Darren Liu, Xiao Hu, Canhua Xiao, Jinbing Bai, Zahra A Barandouzi, Stephanie Lee, Caitlin Webster, La-Urshalar Brock, Lindsay Lee, Delgersuren Bold, Yufen Lin
{"title":"评估大型语言模型在为癌症幸存者及其护理人员量身定制教育内容方面的作用:质量分析。","authors":"Darren Liu, Xiao Hu, Canhua Xiao, Jinbing Bai, Zahra A Barandouzi, Stephanie Lee, Caitlin Webster, La-Urshalar Brock, Lindsay Lee, Delgersuren Bold, Yufen Lin","doi":"10.2196/67914","DOIUrl":null,"url":null,"abstract":"<p><strong>Background: </strong>Cancer survivors and their caregivers, particularly those from disadvantaged backgrounds with limited health literacy or racial and ethnic minorities facing language barriers, are at a disproportionately higher risk of experiencing symptom burdens from cancer and its treatments. Large language models (LLMs) offer a promising avenue for generating concise, linguistically appropriate, and accessible educational materials tailored to these populations. However, there is limited research evaluating how effectively LLMs perform in creating targeted content for individuals with diverse literacy and language needs.</p><p><strong>Objective: </strong>This study aimed to evaluate the overall performance of LLMs in generating tailored educational content for cancer survivors and their caregivers with limited health literacy or language barriers, compare the performances of 3 Generative Pretrained Transformer (GPT) models (ie, GPT-3.5 Turbo, GPT-4, and GPT-4 Turbo; OpenAI), and examine how different prompting approaches influence the quality of the generated content.</p><p><strong>Methods: </strong>We selected 30 topics from national guidelines on cancer care and education. GPT-3.5 Turbo, GPT-4, and GPT-4 Turbo were used to generate tailored content of up to 250 words at a 6th-grade reading level, with translations into Spanish and Chinese for each topic. Two distinct prompting approaches (textual and bulleted) were applied and evaluated. Nine oncology experts evaluated 360 generated responses based on predetermined criteria: word limit, reading level, and quality assessment (ie, clarity, accuracy, relevance, completeness, and comprehensibility). ANOVA (analysis of variance) or chi-square analyses were used to compare differences among the various GPT models and prompts.</p><p><strong>Results: </strong>Overall, LLMs showed excellent performance in tailoring educational content, with 74.2% (267/360) adhering to the specified word limit and achieving an average quality assessment score of 8.933 out of 10. However, LLMs showed moderate performance in reading level, with 41.1% (148/360) of content failing to meet the sixth-grade reading level. LLMs demonstrated strong translation capabilities, achieving an accuracy of 96.7% (87/90) for Spanish and 81.1% (73/90) for Chinese translations. Common errors included imprecise scopes, inaccuracies in definitions, and content that lacked actionable recommendations. The more advanced GPT-4 family models showed better overall performance compared to GPT-3.5 Turbo. Prompting GPTs to produce bulleted-format content was likely to result in better educational content compared with textual-format content.</p><p><strong>Conclusions: </strong>All 3 LLMs demonstrated high potential for delivering multilingual, concise, and low health literacy educational content for cancer survivors and caregivers who face limited literacy or language barriers. GPT-4 family models were notably more robust. While further refinement is required to ensure simpler reading levels and fully comprehensive information, these findings highlight LLMs as an emerging tool for bridging gaps in cancer education and advancing health equity. Future research should integrate expert feedback, additional prompt engineering strategies, and specialized training data to optimize content accuracy and accessibility.</p>","PeriodicalId":45538,"journal":{"name":"JMIR Cancer","volume":"11 ","pages":"e67914"},"PeriodicalIF":2.7000,"publicationDate":"2025-04-07","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC11995809/pdf/","citationCount":"0","resultStr":"{\"title\":\"Evaluation of Large Language Models in Tailoring Educational Content for Cancer Survivors and Their Caregivers: Quality Analysis.\",\"authors\":\"Darren Liu, Xiao Hu, Canhua Xiao, Jinbing Bai, Zahra A Barandouzi, Stephanie Lee, Caitlin Webster, La-Urshalar Brock, Lindsay Lee, Delgersuren Bold, Yufen Lin\",\"doi\":\"10.2196/67914\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><strong>Background: </strong>Cancer survivors and their caregivers, particularly those from disadvantaged backgrounds with limited health literacy or racial and ethnic minorities facing language barriers, are at a disproportionately higher risk of experiencing symptom burdens from cancer and its treatments. Large language models (LLMs) offer a promising avenue for generating concise, linguistically appropriate, and accessible educational materials tailored to these populations. However, there is limited research evaluating how effectively LLMs perform in creating targeted content for individuals with diverse literacy and language needs.</p><p><strong>Objective: </strong>This study aimed to evaluate the overall performance of LLMs in generating tailored educational content for cancer survivors and their caregivers with limited health literacy or language barriers, compare the performances of 3 Generative Pretrained Transformer (GPT) models (ie, GPT-3.5 Turbo, GPT-4, and GPT-4 Turbo; OpenAI), and examine how different prompting approaches influence the quality of the generated content.</p><p><strong>Methods: </strong>We selected 30 topics from national guidelines on cancer care and education. GPT-3.5 Turbo, GPT-4, and GPT-4 Turbo were used to generate tailored content of up to 250 words at a 6th-grade reading level, with translations into Spanish and Chinese for each topic. Two distinct prompting approaches (textual and bulleted) were applied and evaluated. Nine oncology experts evaluated 360 generated responses based on predetermined criteria: word limit, reading level, and quality assessment (ie, clarity, accuracy, relevance, completeness, and comprehensibility). ANOVA (analysis of variance) or chi-square analyses were used to compare differences among the various GPT models and prompts.</p><p><strong>Results: </strong>Overall, LLMs showed excellent performance in tailoring educational content, with 74.2% (267/360) adhering to the specified word limit and achieving an average quality assessment score of 8.933 out of 10. However, LLMs showed moderate performance in reading level, with 41.1% (148/360) of content failing to meet the sixth-grade reading level. LLMs demonstrated strong translation capabilities, achieving an accuracy of 96.7% (87/90) for Spanish and 81.1% (73/90) for Chinese translations. Common errors included imprecise scopes, inaccuracies in definitions, and content that lacked actionable recommendations. The more advanced GPT-4 family models showed better overall performance compared to GPT-3.5 Turbo. Prompting GPTs to produce bulleted-format content was likely to result in better educational content compared with textual-format content.</p><p><strong>Conclusions: </strong>All 3 LLMs demonstrated high potential for delivering multilingual, concise, and low health literacy educational content for cancer survivors and caregivers who face limited literacy or language barriers. GPT-4 family models were notably more robust. While further refinement is required to ensure simpler reading levels and fully comprehensive information, these findings highlight LLMs as an emerging tool for bridging gaps in cancer education and advancing health equity. Future research should integrate expert feedback, additional prompt engineering strategies, and specialized training data to optimize content accuracy and accessibility.</p>\",\"PeriodicalId\":45538,\"journal\":{\"name\":\"JMIR Cancer\",\"volume\":\"11 \",\"pages\":\"e67914\"},\"PeriodicalIF\":2.7000,\"publicationDate\":\"2025-04-07\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC11995809/pdf/\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"JMIR Cancer\",\"FirstCategoryId\":\"1085\",\"ListUrlMain\":\"https://doi.org/10.2196/67914\",\"RegionNum\":0,\"RegionCategory\":null,\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q2\",\"JCRName\":\"ONCOLOGY\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"JMIR Cancer","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.2196/67914","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q2","JCRName":"ONCOLOGY","Score":null,"Total":0}
Evaluation of Large Language Models in Tailoring Educational Content for Cancer Survivors and Their Caregivers: Quality Analysis.
Background: Cancer survivors and their caregivers, particularly those from disadvantaged backgrounds with limited health literacy or racial and ethnic minorities facing language barriers, are at a disproportionately higher risk of experiencing symptom burdens from cancer and its treatments. Large language models (LLMs) offer a promising avenue for generating concise, linguistically appropriate, and accessible educational materials tailored to these populations. However, there is limited research evaluating how effectively LLMs perform in creating targeted content for individuals with diverse literacy and language needs.
Objective: This study aimed to evaluate the overall performance of LLMs in generating tailored educational content for cancer survivors and their caregivers with limited health literacy or language barriers, compare the performances of 3 Generative Pretrained Transformer (GPT) models (ie, GPT-3.5 Turbo, GPT-4, and GPT-4 Turbo; OpenAI), and examine how different prompting approaches influence the quality of the generated content.
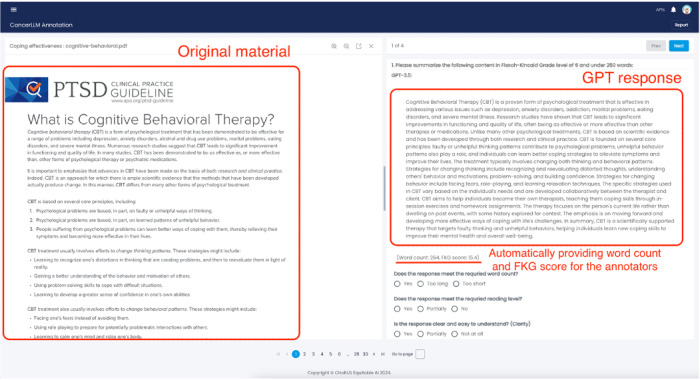
Methods: We selected 30 topics from national guidelines on cancer care and education. GPT-3.5 Turbo, GPT-4, and GPT-4 Turbo were used to generate tailored content of up to 250 words at a 6th-grade reading level, with translations into Spanish and Chinese for each topic. Two distinct prompting approaches (textual and bulleted) were applied and evaluated. Nine oncology experts evaluated 360 generated responses based on predetermined criteria: word limit, reading level, and quality assessment (ie, clarity, accuracy, relevance, completeness, and comprehensibility). ANOVA (analysis of variance) or chi-square analyses were used to compare differences among the various GPT models and prompts.
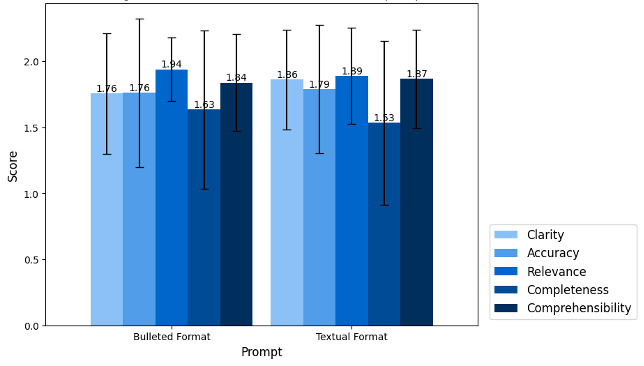
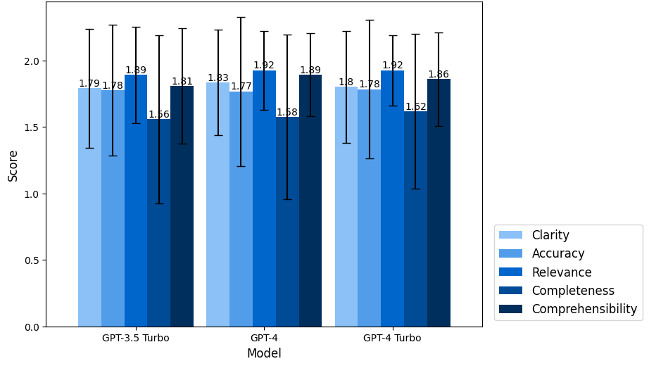
Results: Overall, LLMs showed excellent performance in tailoring educational content, with 74.2% (267/360) adhering to the specified word limit and achieving an average quality assessment score of 8.933 out of 10. However, LLMs showed moderate performance in reading level, with 41.1% (148/360) of content failing to meet the sixth-grade reading level. LLMs demonstrated strong translation capabilities, achieving an accuracy of 96.7% (87/90) for Spanish and 81.1% (73/90) for Chinese translations. Common errors included imprecise scopes, inaccuracies in definitions, and content that lacked actionable recommendations. The more advanced GPT-4 family models showed better overall performance compared to GPT-3.5 Turbo. Prompting GPTs to produce bulleted-format content was likely to result in better educational content compared with textual-format content.
Conclusions: All 3 LLMs demonstrated high potential for delivering multilingual, concise, and low health literacy educational content for cancer survivors and caregivers who face limited literacy or language barriers. GPT-4 family models were notably more robust. While further refinement is required to ensure simpler reading levels and fully comprehensive information, these findings highlight LLMs as an emerging tool for bridging gaps in cancer education and advancing health equity. Future research should integrate expert feedback, additional prompt engineering strategies, and specialized training data to optimize content accuracy and accessibility.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


