Yu Hou, Jay Patel, Liya Dai, Emily Zhang, Yang Liu, Zaifu Zhan, Pooja Gangwani, Rui Zhang
{"title":"牙科入学考试大型语言模型的基准测试。","authors":"Yu Hou, Jay Patel, Liya Dai, Emily Zhang, Yang Liu, Zaifu Zhan, Pooja Gangwani, Rui Zhang","doi":"10.34133/hds.0250","DOIUrl":null,"url":null,"abstract":"<p><p><b>Background:</b> Large language models (LLMs) have shown promise in educational applications, but their performance on high-stakes admissions tests, such as the Dental Admission Test (DAT), remains unclear. Understanding the capabilities and limitations of these models is critical for determining their suitability in test preparation. <b>Methods:</b> This study evaluated the ability of 16 LLMs, including general-purpose models (e.g., GPT-3.5, GPT-4, GPT-4o, GPT-o1, Google's Bard, mistral-large, and Claude), domain-specific fine-tuned models (e.g., DentalGPT, MedGPT, and BioGPT), and open-source models (e.g., Llama2-7B, Llama2-13B, Llama2-70B, Llama3-8B, and Llama3-70B), to answer questions from a sample DAT. Quantitative analysis was performed to assess model accuracy in different sections, and qualitative thematic analysis by subject matter experts examined specific challenges encountered by the models. <b>Results:</b> GPT-4o and GPT-o1 outperformed others in text-based questions assessing knowledge and comprehension, with GPT-o1 achieving perfect scores in the natural sciences (NS) and reading comprehension (RC) sections. Open-source models such as Llama3-70B also performed competitively in RC tasks. However, all models, including GPT-4o, struggled substantially with perceptual ability (PA) items, highlighting a persistent limitation in handling image-based tasks requiring visual-spatial reasoning. Fine-tuned medical models (e.g., DentalGPT, MedGPT, and BioGPT) demonstrated moderate success in text-based tasks but underperformed in areas requiring critical thinking and reasoning. Thematic analysis identified key challenges, including difficulties with stepwise problem-solving, transferring knowledge, comprehending intricate questions, and hallucinations, particularly on advanced items. <b>Conclusions:</b> While LLMs show potential for reinforcing factual knowledge and supporting learners, their limitations in handling higher-order cognitive tasks and image-based reasoning underscore the need for judicious integration with instructor-led guidance and targeted practice. This study provides valuable insights into the capabilities and limitations of current LLMs in preparing prospective dental students and highlights pathways for future innovations to improve performance across all cognitive skills assessed by the DAT.</p>","PeriodicalId":73207,"journal":{"name":"Health data science","volume":"5 ","pages":"0250"},"PeriodicalIF":0.0000,"publicationDate":"2025-04-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC11961047/pdf/","citationCount":"0","resultStr":"{\"title\":\"Benchmarking of Large Language Models for the Dental Admission Test.\",\"authors\":\"Yu Hou, Jay Patel, Liya Dai, Emily Zhang, Yang Liu, Zaifu Zhan, Pooja Gangwani, Rui Zhang\",\"doi\":\"10.34133/hds.0250\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><p><b>Background:</b> Large language models (LLMs) have shown promise in educational applications, but their performance on high-stakes admissions tests, such as the Dental Admission Test (DAT), remains unclear. Understanding the capabilities and limitations of these models is critical for determining their suitability in test preparation. <b>Methods:</b> This study evaluated the ability of 16 LLMs, including general-purpose models (e.g., GPT-3.5, GPT-4, GPT-4o, GPT-o1, Google's Bard, mistral-large, and Claude), domain-specific fine-tuned models (e.g., DentalGPT, MedGPT, and BioGPT), and open-source models (e.g., Llama2-7B, Llama2-13B, Llama2-70B, Llama3-8B, and Llama3-70B), to answer questions from a sample DAT. Quantitative analysis was performed to assess model accuracy in different sections, and qualitative thematic analysis by subject matter experts examined specific challenges encountered by the models. <b>Results:</b> GPT-4o and GPT-o1 outperformed others in text-based questions assessing knowledge and comprehension, with GPT-o1 achieving perfect scores in the natural sciences (NS) and reading comprehension (RC) sections. Open-source models such as Llama3-70B also performed competitively in RC tasks. However, all models, including GPT-4o, struggled substantially with perceptual ability (PA) items, highlighting a persistent limitation in handling image-based tasks requiring visual-spatial reasoning. Fine-tuned medical models (e.g., DentalGPT, MedGPT, and BioGPT) demonstrated moderate success in text-based tasks but underperformed in areas requiring critical thinking and reasoning. Thematic analysis identified key challenges, including difficulties with stepwise problem-solving, transferring knowledge, comprehending intricate questions, and hallucinations, particularly on advanced items. <b>Conclusions:</b> While LLMs show potential for reinforcing factual knowledge and supporting learners, their limitations in handling higher-order cognitive tasks and image-based reasoning underscore the need for judicious integration with instructor-led guidance and targeted practice. This study provides valuable insights into the capabilities and limitations of current LLMs in preparing prospective dental students and highlights pathways for future innovations to improve performance across all cognitive skills assessed by the DAT.</p>\",\"PeriodicalId\":73207,\"journal\":{\"name\":\"Health data science\",\"volume\":\"5 \",\"pages\":\"0250\"},\"PeriodicalIF\":0.0000,\"publicationDate\":\"2025-04-01\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC11961047/pdf/\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Health data science\",\"FirstCategoryId\":\"1085\",\"ListUrlMain\":\"https://doi.org/10.34133/hds.0250\",\"RegionNum\":0,\"RegionCategory\":null,\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"2025/1/1 0:00:00\",\"PubModel\":\"eCollection\",\"JCR\":\"\",\"JCRName\":\"\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Health data science","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.34133/hds.0250","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2025/1/1 0:00:00","PubModel":"eCollection","JCR":"","JCRName":"","Score":null,"Total":0}
Benchmarking of Large Language Models for the Dental Admission Test.
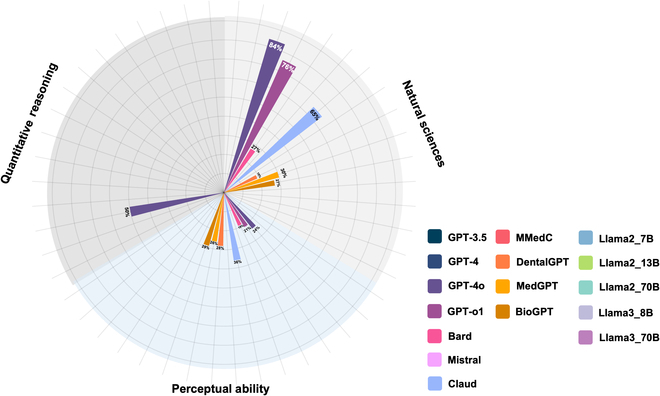
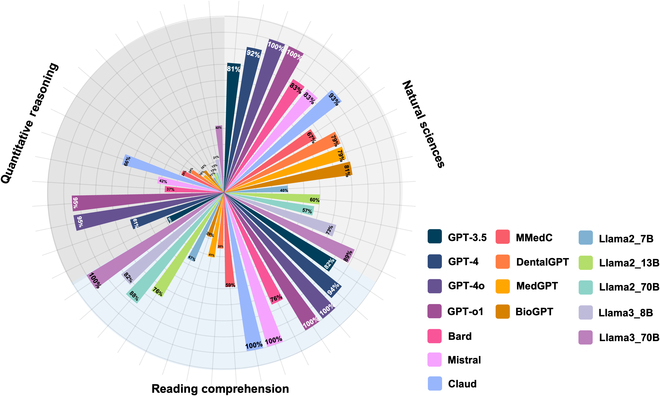
Background: Large language models (LLMs) have shown promise in educational applications, but their performance on high-stakes admissions tests, such as the Dental Admission Test (DAT), remains unclear. Understanding the capabilities and limitations of these models is critical for determining their suitability in test preparation. Methods: This study evaluated the ability of 16 LLMs, including general-purpose models (e.g., GPT-3.5, GPT-4, GPT-4o, GPT-o1, Google's Bard, mistral-large, and Claude), domain-specific fine-tuned models (e.g., DentalGPT, MedGPT, and BioGPT), and open-source models (e.g., Llama2-7B, Llama2-13B, Llama2-70B, Llama3-8B, and Llama3-70B), to answer questions from a sample DAT. Quantitative analysis was performed to assess model accuracy in different sections, and qualitative thematic analysis by subject matter experts examined specific challenges encountered by the models. Results: GPT-4o and GPT-o1 outperformed others in text-based questions assessing knowledge and comprehension, with GPT-o1 achieving perfect scores in the natural sciences (NS) and reading comprehension (RC) sections. Open-source models such as Llama3-70B also performed competitively in RC tasks. However, all models, including GPT-4o, struggled substantially with perceptual ability (PA) items, highlighting a persistent limitation in handling image-based tasks requiring visual-spatial reasoning. Fine-tuned medical models (e.g., DentalGPT, MedGPT, and BioGPT) demonstrated moderate success in text-based tasks but underperformed in areas requiring critical thinking and reasoning. Thematic analysis identified key challenges, including difficulties with stepwise problem-solving, transferring knowledge, comprehending intricate questions, and hallucinations, particularly on advanced items. Conclusions: While LLMs show potential for reinforcing factual knowledge and supporting learners, their limitations in handling higher-order cognitive tasks and image-based reasoning underscore the need for judicious integration with instructor-led guidance and targeted practice. This study provides valuable insights into the capabilities and limitations of current LLMs in preparing prospective dental students and highlights pathways for future innovations to improve performance across all cognitive skills assessed by the DAT.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


