{"title":"评估ChatGPT-4在FRCR第一部分试题中识别放射解剖学的性能。","authors":"Pradosh Kumar Sarangi, Suvrankar Datta, Braja Behari Panda, Swaha Panda, Himel Mondal","doi":"10.1055/s-0044-1792040","DOIUrl":null,"url":null,"abstract":"<p><p><b>Background</b> Radiology is critical for diagnosis and patient care, relying heavily on accurate image interpretation. Recent advancements in artificial intelligence (AI) and natural language processing (NLP) have raised interest in the potential of AI models to support radiologists, although robust research on AI performance in this field is still emerging. <b>Objective</b> This study aimed to assess the efficacy of ChatGPT-4 in answering radiological anatomy questions similar to those in the Fellowship of the Royal College of Radiologists (FRCR) Part 1 Anatomy examination. <b>Materials and Methods</b> We used 100 mock radiological anatomy questions from a free Web site patterned after the FRCR Part 1 Anatomy examination. ChatGPT-4 was tested under two conditions: with and without context regarding the examination instructions and question format. The main query posed was: \"Identify the structure indicated by the arrow(s).\" Responses were evaluated against correct answers, and two expert radiologists (>5 and 30 years of experience in radiology diagnostics and academics) rated the explanation of the answers. We calculated four scores: correctness, sidedness, modality identification, and approximation. The latter considers partial correctness if the identified structure is present but not the focus of the question. <b>Results</b> Both testing conditions saw ChatGPT-4 underperform, with correctness scores of 4 and 7.5% for no context and with context, respectively. However, it identified the imaging modality with 100% accuracy. The model scored over 50% on the approximation metric, where it identified present structures not indicated by the arrow. However, it struggled with identifying the correct side of the structure, scoring approximately 42 and 40% in the no context and with context settings, respectively. Only 32% of the responses were similar across the two settings. <b>Conclusion</b> Despite its ability to correctly recognize the imaging modality, ChatGPT-4 has significant limitations in interpreting normal radiological anatomy. This indicates the necessity for enhanced training in normal anatomy to better interpret abnormal radiological images. Identifying the correct side of structures in radiological images also remains a challenge for ChatGPT-4.</p>","PeriodicalId":51597,"journal":{"name":"Indian Journal of Radiology and Imaging","volume":"35 2","pages":"287-294"},"PeriodicalIF":1.0000,"publicationDate":"2024-11-04","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12034419/pdf/","citationCount":"0","resultStr":"{\"title\":\"Evaluating ChatGPT-4's Performance in Identifying Radiological Anatomy in FRCR Part 1 Examination Questions.\",\"authors\":\"Pradosh Kumar Sarangi, Suvrankar Datta, Braja Behari Panda, Swaha Panda, Himel Mondal\",\"doi\":\"10.1055/s-0044-1792040\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><p><b>Background</b> Radiology is critical for diagnosis and patient care, relying heavily on accurate image interpretation. Recent advancements in artificial intelligence (AI) and natural language processing (NLP) have raised interest in the potential of AI models to support radiologists, although robust research on AI performance in this field is still emerging. <b>Objective</b> This study aimed to assess the efficacy of ChatGPT-4 in answering radiological anatomy questions similar to those in the Fellowship of the Royal College of Radiologists (FRCR) Part 1 Anatomy examination. <b>Materials and Methods</b> We used 100 mock radiological anatomy questions from a free Web site patterned after the FRCR Part 1 Anatomy examination. ChatGPT-4 was tested under two conditions: with and without context regarding the examination instructions and question format. The main query posed was: \\\"Identify the structure indicated by the arrow(s).\\\" Responses were evaluated against correct answers, and two expert radiologists (>5 and 30 years of experience in radiology diagnostics and academics) rated the explanation of the answers. We calculated four scores: correctness, sidedness, modality identification, and approximation. The latter considers partial correctness if the identified structure is present but not the focus of the question. <b>Results</b> Both testing conditions saw ChatGPT-4 underperform, with correctness scores of 4 and 7.5% for no context and with context, respectively. However, it identified the imaging modality with 100% accuracy. The model scored over 50% on the approximation metric, where it identified present structures not indicated by the arrow. However, it struggled with identifying the correct side of the structure, scoring approximately 42 and 40% in the no context and with context settings, respectively. Only 32% of the responses were similar across the two settings. <b>Conclusion</b> Despite its ability to correctly recognize the imaging modality, ChatGPT-4 has significant limitations in interpreting normal radiological anatomy. This indicates the necessity for enhanced training in normal anatomy to better interpret abnormal radiological images. Identifying the correct side of structures in radiological images also remains a challenge for ChatGPT-4.</p>\",\"PeriodicalId\":51597,\"journal\":{\"name\":\"Indian Journal of Radiology and Imaging\",\"volume\":\"35 2\",\"pages\":\"287-294\"},\"PeriodicalIF\":1.0000,\"publicationDate\":\"2024-11-04\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12034419/pdf/\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Indian Journal of Radiology and Imaging\",\"FirstCategoryId\":\"1085\",\"ListUrlMain\":\"https://doi.org/10.1055/s-0044-1792040\",\"RegionNum\":0,\"RegionCategory\":null,\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"2025/4/1 0:00:00\",\"PubModel\":\"eCollection\",\"JCR\":\"Q4\",\"JCRName\":\"RADIOLOGY, NUCLEAR MEDICINE & MEDICAL IMAGING\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Indian Journal of Radiology and Imaging","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.1055/s-0044-1792040","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2025/4/1 0:00:00","PubModel":"eCollection","JCR":"Q4","JCRName":"RADIOLOGY, NUCLEAR MEDICINE & MEDICAL IMAGING","Score":null,"Total":0}
Evaluating ChatGPT-4's Performance in Identifying Radiological Anatomy in FRCR Part 1 Examination Questions.
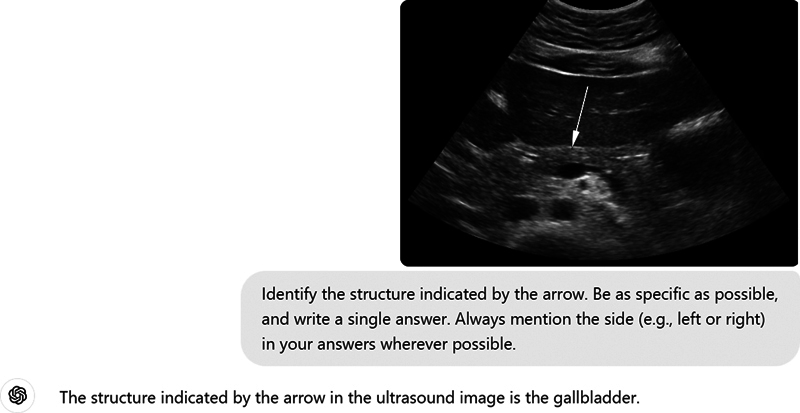
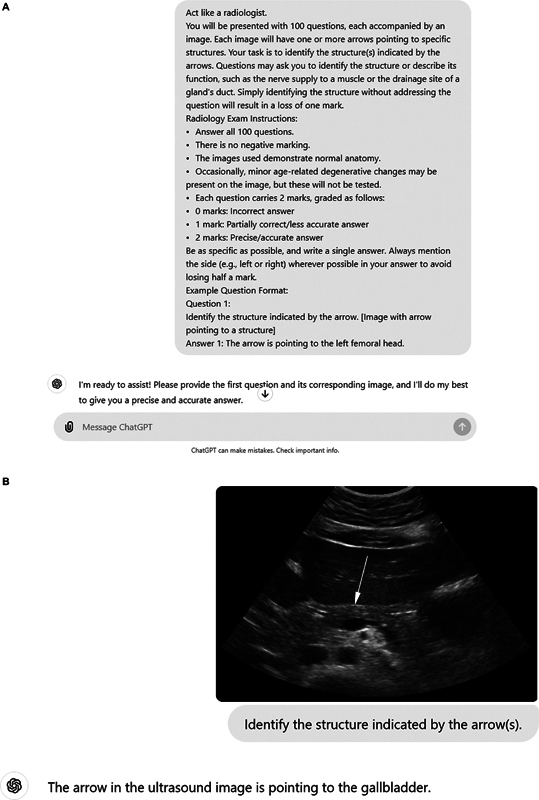
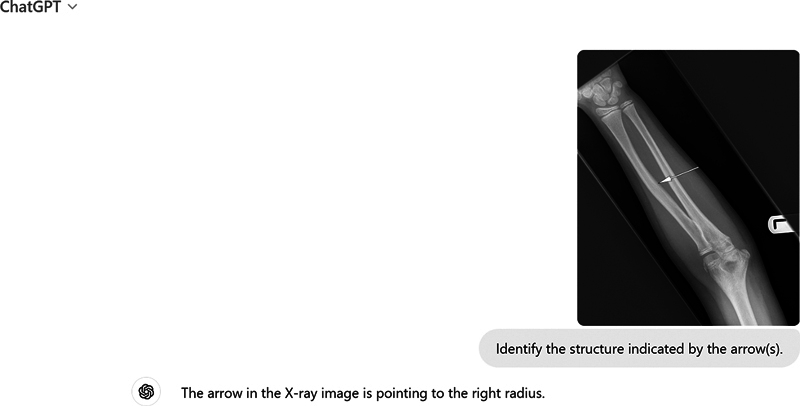
Background Radiology is critical for diagnosis and patient care, relying heavily on accurate image interpretation. Recent advancements in artificial intelligence (AI) and natural language processing (NLP) have raised interest in the potential of AI models to support radiologists, although robust research on AI performance in this field is still emerging. Objective This study aimed to assess the efficacy of ChatGPT-4 in answering radiological anatomy questions similar to those in the Fellowship of the Royal College of Radiologists (FRCR) Part 1 Anatomy examination. Materials and Methods We used 100 mock radiological anatomy questions from a free Web site patterned after the FRCR Part 1 Anatomy examination. ChatGPT-4 was tested under two conditions: with and without context regarding the examination instructions and question format. The main query posed was: "Identify the structure indicated by the arrow(s)." Responses were evaluated against correct answers, and two expert radiologists (>5 and 30 years of experience in radiology diagnostics and academics) rated the explanation of the answers. We calculated four scores: correctness, sidedness, modality identification, and approximation. The latter considers partial correctness if the identified structure is present but not the focus of the question. Results Both testing conditions saw ChatGPT-4 underperform, with correctness scores of 4 and 7.5% for no context and with context, respectively. However, it identified the imaging modality with 100% accuracy. The model scored over 50% on the approximation metric, where it identified present structures not indicated by the arrow. However, it struggled with identifying the correct side of the structure, scoring approximately 42 and 40% in the no context and with context settings, respectively. Only 32% of the responses were similar across the two settings. Conclusion Despite its ability to correctly recognize the imaging modality, ChatGPT-4 has significant limitations in interpreting normal radiological anatomy. This indicates the necessity for enhanced training in normal anatomy to better interpret abnormal radiological images. Identifying the correct side of structures in radiological images also remains a challenge for ChatGPT-4.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


