Yinyao Ma, Hanlin Lv, Yanhua Ma, Xiao Wang, Longting Lv, Xuxia Liang, Lei Wang
{"title":"推进子痫前期预测:一个定制的机器学习管道,集成了重采样和集成模型,用于处理不平衡的医疗数据。","authors":"Yinyao Ma, Hanlin Lv, Yanhua Ma, Xiao Wang, Longting Lv, Xuxia Liang, Lei Wang","doi":"10.1186/s13040-025-00440-1","DOIUrl":null,"url":null,"abstract":"<p><strong>Background: </strong>Constructing a predictive model is challenging in imbalanced medical dataset (such as preeclampsia), particularly when employing ensemble machine learning algorithms.</p><p><strong>Objective: </strong>This study aims to develop a robust pipeline that enhances the predictive performance of ensemble machine learning models for the early prediction of preeclampsia in an imbalanced dataset.</p><p><strong>Methods: </strong>Our research establishes a comprehensive pipeline optimized for early preeclampsia prediction in imbalanced medical datasets. We gathered electronic health records from pregnant women at the People's Hospital of Guangxi from 2015 to 2020, with additional external validation using three public datasets. This extensive data collection facilitated the systematic assessment of various resampling techniques, varied minority-to-majority ratios, and ensemble machine learning algorithms through a structured evaluation process. We analyzed 4,608 combinations of model settings against performance metrics such as G-mean, MCC, AP, and AUC to determine the most effective configurations. Advanced statistical analyses including OLS regression, ANOVA, and Kruskal-Wallis tests were utilized to fine-tune these settings, enhancing model performance and robustness for clinical application.</p><p><strong>Results: </strong>Our analysis confirmed the significant impact of systematic sequential optimization of variables on the predictive performance of our models. The most effective configuration utilized the Inverse Weighted Gaussian Mixture Model for resampling, combined with Gradient Boosting Decision Trees algorithm, and an optimized minority-to-majority ratio of 0.09, achieving a Geometric Mean of 0.6694 (95% confidence interval: 0.5855-0.7557). This configuration significantly outperformed the baseline across all evaluated metrics, demonstrating substantial improvements in model performance.</p><p><strong>Conclusions: </strong>This study establishes a robust pipeline that significantly enhances the predictive performance of models for preeclampsia within imbalanced datasets. Our findings underscore the importance of a strategic approach to variable optimization in medical diagnostics, offering potential for broad application in various medical contexts where class imbalance is a concern.</p>","PeriodicalId":48947,"journal":{"name":"Biodata Mining","volume":"18 1","pages":"25"},"PeriodicalIF":6.1000,"publicationDate":"2025-03-24","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC11934807/pdf/","citationCount":"0","resultStr":"{\"title\":\"Advancing preeclampsia prediction: a tailored machine learning pipeline integrating resampling and ensemble models for handling imbalanced medical data.\",\"authors\":\"Yinyao Ma, Hanlin Lv, Yanhua Ma, Xiao Wang, Longting Lv, Xuxia Liang, Lei Wang\",\"doi\":\"10.1186/s13040-025-00440-1\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><strong>Background: </strong>Constructing a predictive model is challenging in imbalanced medical dataset (such as preeclampsia), particularly when employing ensemble machine learning algorithms.</p><p><strong>Objective: </strong>This study aims to develop a robust pipeline that enhances the predictive performance of ensemble machine learning models for the early prediction of preeclampsia in an imbalanced dataset.</p><p><strong>Methods: </strong>Our research establishes a comprehensive pipeline optimized for early preeclampsia prediction in imbalanced medical datasets. We gathered electronic health records from pregnant women at the People's Hospital of Guangxi from 2015 to 2020, with additional external validation using three public datasets. This extensive data collection facilitated the systematic assessment of various resampling techniques, varied minority-to-majority ratios, and ensemble machine learning algorithms through a structured evaluation process. We analyzed 4,608 combinations of model settings against performance metrics such as G-mean, MCC, AP, and AUC to determine the most effective configurations. Advanced statistical analyses including OLS regression, ANOVA, and Kruskal-Wallis tests were utilized to fine-tune these settings, enhancing model performance and robustness for clinical application.</p><p><strong>Results: </strong>Our analysis confirmed the significant impact of systematic sequential optimization of variables on the predictive performance of our models. The most effective configuration utilized the Inverse Weighted Gaussian Mixture Model for resampling, combined with Gradient Boosting Decision Trees algorithm, and an optimized minority-to-majority ratio of 0.09, achieving a Geometric Mean of 0.6694 (95% confidence interval: 0.5855-0.7557). This configuration significantly outperformed the baseline across all evaluated metrics, demonstrating substantial improvements in model performance.</p><p><strong>Conclusions: </strong>This study establishes a robust pipeline that significantly enhances the predictive performance of models for preeclampsia within imbalanced datasets. Our findings underscore the importance of a strategic approach to variable optimization in medical diagnostics, offering potential for broad application in various medical contexts where class imbalance is a concern.</p>\",\"PeriodicalId\":48947,\"journal\":{\"name\":\"Biodata Mining\",\"volume\":\"18 1\",\"pages\":\"25\"},\"PeriodicalIF\":6.1000,\"publicationDate\":\"2025-03-24\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC11934807/pdf/\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Biodata Mining\",\"FirstCategoryId\":\"99\",\"ListUrlMain\":\"https://doi.org/10.1186/s13040-025-00440-1\",\"RegionNum\":3,\"RegionCategory\":\"生物学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q1\",\"JCRName\":\"MATHEMATICAL & COMPUTATIONAL BIOLOGY\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Biodata Mining","FirstCategoryId":"99","ListUrlMain":"https://doi.org/10.1186/s13040-025-00440-1","RegionNum":3,"RegionCategory":"生物学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"MATHEMATICAL & COMPUTATIONAL BIOLOGY","Score":null,"Total":0}
Advancing preeclampsia prediction: a tailored machine learning pipeline integrating resampling and ensemble models for handling imbalanced medical data.
Background: Constructing a predictive model is challenging in imbalanced medical dataset (such as preeclampsia), particularly when employing ensemble machine learning algorithms.
Objective: This study aims to develop a robust pipeline that enhances the predictive performance of ensemble machine learning models for the early prediction of preeclampsia in an imbalanced dataset.
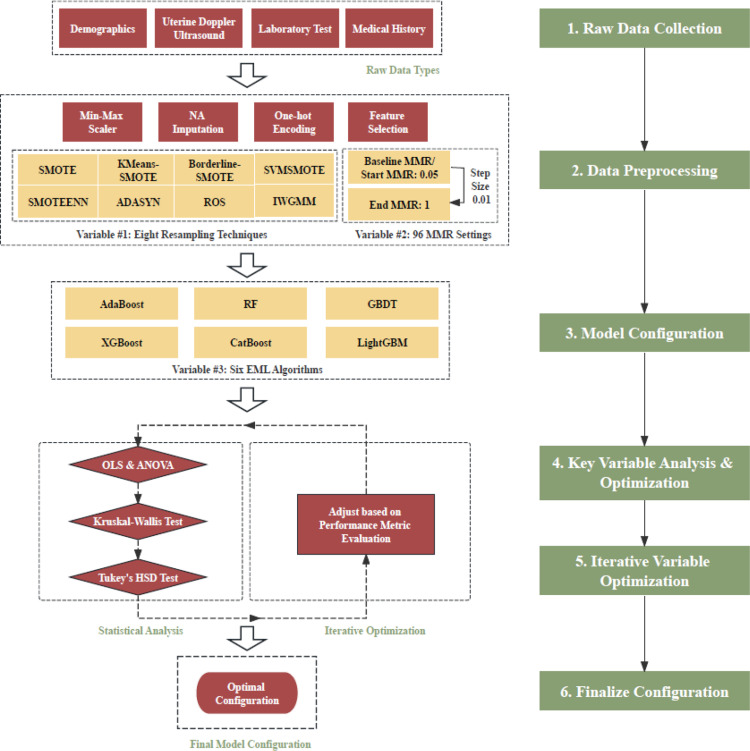
Methods: Our research establishes a comprehensive pipeline optimized for early preeclampsia prediction in imbalanced medical datasets. We gathered electronic health records from pregnant women at the People's Hospital of Guangxi from 2015 to 2020, with additional external validation using three public datasets. This extensive data collection facilitated the systematic assessment of various resampling techniques, varied minority-to-majority ratios, and ensemble machine learning algorithms through a structured evaluation process. We analyzed 4,608 combinations of model settings against performance metrics such as G-mean, MCC, AP, and AUC to determine the most effective configurations. Advanced statistical analyses including OLS regression, ANOVA, and Kruskal-Wallis tests were utilized to fine-tune these settings, enhancing model performance and robustness for clinical application.
Results: Our analysis confirmed the significant impact of systematic sequential optimization of variables on the predictive performance of our models. The most effective configuration utilized the Inverse Weighted Gaussian Mixture Model for resampling, combined with Gradient Boosting Decision Trees algorithm, and an optimized minority-to-majority ratio of 0.09, achieving a Geometric Mean of 0.6694 (95% confidence interval: 0.5855-0.7557). This configuration significantly outperformed the baseline across all evaluated metrics, demonstrating substantial improvements in model performance.
Conclusions: This study establishes a robust pipeline that significantly enhances the predictive performance of models for preeclampsia within imbalanced datasets. Our findings underscore the importance of a strategic approach to variable optimization in medical diagnostics, offering potential for broad application in various medical contexts where class imbalance is a concern.
期刊介绍:
BioData Mining is an open access, open peer-reviewed journal encompassing research on all aspects of data mining applied to high-dimensional biological and biomedical data, focusing on computational aspects of knowledge discovery from large-scale genetic, transcriptomic, genomic, proteomic, and metabolomic data.
Topical areas include, but are not limited to:
-Development, evaluation, and application of novel data mining and machine learning algorithms.
-Adaptation, evaluation, and application of traditional data mining and machine learning algorithms.
-Open-source software for the application of data mining and machine learning algorithms.
-Design, development and integration of databases, software and web services for the storage, management, retrieval, and analysis of data from large scale studies.
-Pre-processing, post-processing, modeling, and interpretation of data mining and machine learning results for biological interpretation and knowledge discovery.


 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


