David Chen, Saif Addeen Alnassar, Kate Elizabeth Avison, Ryan S Huang, Srinivas Raman
{"title":"大语言模型在肿瘤学健康信息提取中的应用:范围综述。","authors":"David Chen, Saif Addeen Alnassar, Kate Elizabeth Avison, Ryan S Huang, Srinivas Raman","doi":"10.2196/65984","DOIUrl":null,"url":null,"abstract":"<p><strong>Background: </strong>Natural language processing systems for data extraction from unstructured clinical text require expert-driven input for labeled annotations and model training. The natural language processing competency of large language models (LLM) can enable automated data extraction of important patient characteristics from electronic health records, which is useful for accelerating cancer clinical research and informing oncology care.</p><p><strong>Objective: </strong>This scoping review aims to map the current landscape, including definitions, frameworks, and future directions of LLMs applied to data extraction from clinical text in oncology.</p><p><strong>Methods: </strong>We queried Ovid MEDLINE for primary, peer-reviewed research studies published since 2000 on June 2, 2024, using oncology- and LLM-related keywords. This scoping review included studies that evaluated the performance of an LLM applied to data extraction from clinical text in oncology contexts. Study attributes and main outcomes were extracted to outline key trends of research in LLM-based data extraction.</p><p><strong>Results: </strong>The literature search yielded 24 studies for inclusion. The majority of studies assessed original and fine-tuned variants of the BERT LLM (n=18, 75%) followed by the Chat-GPT conversational LLM (n=6, 25%). LLMs for data extraction were commonly applied in pan-cancer clinical settings (n=11, 46%), followed by breast (n=4, 17%), and lung (n=4, 17%) cancer contexts, and were evaluated using multi-institution datasets (n=18, 75%). Comparing the studies published in 2022-2024 versus 2019-2021, both the total number of studies (18 vs 6) and the proportion of studies using prompt engineering increased (5/18, 28% vs 0/6, 0%), while the proportion using fine-tuning decreased (8/18, 44.4% vs 6/6, 100%). Advantages of LLMs included positive data extraction performance and reduced manual workload.</p><p><strong>Conclusions: </strong>LLMs applied to data extraction in oncology can serve as useful automated tools to reduce the administrative burden of reviewing patient health records and increase time for patient-facing care. Recent advances in prompt-engineering and fine-tuning methods, and multimodal data extraction present promising directions for future research. Further studies are needed to evaluate the performance of LLM-enabled data extraction in clinical domains beyond the training dataset and to assess the scope and integration of LLMs into real-world clinical environments.</p>","PeriodicalId":45538,"journal":{"name":"JMIR Cancer","volume":"11 ","pages":"e65984"},"PeriodicalIF":2.7000,"publicationDate":"2025-03-28","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC11970800/pdf/","citationCount":"0","resultStr":"{\"title\":\"Large Language Model Applications for Health Information Extraction in Oncology: Scoping Review.\",\"authors\":\"David Chen, Saif Addeen Alnassar, Kate Elizabeth Avison, Ryan S Huang, Srinivas Raman\",\"doi\":\"10.2196/65984\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><strong>Background: </strong>Natural language processing systems for data extraction from unstructured clinical text require expert-driven input for labeled annotations and model training. The natural language processing competency of large language models (LLM) can enable automated data extraction of important patient characteristics from electronic health records, which is useful for accelerating cancer clinical research and informing oncology care.</p><p><strong>Objective: </strong>This scoping review aims to map the current landscape, including definitions, frameworks, and future directions of LLMs applied to data extraction from clinical text in oncology.</p><p><strong>Methods: </strong>We queried Ovid MEDLINE for primary, peer-reviewed research studies published since 2000 on June 2, 2024, using oncology- and LLM-related keywords. This scoping review included studies that evaluated the performance of an LLM applied to data extraction from clinical text in oncology contexts. Study attributes and main outcomes were extracted to outline key trends of research in LLM-based data extraction.</p><p><strong>Results: </strong>The literature search yielded 24 studies for inclusion. The majority of studies assessed original and fine-tuned variants of the BERT LLM (n=18, 75%) followed by the Chat-GPT conversational LLM (n=6, 25%). LLMs for data extraction were commonly applied in pan-cancer clinical settings (n=11, 46%), followed by breast (n=4, 17%), and lung (n=4, 17%) cancer contexts, and were evaluated using multi-institution datasets (n=18, 75%). Comparing the studies published in 2022-2024 versus 2019-2021, both the total number of studies (18 vs 6) and the proportion of studies using prompt engineering increased (5/18, 28% vs 0/6, 0%), while the proportion using fine-tuning decreased (8/18, 44.4% vs 6/6, 100%). Advantages of LLMs included positive data extraction performance and reduced manual workload.</p><p><strong>Conclusions: </strong>LLMs applied to data extraction in oncology can serve as useful automated tools to reduce the administrative burden of reviewing patient health records and increase time for patient-facing care. Recent advances in prompt-engineering and fine-tuning methods, and multimodal data extraction present promising directions for future research. Further studies are needed to evaluate the performance of LLM-enabled data extraction in clinical domains beyond the training dataset and to assess the scope and integration of LLMs into real-world clinical environments.</p>\",\"PeriodicalId\":45538,\"journal\":{\"name\":\"JMIR Cancer\",\"volume\":\"11 \",\"pages\":\"e65984\"},\"PeriodicalIF\":2.7000,\"publicationDate\":\"2025-03-28\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC11970800/pdf/\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"JMIR Cancer\",\"FirstCategoryId\":\"1085\",\"ListUrlMain\":\"https://doi.org/10.2196/65984\",\"RegionNum\":0,\"RegionCategory\":null,\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q2\",\"JCRName\":\"ONCOLOGY\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"JMIR Cancer","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.2196/65984","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q2","JCRName":"ONCOLOGY","Score":null,"Total":0}
引用次数: 0
摘要
背景:用于从非结构化临床文本中提取数据的自然语言处理系统需要专家驱动的输入来进行标记注释和模型训练。大型语言模型(LLM)的自然语言处理能力可以实现从电子健康记录中自动提取重要患者特征的数据,这对于加速癌症临床研究和告知肿瘤护理非常有用。目的:这一范围综述旨在绘制当前的景观,包括法学硕士应用于肿瘤临床文本数据提取的定义、框架和未来方向。方法:我们于2024年6月2日在Ovid MEDLINE检索自2000年以来发表的主要的、同行评审的研究,使用肿瘤学和法学硕士相关的关键词。该范围综述包括评估法学硕士应用于肿瘤学临床文本数据提取的性能的研究。提取了研究属性和主要结果,概述了基于法学硕士的数据提取研究的关键趋势。结果:文献检索共纳入24篇研究。大多数研究评估了BERT LLM的原始和微调变体(n= 18.75%),然后是Chat-GPT会话LLM (n= 6,25%)。llm用于数据提取通常应用于泛癌症临床环境(n= 11,46%),其次是乳腺癌(n= 4,17%)和肺癌(n= 4,17%),并使用多机构数据集进行评估(n= 18,75%)。与2019-2021年发表的研究相比,2022-2024年发表的研究总数(18篇vs 6篇)和使用即时工程的研究比例均有所增加(5/18,28% vs 0/6, 0%),而使用微调的研究比例有所下降(8/18,44.4% vs 6/6, 100%)。llm的优点包括积极的数据提取性能和减少人工工作量。结论:llm应用于肿瘤学数据提取可以作为有用的自动化工具,减少审查患者健康记录的行政负担,增加面向患者的护理时间。即时工程和微调方法以及多模态数据提取的最新进展为未来的研究提供了有希望的方向。需要进一步的研究来评估法学硕士在训练数据集之外的临床领域的数据提取性能,并评估法学硕士在现实临床环境中的范围和集成。
Large Language Model Applications for Health Information Extraction in Oncology: Scoping Review.
Background: Natural language processing systems for data extraction from unstructured clinical text require expert-driven input for labeled annotations and model training. The natural language processing competency of large language models (LLM) can enable automated data extraction of important patient characteristics from electronic health records, which is useful for accelerating cancer clinical research and informing oncology care.
Objective: This scoping review aims to map the current landscape, including definitions, frameworks, and future directions of LLMs applied to data extraction from clinical text in oncology.
Methods: We queried Ovid MEDLINE for primary, peer-reviewed research studies published since 2000 on June 2, 2024, using oncology- and LLM-related keywords. This scoping review included studies that evaluated the performance of an LLM applied to data extraction from clinical text in oncology contexts. Study attributes and main outcomes were extracted to outline key trends of research in LLM-based data extraction.
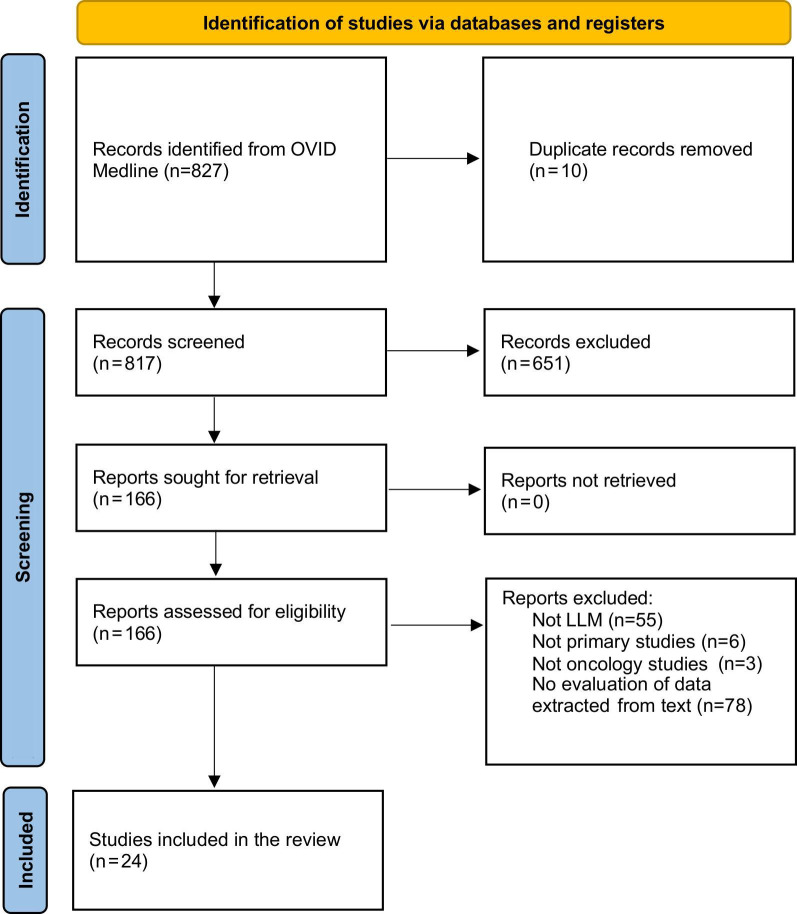
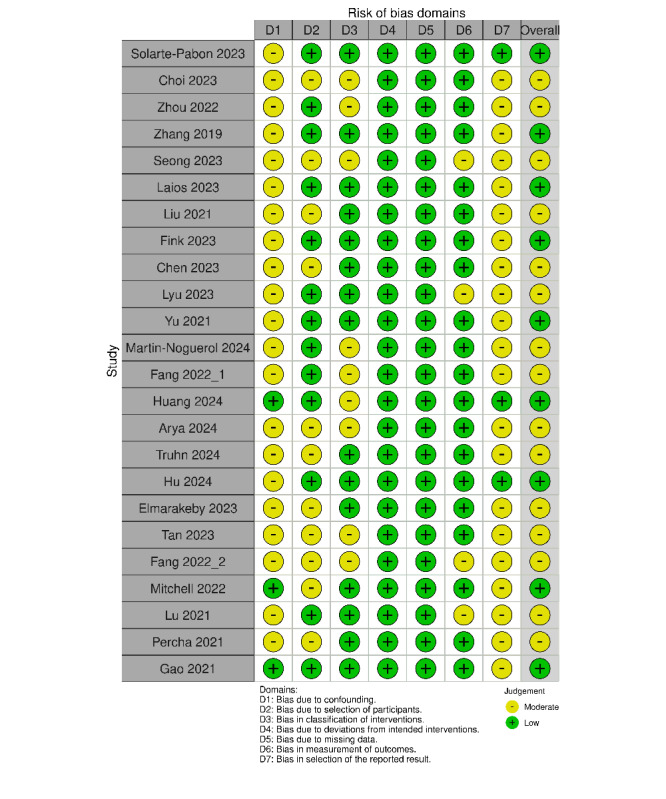
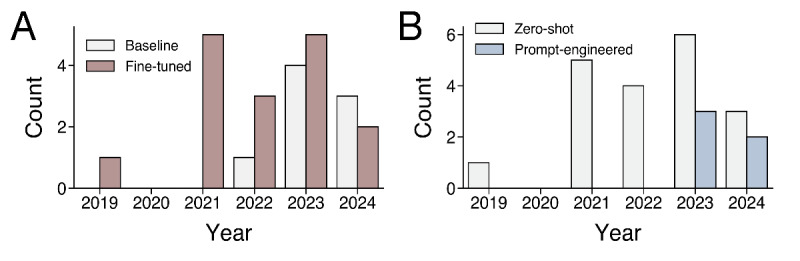
Results: The literature search yielded 24 studies for inclusion. The majority of studies assessed original and fine-tuned variants of the BERT LLM (n=18, 75%) followed by the Chat-GPT conversational LLM (n=6, 25%). LLMs for data extraction were commonly applied in pan-cancer clinical settings (n=11, 46%), followed by breast (n=4, 17%), and lung (n=4, 17%) cancer contexts, and were evaluated using multi-institution datasets (n=18, 75%). Comparing the studies published in 2022-2024 versus 2019-2021, both the total number of studies (18 vs 6) and the proportion of studies using prompt engineering increased (5/18, 28% vs 0/6, 0%), while the proportion using fine-tuning decreased (8/18, 44.4% vs 6/6, 100%). Advantages of LLMs included positive data extraction performance and reduced manual workload.
Conclusions: LLMs applied to data extraction in oncology can serve as useful automated tools to reduce the administrative burden of reviewing patient health records and increase time for patient-facing care. Recent advances in prompt-engineering and fine-tuning methods, and multimodal data extraction present promising directions for future research. Further studies are needed to evaluate the performance of LLM-enabled data extraction in clinical domains beyond the training dataset and to assess the scope and integration of LLMs into real-world clinical environments.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


