Davide Panzeri, Thiyaphat Laohawetwanit, Reha Akpinar, Camilla De Carlo, Vincenzo Belsito, Luigi Terracciano, Alessio Aghemo, Nicola Pugliese, Giuseppe Chirico, Donato Inverso, Julien Calderaro, Laura Sironi, Luca Di Tommaso
{"title":"评估ChatGPT-4在MASH肝纤维化组织病理学评估中的诊断准确性。","authors":"Davide Panzeri, Thiyaphat Laohawetwanit, Reha Akpinar, Camilla De Carlo, Vincenzo Belsito, Luigi Terracciano, Alessio Aghemo, Nicola Pugliese, Giuseppe Chirico, Donato Inverso, Julien Calderaro, Laura Sironi, Luca Di Tommaso","doi":"10.1097/HC9.0000000000000695","DOIUrl":null,"url":null,"abstract":"<p><strong>Background: </strong>Large language models like ChatGPT have demonstrated potential in medical image interpretation, but their efficacy in liver histopathological analysis remains largely unexplored. This study aims to assess ChatGPT-4-vision's diagnostic accuracy, compared to liver pathologists' performance, in evaluating liver fibrosis (stage) in metabolic dysfunction-associated steatohepatitis.</p><p><strong>Methods: </strong>Digitized Sirius Red-stained images for 59 metabolic dysfunction-associated steatohepatitis tissue biopsy specimens were evaluated by ChatGPT-4 and 4 pathologists using the NASH-CRN staging system. Fields of view at increasing magnification levels, extracted by a senior pathologist or randomly selected, were shown to ChatGPT-4, asking for fibrosis staging. The diagnostic accuracy of ChatGPT-4 was compared with pathologists' evaluations and correlated to the collagen proportionate area for additional insights. All cases were further analyzed by an in-context learning approach, where the model learns from exemplary images provided during prompting.</p><p><strong>Results: </strong>ChatGPT-4's diagnostic accuracy was 81% when using images selected by a pathologist, while it decreased to 54% with randomly cropped fields of view. By employing an in-context learning approach, the accuracy increased to 88% and 77% for selected and random fields of view, respectively. This method enabled the model to fully and correctly identify the tissue structures characteristic of F4 stages, previously misclassified. The study also highlighted a moderate to strong correlation between ChatGPT-4's fibrosis staging and collagen proportionate area.</p><p><strong>Conclusions: </strong>ChatGPT-4 showed remarkable results with a diagnostic accuracy overlapping those of expert liver pathologists. The in-context learning analysis, applied here for the first time to assess fibrosis deposition in metabolic dysfunction-associated steatohepatitis samples, was crucial in accurately identifying the key features of F4 cases, critical for early therapeutic decision-making. These findings suggest the potential for integrating large language models as supportive tools in diagnostic pathology.</p>","PeriodicalId":12978,"journal":{"name":"Hepatology Communications","volume":"9 5","pages":""},"PeriodicalIF":5.6000,"publicationDate":"2025-04-30","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12045550/pdf/","citationCount":"0","resultStr":"{\"title\":\"Assessing the diagnostic accuracy of ChatGPT-4 in the histopathological evaluation of liver fibrosis in MASH.\",\"authors\":\"Davide Panzeri, Thiyaphat Laohawetwanit, Reha Akpinar, Camilla De Carlo, Vincenzo Belsito, Luigi Terracciano, Alessio Aghemo, Nicola Pugliese, Giuseppe Chirico, Donato Inverso, Julien Calderaro, Laura Sironi, Luca Di Tommaso\",\"doi\":\"10.1097/HC9.0000000000000695\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><strong>Background: </strong>Large language models like ChatGPT have demonstrated potential in medical image interpretation, but their efficacy in liver histopathological analysis remains largely unexplored. This study aims to assess ChatGPT-4-vision's diagnostic accuracy, compared to liver pathologists' performance, in evaluating liver fibrosis (stage) in metabolic dysfunction-associated steatohepatitis.</p><p><strong>Methods: </strong>Digitized Sirius Red-stained images for 59 metabolic dysfunction-associated steatohepatitis tissue biopsy specimens were evaluated by ChatGPT-4 and 4 pathologists using the NASH-CRN staging system. Fields of view at increasing magnification levels, extracted by a senior pathologist or randomly selected, were shown to ChatGPT-4, asking for fibrosis staging. The diagnostic accuracy of ChatGPT-4 was compared with pathologists' evaluations and correlated to the collagen proportionate area for additional insights. All cases were further analyzed by an in-context learning approach, where the model learns from exemplary images provided during prompting.</p><p><strong>Results: </strong>ChatGPT-4's diagnostic accuracy was 81% when using images selected by a pathologist, while it decreased to 54% with randomly cropped fields of view. By employing an in-context learning approach, the accuracy increased to 88% and 77% for selected and random fields of view, respectively. This method enabled the model to fully and correctly identify the tissue structures characteristic of F4 stages, previously misclassified. The study also highlighted a moderate to strong correlation between ChatGPT-4's fibrosis staging and collagen proportionate area.</p><p><strong>Conclusions: </strong>ChatGPT-4 showed remarkable results with a diagnostic accuracy overlapping those of expert liver pathologists. The in-context learning analysis, applied here for the first time to assess fibrosis deposition in metabolic dysfunction-associated steatohepatitis samples, was crucial in accurately identifying the key features of F4 cases, critical for early therapeutic decision-making. These findings suggest the potential for integrating large language models as supportive tools in diagnostic pathology.</p>\",\"PeriodicalId\":12978,\"journal\":{\"name\":\"Hepatology Communications\",\"volume\":\"9 5\",\"pages\":\"\"},\"PeriodicalIF\":5.6000,\"publicationDate\":\"2025-04-30\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12045550/pdf/\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Hepatology Communications\",\"FirstCategoryId\":\"3\",\"ListUrlMain\":\"https://doi.org/10.1097/HC9.0000000000000695\",\"RegionNum\":2,\"RegionCategory\":\"医学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"2025/5/1 0:00:00\",\"PubModel\":\"eCollection\",\"JCR\":\"Q1\",\"JCRName\":\"GASTROENTEROLOGY & HEPATOLOGY\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Hepatology Communications","FirstCategoryId":"3","ListUrlMain":"https://doi.org/10.1097/HC9.0000000000000695","RegionNum":2,"RegionCategory":"医学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2025/5/1 0:00:00","PubModel":"eCollection","JCR":"Q1","JCRName":"GASTROENTEROLOGY & HEPATOLOGY","Score":null,"Total":0}
Assessing the diagnostic accuracy of ChatGPT-4 in the histopathological evaluation of liver fibrosis in MASH.
Background: Large language models like ChatGPT have demonstrated potential in medical image interpretation, but their efficacy in liver histopathological analysis remains largely unexplored. This study aims to assess ChatGPT-4-vision's diagnostic accuracy, compared to liver pathologists' performance, in evaluating liver fibrosis (stage) in metabolic dysfunction-associated steatohepatitis.
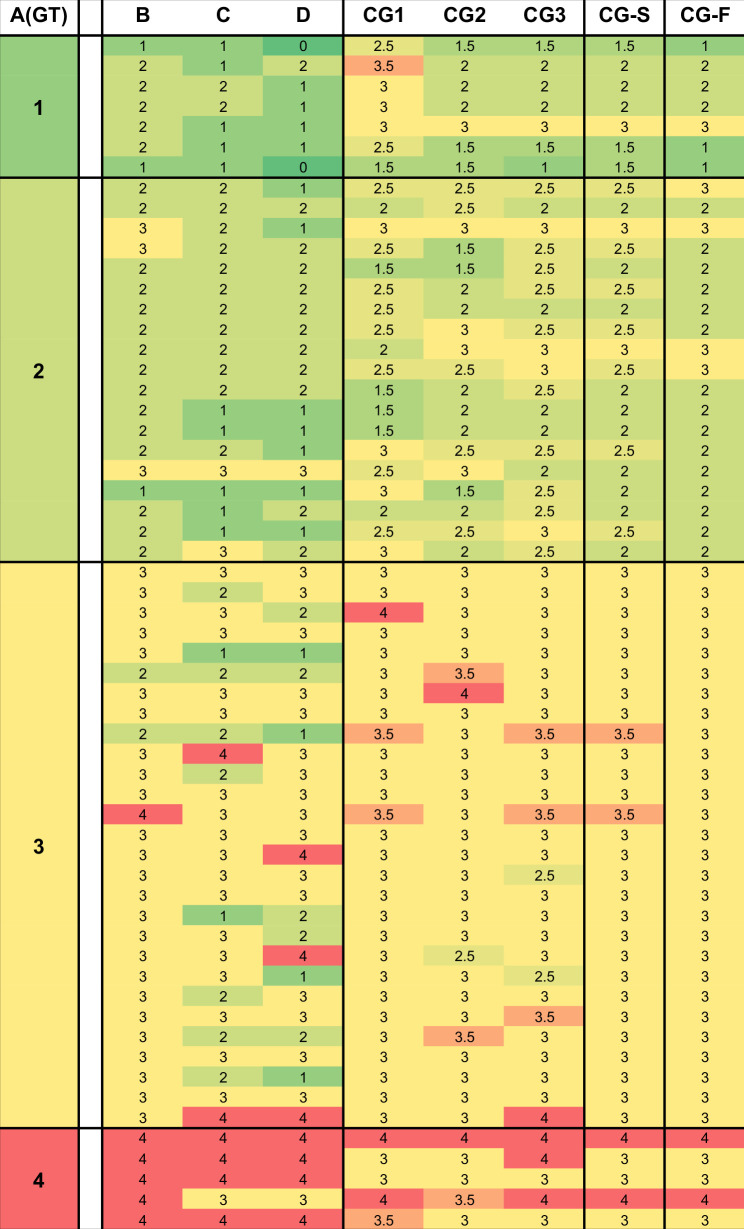
Methods: Digitized Sirius Red-stained images for 59 metabolic dysfunction-associated steatohepatitis tissue biopsy specimens were evaluated by ChatGPT-4 and 4 pathologists using the NASH-CRN staging system. Fields of view at increasing magnification levels, extracted by a senior pathologist or randomly selected, were shown to ChatGPT-4, asking for fibrosis staging. The diagnostic accuracy of ChatGPT-4 was compared with pathologists' evaluations and correlated to the collagen proportionate area for additional insights. All cases were further analyzed by an in-context learning approach, where the model learns from exemplary images provided during prompting.
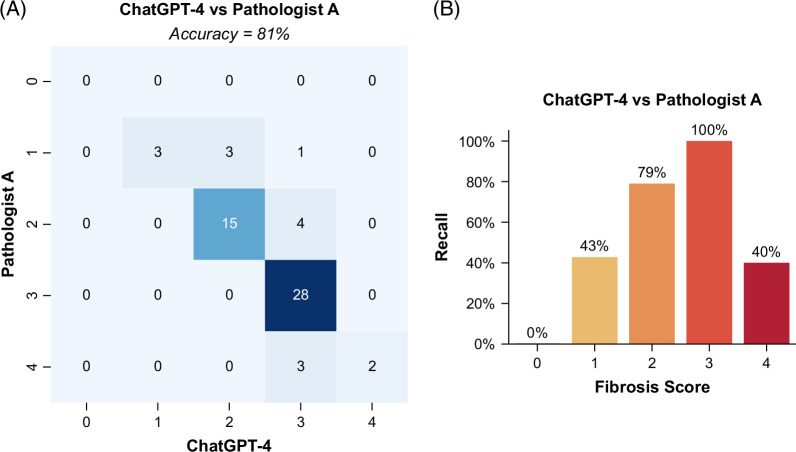
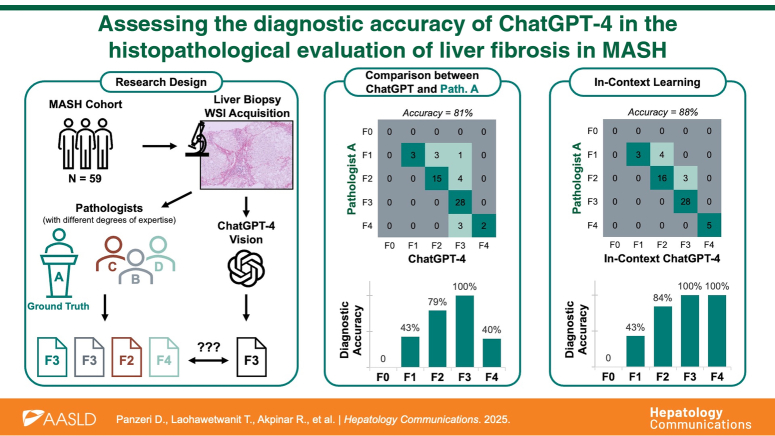
Results: ChatGPT-4's diagnostic accuracy was 81% when using images selected by a pathologist, while it decreased to 54% with randomly cropped fields of view. By employing an in-context learning approach, the accuracy increased to 88% and 77% for selected and random fields of view, respectively. This method enabled the model to fully and correctly identify the tissue structures characteristic of F4 stages, previously misclassified. The study also highlighted a moderate to strong correlation between ChatGPT-4's fibrosis staging and collagen proportionate area.
Conclusions: ChatGPT-4 showed remarkable results with a diagnostic accuracy overlapping those of expert liver pathologists. The in-context learning analysis, applied here for the first time to assess fibrosis deposition in metabolic dysfunction-associated steatohepatitis samples, was crucial in accurately identifying the key features of F4 cases, critical for early therapeutic decision-making. These findings suggest the potential for integrating large language models as supportive tools in diagnostic pathology.
期刊介绍:
Hepatology Communications is a peer-reviewed, online-only, open access journal for fast dissemination of high quality basic, translational, and clinical research in hepatology. Hepatology Communications maintains high standard and rigorous peer review. Because of its open access nature, authors retain the copyright to their works, all articles are immediately available and free to read and share, and it is fully compliant with funder and institutional mandates. The journal is committed to fast publication and author satisfaction.
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


