{"title":"AI聊天机器人作为STD信息的来源:可靠性和可读性研究。","authors":"Hüseyin Alperen Yıldız, Emrullah Söğütdelen","doi":"10.1007/s10916-025-02178-z","DOIUrl":null,"url":null,"abstract":"<p><strong>Background: </strong>Artificial intelligence (AI) chatbots are increasingly used for medical inquiries, including sensitive topics like sexually transmitted diseases (STDs). However, concerns remain regarding the reliability and readability of the information they provide. This study aimed to assess the reliability and readability of AI chatbots in providing information on STDs. The key objectives were to determine (1) the reliability of STD-related information provided by AI chatbots, and (2) whether the readability of this information meets the recommended standarts for patient education materials.</p><p><strong>Methods: </strong>Eleven relevant STD-related search queries were identified using Google Trends and entered into four AI chatbots: ChatGPT, Gemini, Perplexity, and Copilot. The reliability of the responses was evaluated using established tools, including DISCERN, EQIP, JAMA, and GQS. Readability was assessed using six widely recognized metrics, such as the Flesch-Kincaid Grade Level and the Gunning Fog Index. The performance of chatbots was statistically compared in terms of reliability and readability.</p><p><strong>Results: </strong>The analysis revealed significant differences in reliability across the AI chatbots. Perplexity and Copilot consistently outperformed ChatGPT and Gemini in DISCERN and EQIP scores, suggesting that these two chatbots provided more reliable information. However, results showed that none of the chatbots achieved the 6th-grade readability standard. All the chatbots generated information that was too complex for the general public, especially for individuals with lower health literacy levels.</p><p><strong>Conclusion: </strong>While Perplexity and Copilot showed better reliability in providing STD-related information, none of the chatbots met the recommended readability benchmarks. These findings highlight the need for future improvements in both the accuracy and accessibility of AI-generated health information, ensuring it can be easily understood by a broader audience.</p>","PeriodicalId":16338,"journal":{"name":"Journal of Medical Systems","volume":"49 1","pages":"43"},"PeriodicalIF":5.7000,"publicationDate":"2025-04-03","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC11968469/pdf/","citationCount":"0","resultStr":"{\"title\":\"AI Chatbots as Sources of STD Information: A Study on Reliability and Readability.\",\"authors\":\"Hüseyin Alperen Yıldız, Emrullah Söğütdelen\",\"doi\":\"10.1007/s10916-025-02178-z\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><strong>Background: </strong>Artificial intelligence (AI) chatbots are increasingly used for medical inquiries, including sensitive topics like sexually transmitted diseases (STDs). However, concerns remain regarding the reliability and readability of the information they provide. This study aimed to assess the reliability and readability of AI chatbots in providing information on STDs. The key objectives were to determine (1) the reliability of STD-related information provided by AI chatbots, and (2) whether the readability of this information meets the recommended standarts for patient education materials.</p><p><strong>Methods: </strong>Eleven relevant STD-related search queries were identified using Google Trends and entered into four AI chatbots: ChatGPT, Gemini, Perplexity, and Copilot. The reliability of the responses was evaluated using established tools, including DISCERN, EQIP, JAMA, and GQS. Readability was assessed using six widely recognized metrics, such as the Flesch-Kincaid Grade Level and the Gunning Fog Index. The performance of chatbots was statistically compared in terms of reliability and readability.</p><p><strong>Results: </strong>The analysis revealed significant differences in reliability across the AI chatbots. Perplexity and Copilot consistently outperformed ChatGPT and Gemini in DISCERN and EQIP scores, suggesting that these two chatbots provided more reliable information. However, results showed that none of the chatbots achieved the 6th-grade readability standard. All the chatbots generated information that was too complex for the general public, especially for individuals with lower health literacy levels.</p><p><strong>Conclusion: </strong>While Perplexity and Copilot showed better reliability in providing STD-related information, none of the chatbots met the recommended readability benchmarks. These findings highlight the need for future improvements in both the accuracy and accessibility of AI-generated health information, ensuring it can be easily understood by a broader audience.</p>\",\"PeriodicalId\":16338,\"journal\":{\"name\":\"Journal of Medical Systems\",\"volume\":\"49 1\",\"pages\":\"43\"},\"PeriodicalIF\":5.7000,\"publicationDate\":\"2025-04-03\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC11968469/pdf/\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Journal of Medical Systems\",\"FirstCategoryId\":\"3\",\"ListUrlMain\":\"https://doi.org/10.1007/s10916-025-02178-z\",\"RegionNum\":3,\"RegionCategory\":\"医学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q1\",\"JCRName\":\"HEALTH CARE SCIENCES & SERVICES\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Journal of Medical Systems","FirstCategoryId":"3","ListUrlMain":"https://doi.org/10.1007/s10916-025-02178-z","RegionNum":3,"RegionCategory":"医学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"HEALTH CARE SCIENCES & SERVICES","Score":null,"Total":0}
AI Chatbots as Sources of STD Information: A Study on Reliability and Readability.
Background: Artificial intelligence (AI) chatbots are increasingly used for medical inquiries, including sensitive topics like sexually transmitted diseases (STDs). However, concerns remain regarding the reliability and readability of the information they provide. This study aimed to assess the reliability and readability of AI chatbots in providing information on STDs. The key objectives were to determine (1) the reliability of STD-related information provided by AI chatbots, and (2) whether the readability of this information meets the recommended standarts for patient education materials.
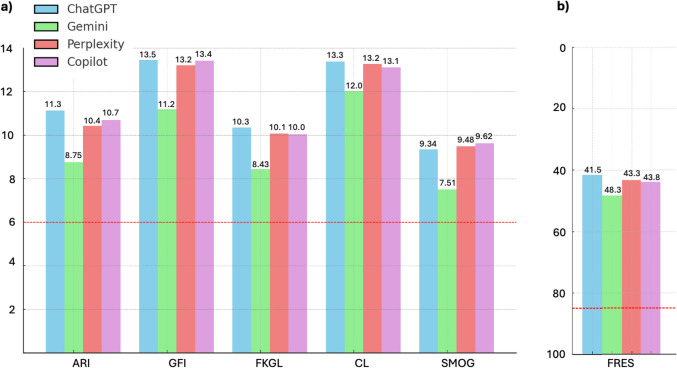
Methods: Eleven relevant STD-related search queries were identified using Google Trends and entered into four AI chatbots: ChatGPT, Gemini, Perplexity, and Copilot. The reliability of the responses was evaluated using established tools, including DISCERN, EQIP, JAMA, and GQS. Readability was assessed using six widely recognized metrics, such as the Flesch-Kincaid Grade Level and the Gunning Fog Index. The performance of chatbots was statistically compared in terms of reliability and readability.
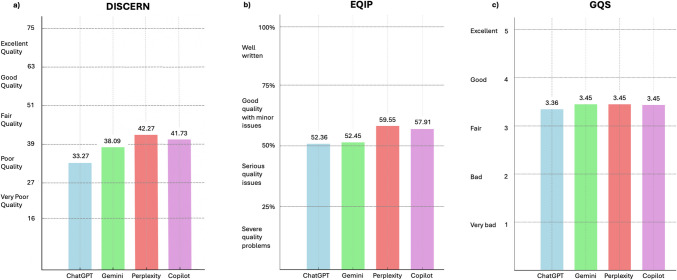
Results: The analysis revealed significant differences in reliability across the AI chatbots. Perplexity and Copilot consistently outperformed ChatGPT and Gemini in DISCERN and EQIP scores, suggesting that these two chatbots provided more reliable information. However, results showed that none of the chatbots achieved the 6th-grade readability standard. All the chatbots generated information that was too complex for the general public, especially for individuals with lower health literacy levels.
Conclusion: While Perplexity and Copilot showed better reliability in providing STD-related information, none of the chatbots met the recommended readability benchmarks. These findings highlight the need for future improvements in both the accuracy and accessibility of AI-generated health information, ensuring it can be easily understood by a broader audience.
期刊介绍:
Journal of Medical Systems provides a forum for the presentation and discussion of the increasingly extensive applications of new systems techniques and methods in hospital clinic and physician''s office administration; pathology radiology and pharmaceutical delivery systems; medical records storage and retrieval; and ancillary patient-support systems. The journal publishes informative articles essays and studies across the entire scale of medical systems from large hospital programs to novel small-scale medical services. Education is an integral part of this amalgamation of sciences and selected articles are published in this area. Since existing medical systems are constantly being modified to fit particular circumstances and to solve specific problems the journal includes a special section devoted to status reports on current installations.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


