{"title":"探索现实世界健康数据记录链接的复杂性——一个连接癌症登记和索赔数据的示范研究。","authors":"Nadja Lendle, Bianca Kollhorst, Timm Intemann","doi":"10.1002/pds.70120","DOIUrl":null,"url":null,"abstract":"<p><strong>Purpose: </strong>Record linkage based on quasi-identifiers remains an important approach as not every data source provides a comprehensive unique identifier. In this study, the reasons for the failure of a linkage based on quasi-identifiers were examined. Furthermore, informed algorithms using information on gold standard links were developed to investigate the potentially achievable linkage quality based on quasi-identifiers.</p><p><strong>Methods: </strong>The study population includes patients from an antidiabetic cohort from German claims and colorectal cancer patients from two German cancer registries. Linkage algorithms were applied using information on gold standard links. Informed linkage algorithms based on deterministic linkage, logistic regression, random forests, gradient boosting, and neural networks were derived and compared. Descriptive analyses were performed to identify reasons for the failure of linkage, such as discrepancies between data sources.</p><p><strong>Results: </strong>A gradient boosting-based linkage approach performed best, achieving a precision (positive predictive value) of 77%, a recall (sensitivity) of 81%, and an F*-measure (combining precision and recall) of 64%. Of 641 patients in GePaRD, 8% were not uniquely identifiable using birth year, sex, area of residence, and year and quarter of diagnosis, whereas 33% of 42 817 cancer registry patients were not uniquely identifiable with these quasi-identifiers.</p><p><strong>Conclusions: </strong>Linkage of German claims and cancer registry data based on quasi-identifiers does result in insufficient linkage quality since subjects cannot be uniquely identified. It is advisable to use unique identifiers from a subsample, if available, to derive informed linkage algorithms for the entire sample. In this case, the machine learning technique gradient boosting has been found to outperform other methods.</p>","PeriodicalId":19782,"journal":{"name":"Pharmacoepidemiology and Drug Safety","volume":"34 4","pages":"e70120"},"PeriodicalIF":2.4000,"publicationDate":"2025-04-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC11934838/pdf/","citationCount":"0","resultStr":"{\"title\":\"Exploring the Complexity of Real-World Health Data Record Linkage-An Exemplary Study Linking Cancer Registry and Claims Data.\",\"authors\":\"Nadja Lendle, Bianca Kollhorst, Timm Intemann\",\"doi\":\"10.1002/pds.70120\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><strong>Purpose: </strong>Record linkage based on quasi-identifiers remains an important approach as not every data source provides a comprehensive unique identifier. In this study, the reasons for the failure of a linkage based on quasi-identifiers were examined. Furthermore, informed algorithms using information on gold standard links were developed to investigate the potentially achievable linkage quality based on quasi-identifiers.</p><p><strong>Methods: </strong>The study population includes patients from an antidiabetic cohort from German claims and colorectal cancer patients from two German cancer registries. Linkage algorithms were applied using information on gold standard links. Informed linkage algorithms based on deterministic linkage, logistic regression, random forests, gradient boosting, and neural networks were derived and compared. Descriptive analyses were performed to identify reasons for the failure of linkage, such as discrepancies between data sources.</p><p><strong>Results: </strong>A gradient boosting-based linkage approach performed best, achieving a precision (positive predictive value) of 77%, a recall (sensitivity) of 81%, and an F*-measure (combining precision and recall) of 64%. Of 641 patients in GePaRD, 8% were not uniquely identifiable using birth year, sex, area of residence, and year and quarter of diagnosis, whereas 33% of 42 817 cancer registry patients were not uniquely identifiable with these quasi-identifiers.</p><p><strong>Conclusions: </strong>Linkage of German claims and cancer registry data based on quasi-identifiers does result in insufficient linkage quality since subjects cannot be uniquely identified. It is advisable to use unique identifiers from a subsample, if available, to derive informed linkage algorithms for the entire sample. In this case, the machine learning technique gradient boosting has been found to outperform other methods.</p>\",\"PeriodicalId\":19782,\"journal\":{\"name\":\"Pharmacoepidemiology and Drug Safety\",\"volume\":\"34 4\",\"pages\":\"e70120\"},\"PeriodicalIF\":2.4000,\"publicationDate\":\"2025-04-01\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC11934838/pdf/\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Pharmacoepidemiology and Drug Safety\",\"FirstCategoryId\":\"3\",\"ListUrlMain\":\"https://doi.org/10.1002/pds.70120\",\"RegionNum\":4,\"RegionCategory\":\"医学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q3\",\"JCRName\":\"PHARMACOLOGY & PHARMACY\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Pharmacoepidemiology and Drug Safety","FirstCategoryId":"3","ListUrlMain":"https://doi.org/10.1002/pds.70120","RegionNum":4,"RegionCategory":"医学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q3","JCRName":"PHARMACOLOGY & PHARMACY","Score":null,"Total":0}
Exploring the Complexity of Real-World Health Data Record Linkage-An Exemplary Study Linking Cancer Registry and Claims Data.
Purpose: Record linkage based on quasi-identifiers remains an important approach as not every data source provides a comprehensive unique identifier. In this study, the reasons for the failure of a linkage based on quasi-identifiers were examined. Furthermore, informed algorithms using information on gold standard links were developed to investigate the potentially achievable linkage quality based on quasi-identifiers.
Methods: The study population includes patients from an antidiabetic cohort from German claims and colorectal cancer patients from two German cancer registries. Linkage algorithms were applied using information on gold standard links. Informed linkage algorithms based on deterministic linkage, logistic regression, random forests, gradient boosting, and neural networks were derived and compared. Descriptive analyses were performed to identify reasons for the failure of linkage, such as discrepancies between data sources.
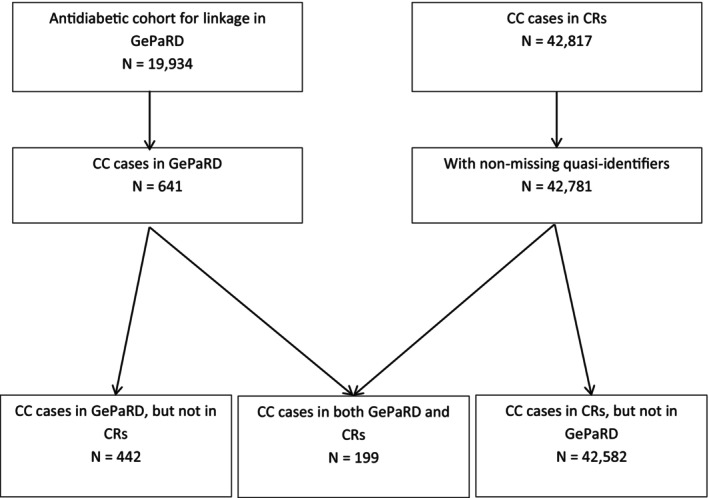
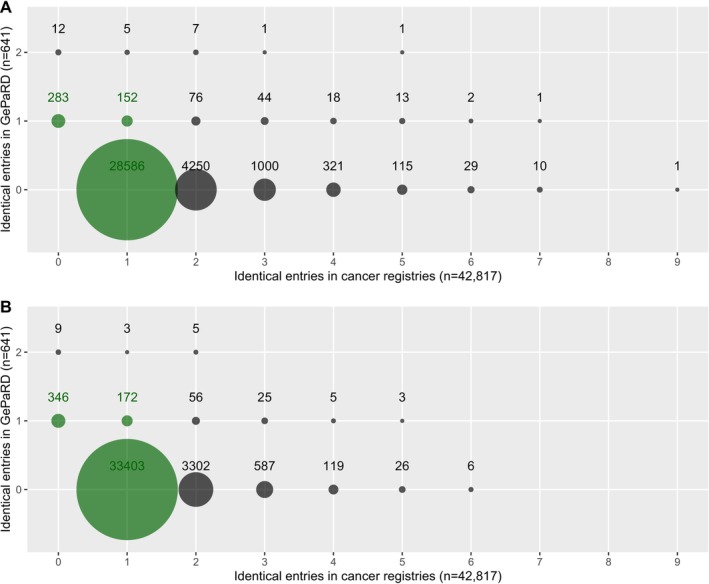
Results: A gradient boosting-based linkage approach performed best, achieving a precision (positive predictive value) of 77%, a recall (sensitivity) of 81%, and an F*-measure (combining precision and recall) of 64%. Of 641 patients in GePaRD, 8% were not uniquely identifiable using birth year, sex, area of residence, and year and quarter of diagnosis, whereas 33% of 42 817 cancer registry patients were not uniquely identifiable with these quasi-identifiers.
Conclusions: Linkage of German claims and cancer registry data based on quasi-identifiers does result in insufficient linkage quality since subjects cannot be uniquely identified. It is advisable to use unique identifiers from a subsample, if available, to derive informed linkage algorithms for the entire sample. In this case, the machine learning technique gradient boosting has been found to outperform other methods.
期刊介绍:
The aim of Pharmacoepidemiology and Drug Safety is to provide an international forum for the communication and evaluation of data, methods and opinion in the discipline of pharmacoepidemiology. The Journal publishes peer-reviewed reports of original research, invited reviews and a variety of guest editorials and commentaries embracing scientific, medical, statistical, legal and economic aspects of pharmacoepidemiology and post-marketing surveillance of drug safety. Appropriate material in these categories may also be considered for publication as a Brief Report.
Particular areas of interest include:
design, analysis, results, and interpretation of studies looking at the benefit or safety of specific pharmaceuticals, biologics, or medical devices, including studies in pharmacovigilance, postmarketing surveillance, pharmacoeconomics, patient safety, molecular pharmacoepidemiology, or any other study within the broad field of pharmacoepidemiology;
comparative effectiveness research relating to pharmaceuticals, biologics, and medical devices. Comparative effectiveness research is the generation and synthesis of evidence that compares the benefits and harms of alternative methods to prevent, diagnose, treat, and monitor a clinical condition, as these methods are truly used in the real world;
methodologic contributions of relevance to pharmacoepidemiology, whether original contributions, reviews of existing methods, or tutorials for how to apply the methods of pharmacoepidemiology;
assessments of harm versus benefit in drug therapy;
patterns of drug utilization;
relationships between pharmacoepidemiology and the formulation and interpretation of regulatory guidelines;
evaluations of risk management plans and programmes relating to pharmaceuticals, biologics and medical devices.


 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


