Berit Hunsdieck, Christian Bender, Katja Ickstadt, Johanna Mielke
{"title":"大数据中的联合模型:纵向电子健康记录中所需数据质量的基于仿真的指南。","authors":"Berit Hunsdieck, Christian Bender, Katja Ickstadt, Johanna Mielke","doi":"10.1186/s13040-025-00450-z","DOIUrl":null,"url":null,"abstract":"<p><strong>Background: </strong>Over the past decade an increase in usage of electronic health data (EHR) by office-based physicians and hospitals has been reported. However, these data types come with challenge regarding completeness and data quality and it is, especially for more complex models, unclear how these characteristics influence the performance.</p><p><strong>Methods: </strong>In this paper, we focus on joint models which combines longitudinal modelling with survival modelling to incorporate all available information. The aim of this paper is to establish simulation-based guidelines for the necessary quality of longitudinal EHR data so that joint models perform better than cox models. We conducted an extensive simulation study by systematically and transparently varying different characteristics of data quality, e.g., measurement frequency, noise, and heterogeneity between patients. We apply the joint models and evaluate their performance relative to traditional Cox survival modelling techniques.</p><p><strong>Results: </strong>Key findings suggest that biomarker changes before disease onset must be consistent within similar patient groups. With increasing noise and a higher measurement density, the joint model surpasses the traditional Cox regression model in terms of model performance. We illustrate the usefulness and limitations of the guidelines with two real-world examples, namely the influence of serum bilirubin on primary biliary liver cirrhosis and the influence of the estimated glomerular filtration rate on chronic kidney disease.</p>","PeriodicalId":48947,"journal":{"name":"Biodata Mining","volume":"18 1","pages":"35"},"PeriodicalIF":6.1000,"publicationDate":"2025-05-13","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12070788/pdf/","citationCount":"0","resultStr":"{\"title\":\"Joint models in big data: simulation-based guidelines for required data quality in longitudinal electronic health records.\",\"authors\":\"Berit Hunsdieck, Christian Bender, Katja Ickstadt, Johanna Mielke\",\"doi\":\"10.1186/s13040-025-00450-z\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><strong>Background: </strong>Over the past decade an increase in usage of electronic health data (EHR) by office-based physicians and hospitals has been reported. However, these data types come with challenge regarding completeness and data quality and it is, especially for more complex models, unclear how these characteristics influence the performance.</p><p><strong>Methods: </strong>In this paper, we focus on joint models which combines longitudinal modelling with survival modelling to incorporate all available information. The aim of this paper is to establish simulation-based guidelines for the necessary quality of longitudinal EHR data so that joint models perform better than cox models. We conducted an extensive simulation study by systematically and transparently varying different characteristics of data quality, e.g., measurement frequency, noise, and heterogeneity between patients. We apply the joint models and evaluate their performance relative to traditional Cox survival modelling techniques.</p><p><strong>Results: </strong>Key findings suggest that biomarker changes before disease onset must be consistent within similar patient groups. With increasing noise and a higher measurement density, the joint model surpasses the traditional Cox regression model in terms of model performance. We illustrate the usefulness and limitations of the guidelines with two real-world examples, namely the influence of serum bilirubin on primary biliary liver cirrhosis and the influence of the estimated glomerular filtration rate on chronic kidney disease.</p>\",\"PeriodicalId\":48947,\"journal\":{\"name\":\"Biodata Mining\",\"volume\":\"18 1\",\"pages\":\"35\"},\"PeriodicalIF\":6.1000,\"publicationDate\":\"2025-05-13\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12070788/pdf/\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Biodata Mining\",\"FirstCategoryId\":\"99\",\"ListUrlMain\":\"https://doi.org/10.1186/s13040-025-00450-z\",\"RegionNum\":3,\"RegionCategory\":\"生物学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q1\",\"JCRName\":\"MATHEMATICAL & COMPUTATIONAL BIOLOGY\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Biodata Mining","FirstCategoryId":"99","ListUrlMain":"https://doi.org/10.1186/s13040-025-00450-z","RegionNum":3,"RegionCategory":"生物学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"MATHEMATICAL & COMPUTATIONAL BIOLOGY","Score":null,"Total":0}
Joint models in big data: simulation-based guidelines for required data quality in longitudinal electronic health records.
Background: Over the past decade an increase in usage of electronic health data (EHR) by office-based physicians and hospitals has been reported. However, these data types come with challenge regarding completeness and data quality and it is, especially for more complex models, unclear how these characteristics influence the performance.
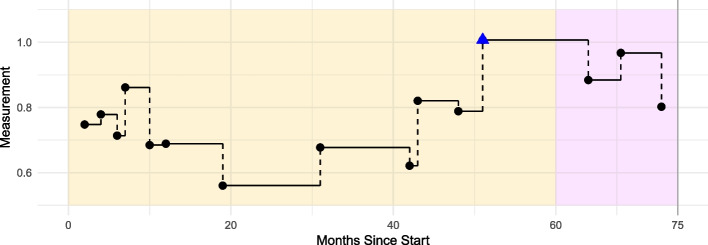
Methods: In this paper, we focus on joint models which combines longitudinal modelling with survival modelling to incorporate all available information. The aim of this paper is to establish simulation-based guidelines for the necessary quality of longitudinal EHR data so that joint models perform better than cox models. We conducted an extensive simulation study by systematically and transparently varying different characteristics of data quality, e.g., measurement frequency, noise, and heterogeneity between patients. We apply the joint models and evaluate their performance relative to traditional Cox survival modelling techniques.
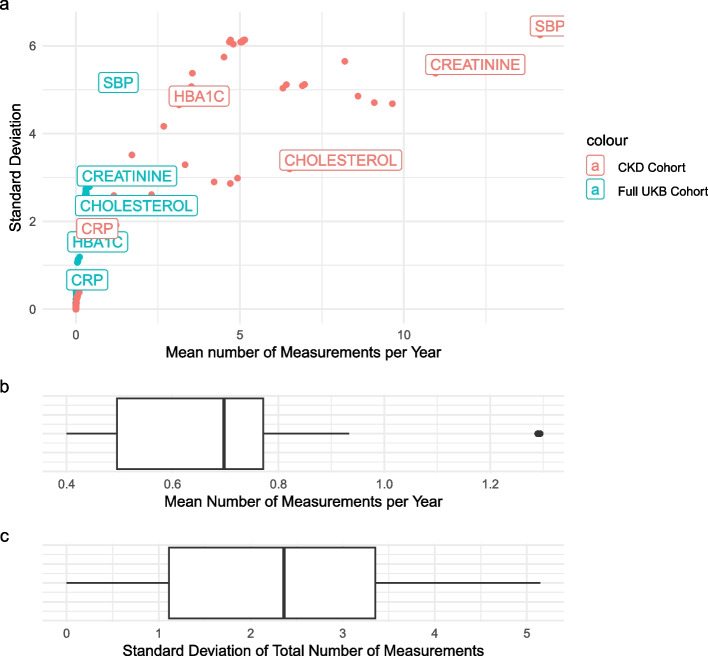
Results: Key findings suggest that biomarker changes before disease onset must be consistent within similar patient groups. With increasing noise and a higher measurement density, the joint model surpasses the traditional Cox regression model in terms of model performance. We illustrate the usefulness and limitations of the guidelines with two real-world examples, namely the influence of serum bilirubin on primary biliary liver cirrhosis and the influence of the estimated glomerular filtration rate on chronic kidney disease.
期刊介绍:
BioData Mining is an open access, open peer-reviewed journal encompassing research on all aspects of data mining applied to high-dimensional biological and biomedical data, focusing on computational aspects of knowledge discovery from large-scale genetic, transcriptomic, genomic, proteomic, and metabolomic data.
Topical areas include, but are not limited to:
-Development, evaluation, and application of novel data mining and machine learning algorithms.
-Adaptation, evaluation, and application of traditional data mining and machine learning algorithms.
-Open-source software for the application of data mining and machine learning algorithms.
-Design, development and integration of databases, software and web services for the storage, management, retrieval, and analysis of data from large scale studies.
-Pre-processing, post-processing, modeling, and interpretation of data mining and machine learning results for biological interpretation and knowledge discovery.


 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


