J Ramón Navarro-Cerdán, Pedro Pons-Suñer, Laura Arnal, Joaquim Arlandis, Rafael Llobet, Juan-Carlos Perez-Cortes, Francisco Lara-Hernández, Celeste Moya-Valera, Maria Elena Quiroz-Rodriguez, Gemma Rojo-Martinez, Sergio Valdés, Eduard Montanya, Alfonso L Calle-Pascual, Josep Franch-Nadal, Elias Delgado, Luis Castaño, Ana-Bárbara García-García, Felipe Javier Chaves
{"title":"使用定制异构特征子集的2型糖尿病诊断和预后的机器学习方法。","authors":"J Ramón Navarro-Cerdán, Pedro Pons-Suñer, Laura Arnal, Joaquim Arlandis, Rafael Llobet, Juan-Carlos Perez-Cortes, Francisco Lara-Hernández, Celeste Moya-Valera, Maria Elena Quiroz-Rodriguez, Gemma Rojo-Martinez, Sergio Valdés, Eduard Montanya, Alfonso L Calle-Pascual, Josep Franch-Nadal, Elias Delgado, Luis Castaño, Ana-Bárbara García-García, Felipe Javier Chaves","doi":"10.1007/s11517-025-03355-5","DOIUrl":null,"url":null,"abstract":"<p><p>Type 2 diabetes (T2D) is becoming one of the leading health problems in Western societies, diminishing quality of life and consuming a significant share of healthcare resources. This study presents machine learning models for T2D diagnosis and prognosis, developed using heterogeneous data from a Spanish population dataset (Di@bet.es study). The models were trained exclusively on individuals classified as controls and undiagnosed diabetics, ensuring that the results are not influenced by treatment effects or behavioral changes due to disease awareness. Two data domains are considered: environmental (patient lifestyle questionnaires and measurements) and clinical (biochemical and anthropometric measurements). The preprocessing pipeline consists of four key steps: geospatial data extraction, feature engineering, missing data imputation, and quasi-constancy filtering. Two working scenarios (Environmental and Healthcare) are defined based on the features used, and applied to two targets (diagnosis and prognosis), resulting in four distinct models. The feature subsets that best predict the target have been identified based on permutation importance and sequential backward selection, reducing the number of features and, consequently, the cost of predictions. In the Environmental scenario, models achieved an AUROC of 0.86 for diagnosis and 0.82 for prognosis. The Healthcare scenario performed better, with an AUROC of 0.96 for diagnosis and 0.88 for prognosis. A partial dependence analysis of the most relevant features is also presented. An online demo page showcasing the Environmental and Healthcare T2D prognosis models is available upon request.</p>","PeriodicalId":49840,"journal":{"name":"Medical & Biological Engineering & Computing","volume":" ","pages":"2733-2752"},"PeriodicalIF":2.6000,"publicationDate":"2025-09-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12402034/pdf/","citationCount":"0","resultStr":"{\"title\":\"A machine learning approach for type 2 diabetes diagnosis and prognosis using tailored heterogeneous feature subsets.\",\"authors\":\"J Ramón Navarro-Cerdán, Pedro Pons-Suñer, Laura Arnal, Joaquim Arlandis, Rafael Llobet, Juan-Carlos Perez-Cortes, Francisco Lara-Hernández, Celeste Moya-Valera, Maria Elena Quiroz-Rodriguez, Gemma Rojo-Martinez, Sergio Valdés, Eduard Montanya, Alfonso L Calle-Pascual, Josep Franch-Nadal, Elias Delgado, Luis Castaño, Ana-Bárbara García-García, Felipe Javier Chaves\",\"doi\":\"10.1007/s11517-025-03355-5\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><p>Type 2 diabetes (T2D) is becoming one of the leading health problems in Western societies, diminishing quality of life and consuming a significant share of healthcare resources. This study presents machine learning models for T2D diagnosis and prognosis, developed using heterogeneous data from a Spanish population dataset (Di@bet.es study). The models were trained exclusively on individuals classified as controls and undiagnosed diabetics, ensuring that the results are not influenced by treatment effects or behavioral changes due to disease awareness. Two data domains are considered: environmental (patient lifestyle questionnaires and measurements) and clinical (biochemical and anthropometric measurements). The preprocessing pipeline consists of four key steps: geospatial data extraction, feature engineering, missing data imputation, and quasi-constancy filtering. Two working scenarios (Environmental and Healthcare) are defined based on the features used, and applied to two targets (diagnosis and prognosis), resulting in four distinct models. The feature subsets that best predict the target have been identified based on permutation importance and sequential backward selection, reducing the number of features and, consequently, the cost of predictions. In the Environmental scenario, models achieved an AUROC of 0.86 for diagnosis and 0.82 for prognosis. The Healthcare scenario performed better, with an AUROC of 0.96 for diagnosis and 0.88 for prognosis. A partial dependence analysis of the most relevant features is also presented. An online demo page showcasing the Environmental and Healthcare T2D prognosis models is available upon request.</p>\",\"PeriodicalId\":49840,\"journal\":{\"name\":\"Medical & Biological Engineering & Computing\",\"volume\":\" \",\"pages\":\"2733-2752\"},\"PeriodicalIF\":2.6000,\"publicationDate\":\"2025-09-01\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12402034/pdf/\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Medical & Biological Engineering & Computing\",\"FirstCategoryId\":\"5\",\"ListUrlMain\":\"https://doi.org/10.1007/s11517-025-03355-5\",\"RegionNum\":4,\"RegionCategory\":\"医学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"2025/4/8 0:00:00\",\"PubModel\":\"Epub\",\"JCR\":\"Q2\",\"JCRName\":\"COMPUTER SCIENCE, INTERDISCIPLINARY APPLICATIONS\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Medical & Biological Engineering & Computing","FirstCategoryId":"5","ListUrlMain":"https://doi.org/10.1007/s11517-025-03355-5","RegionNum":4,"RegionCategory":"医学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2025/4/8 0:00:00","PubModel":"Epub","JCR":"Q2","JCRName":"COMPUTER SCIENCE, INTERDISCIPLINARY APPLICATIONS","Score":null,"Total":0}
A machine learning approach for type 2 diabetes diagnosis and prognosis using tailored heterogeneous feature subsets.
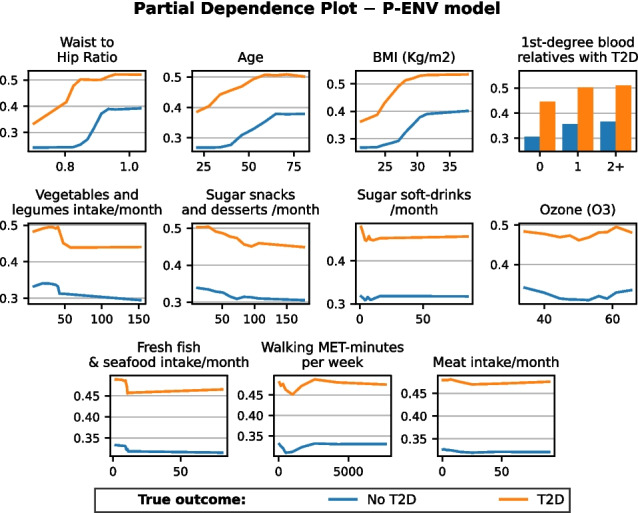
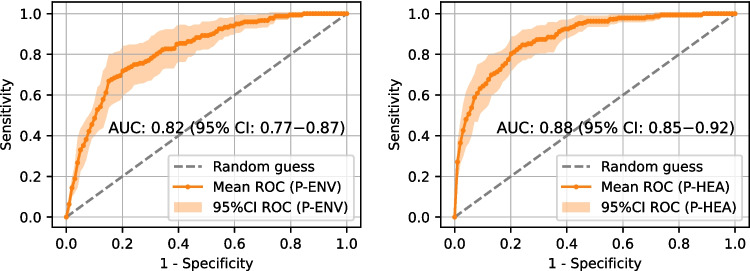
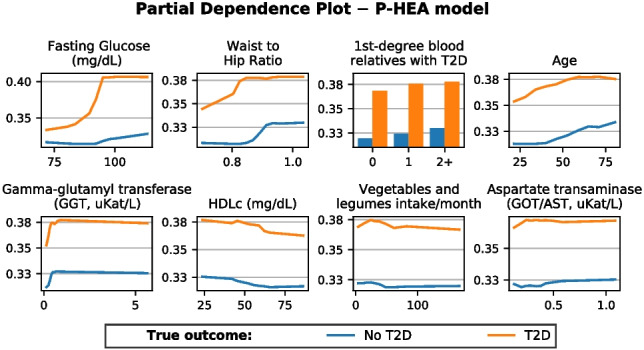
Type 2 diabetes (T2D) is becoming one of the leading health problems in Western societies, diminishing quality of life and consuming a significant share of healthcare resources. This study presents machine learning models for T2D diagnosis and prognosis, developed using heterogeneous data from a Spanish population dataset (Di@bet.es study). The models were trained exclusively on individuals classified as controls and undiagnosed diabetics, ensuring that the results are not influenced by treatment effects or behavioral changes due to disease awareness. Two data domains are considered: environmental (patient lifestyle questionnaires and measurements) and clinical (biochemical and anthropometric measurements). The preprocessing pipeline consists of four key steps: geospatial data extraction, feature engineering, missing data imputation, and quasi-constancy filtering. Two working scenarios (Environmental and Healthcare) are defined based on the features used, and applied to two targets (diagnosis and prognosis), resulting in four distinct models. The feature subsets that best predict the target have been identified based on permutation importance and sequential backward selection, reducing the number of features and, consequently, the cost of predictions. In the Environmental scenario, models achieved an AUROC of 0.86 for diagnosis and 0.82 for prognosis. The Healthcare scenario performed better, with an AUROC of 0.96 for diagnosis and 0.88 for prognosis. A partial dependence analysis of the most relevant features is also presented. An online demo page showcasing the Environmental and Healthcare T2D prognosis models is available upon request.
期刊介绍:
Founded in 1963, Medical & Biological Engineering & Computing (MBEC) continues to serve the biomedical engineering community, covering the entire spectrum of biomedical and clinical engineering. The journal presents exciting and vital experimental and theoretical developments in biomedical science and technology, and reports on advances in computer-based methodologies in these multidisciplinary subjects. The journal also incorporates new and evolving technologies including cellular engineering and molecular imaging.
MBEC publishes original research articles as well as reviews and technical notes. Its Rapid Communications category focuses on material of immediate value to the readership, while the Controversies section provides a forum to exchange views on selected issues, stimulating a vigorous and informed debate in this exciting and high profile field.
MBEC is an official journal of the International Federation of Medical and Biological Engineering (IFMBE).

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


