{"title":"基于集成学习的超增强器识别。","authors":"Wenying He, Jialu Xu, Yun Zuo, Yude Bai, Fei Guo","doi":"10.1093/bfgp/elaf003","DOIUrl":null,"url":null,"abstract":"<p><p>Super-enhancers (SEs) are typically located in the regulatory regions of genes, driving high-level gene expression. Identifying SEs is crucial for a deeper understanding of gene regulatory networks, disease mechanisms, and the development and physiological processes of organisms, thus exerting a profound impact on research and applications in the life sciences field. Traditional experimental methods for identifying SEs are costly and time-consuming. Existing methods for predicting SEs based solely on sequence data use deep learning for feature representation and have achieved good results. However, they overlook biological features related to physicochemical properties, leading to low interpretability. Additionally, the complex model structure often requires extensive labeled data for training, which limits their further application in biological data. In this paper, we integrate the strengths of different models and proposes an ensemble model based on an integration strategy to enhance the model's generalization ability. It designs a multi-angle feature representation method that combines local structure and global information to extract high-dimensional abstract relationships and key low-dimensional biological features from sequences. This enhances the effectiveness and interpretability of the model's input features, providing technical support for discovering cell-specific and species-specific patterns of SEs. We evaluated the performance on both mouse and human datasets using five metrics, including area under the receiver operating characteristic curve accuracy, and others. Compared to the latest models, EnsembleSE achieved an average improvement of 4.5% in F1 score and an average improvement of 8.05% in recall, demonstrating the robustness and adaptability of the model on a unified test set. Source codes are available at https://github.com/2103374200/EnsembleSE-main.</p>","PeriodicalId":55323,"journal":{"name":"Briefings in Functional Genomics","volume":"24 ","pages":""},"PeriodicalIF":2.5000,"publicationDate":"2025-01-15","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12008123/pdf/","citationCount":"0","resultStr":"{\"title\":\"EnsembleSE: identification of super-enhancers based on ensemble learning.\",\"authors\":\"Wenying He, Jialu Xu, Yun Zuo, Yude Bai, Fei Guo\",\"doi\":\"10.1093/bfgp/elaf003\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><p>Super-enhancers (SEs) are typically located in the regulatory regions of genes, driving high-level gene expression. Identifying SEs is crucial for a deeper understanding of gene regulatory networks, disease mechanisms, and the development and physiological processes of organisms, thus exerting a profound impact on research and applications in the life sciences field. Traditional experimental methods for identifying SEs are costly and time-consuming. Existing methods for predicting SEs based solely on sequence data use deep learning for feature representation and have achieved good results. However, they overlook biological features related to physicochemical properties, leading to low interpretability. Additionally, the complex model structure often requires extensive labeled data for training, which limits their further application in biological data. In this paper, we integrate the strengths of different models and proposes an ensemble model based on an integration strategy to enhance the model's generalization ability. It designs a multi-angle feature representation method that combines local structure and global information to extract high-dimensional abstract relationships and key low-dimensional biological features from sequences. This enhances the effectiveness and interpretability of the model's input features, providing technical support for discovering cell-specific and species-specific patterns of SEs. We evaluated the performance on both mouse and human datasets using five metrics, including area under the receiver operating characteristic curve accuracy, and others. Compared to the latest models, EnsembleSE achieved an average improvement of 4.5% in F1 score and an average improvement of 8.05% in recall, demonstrating the robustness and adaptability of the model on a unified test set. Source codes are available at https://github.com/2103374200/EnsembleSE-main.</p>\",\"PeriodicalId\":55323,\"journal\":{\"name\":\"Briefings in Functional Genomics\",\"volume\":\"24 \",\"pages\":\"\"},\"PeriodicalIF\":2.5000,\"publicationDate\":\"2025-01-15\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12008123/pdf/\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Briefings in Functional Genomics\",\"FirstCategoryId\":\"99\",\"ListUrlMain\":\"https://doi.org/10.1093/bfgp/elaf003\",\"RegionNum\":3,\"RegionCategory\":\"生物学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q3\",\"JCRName\":\"BIOTECHNOLOGY & APPLIED MICROBIOLOGY\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Briefings in Functional Genomics","FirstCategoryId":"99","ListUrlMain":"https://doi.org/10.1093/bfgp/elaf003","RegionNum":3,"RegionCategory":"生物学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q3","JCRName":"BIOTECHNOLOGY & APPLIED MICROBIOLOGY","Score":null,"Total":0}
EnsembleSE: identification of super-enhancers based on ensemble learning.
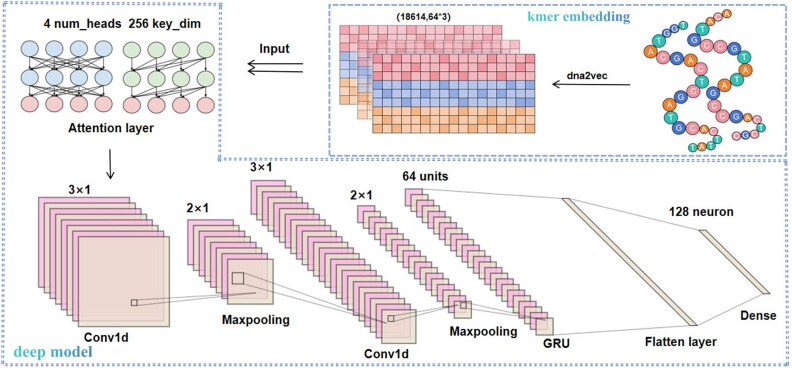
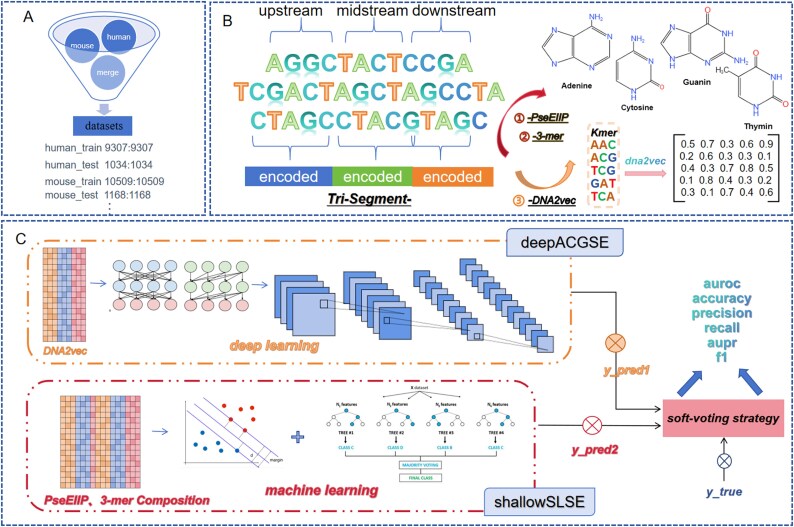
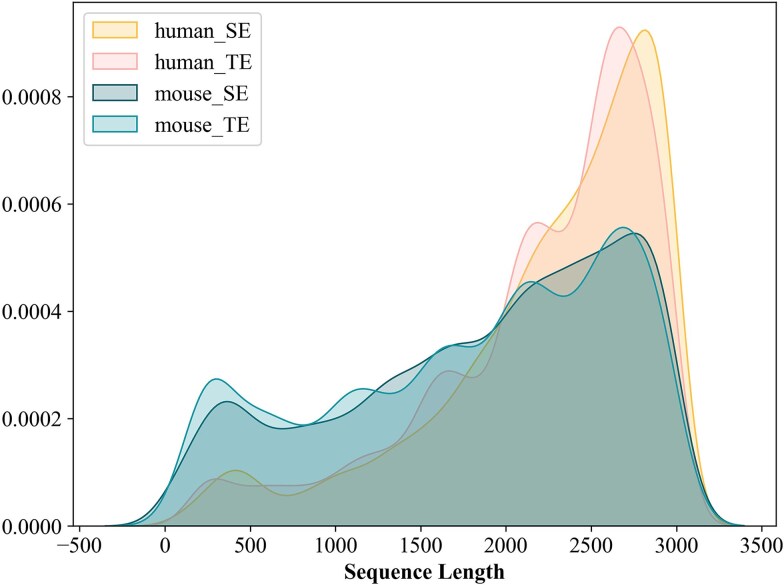
Super-enhancers (SEs) are typically located in the regulatory regions of genes, driving high-level gene expression. Identifying SEs is crucial for a deeper understanding of gene regulatory networks, disease mechanisms, and the development and physiological processes of organisms, thus exerting a profound impact on research and applications in the life sciences field. Traditional experimental methods for identifying SEs are costly and time-consuming. Existing methods for predicting SEs based solely on sequence data use deep learning for feature representation and have achieved good results. However, they overlook biological features related to physicochemical properties, leading to low interpretability. Additionally, the complex model structure often requires extensive labeled data for training, which limits their further application in biological data. In this paper, we integrate the strengths of different models and proposes an ensemble model based on an integration strategy to enhance the model's generalization ability. It designs a multi-angle feature representation method that combines local structure and global information to extract high-dimensional abstract relationships and key low-dimensional biological features from sequences. This enhances the effectiveness and interpretability of the model's input features, providing technical support for discovering cell-specific and species-specific patterns of SEs. We evaluated the performance on both mouse and human datasets using five metrics, including area under the receiver operating characteristic curve accuracy, and others. Compared to the latest models, EnsembleSE achieved an average improvement of 4.5% in F1 score and an average improvement of 8.05% in recall, demonstrating the robustness and adaptability of the model on a unified test set. Source codes are available at https://github.com/2103374200/EnsembleSE-main.
期刊介绍:
Briefings in Functional Genomics publishes high quality peer reviewed articles that focus on the use, development or exploitation of genomic approaches, and their application to all areas of biological research. As well as exploring thematic areas where these techniques and protocols are being used, articles review the impact that these approaches have had, or are likely to have, on their field. Subjects covered by the Journal include but are not restricted to: the identification and functional characterisation of coding and non-coding features in genomes, microarray technologies, gene expression profiling, next generation sequencing, pharmacogenomics, phenomics, SNP technologies, transgenic systems, mutation screens and genotyping. Articles range in scope and depth from the introductory level to specific details of protocols and analyses, encompassing bacterial, fungal, plant, animal and human data.
The editorial board welcome the submission of review articles for publication. Essential criteria for the publication of papers is that they do not contain primary data, and that they are high quality, clearly written review articles which provide a balanced, highly informative and up to date perspective to researchers in the field of functional genomics.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


