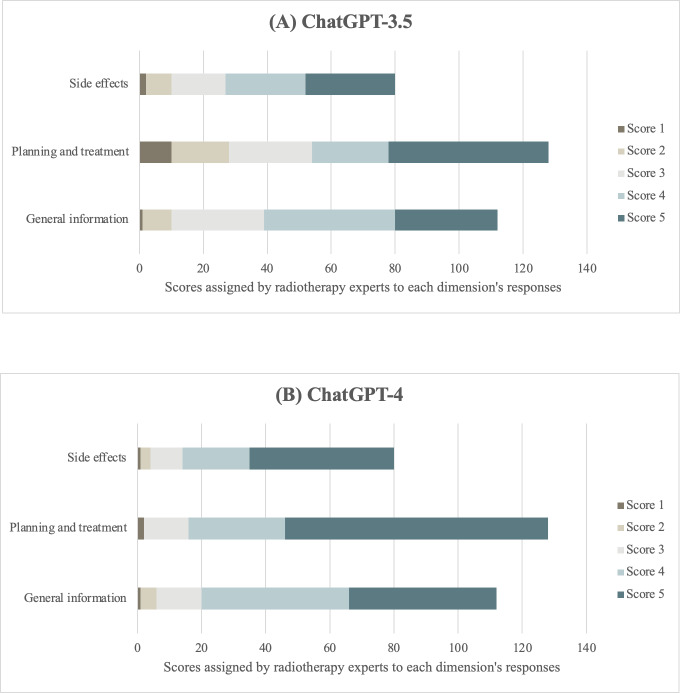
Methods: We selected 40 commonly asked radiotherapy questions and entered the queries in both versions of ChatGPT. Response quality and reliability were evaluated by 16 radiotherapy experts using the General Quality Score (GQS), a 5-point Likert scale, with the median GQS determined based on the experts' ratings. Consistency and similarity of responses were assessed using the cosine similarity score, which ranges from 0 (complete dissimilarity) to 1 (complete similarity). Readability was analyzed using the Flesch Reading Ease Score, ranging from 0 to 100, and the Flesch-Kincaid Grade Level, reflecting the average number of years of education required for comprehension. Statistical analyses were performed using the Mann-Whitney test and effect size, with results deemed significant at a 5% level (P=.05). To assess agreement between experts, Krippendorff α and Fleiss κ were used.
Results: GPT-4 demonstrated superior performance, with a higher GQS and a lower number of scores of 1 and 2, compared to GPT-3.5. The Mann-Whitney test revealed statistically significant differences in some questions, with GPT-4 generally receiving higher ratings. The median (IQR) cosine similarity score indicated substantial similarity (0.81, IQR 0.05) and consistency in the responses of both versions (GPT-3.5: 0.85, IQR 0.04; GPT-4: 0.83, IQR 0.04). Readability scores for both versions were considered college level, with GPT-4 scoring slightly better in the Flesch Reading Ease Score (34.61) and Flesch-Kincaid Grade Level (12.32) compared to GPT-3.5 (32.98 and 13.32, respectively). Responses by both versions were deemed challenging for the general public.
Conclusions: Both GPT-3.5 and GPT-4 demonstrated having the capability to address radiotherapy concepts, with GPT-4 showing superior performance. However, both models present readability challenges for the general population. Although ChatGPT demonstrates potential as a valuable resource for addressing common patient queries related to radiotherapy, it is imperative to acknowledge its limitations, including the risks of misinformation and readability issues. In addition, its implementation should be supported by strategies to enhance accessibility and readability.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


