{"title":"Tukey的g- &-h分布的有限混合估计和模型选择。","authors":"Tingting Zhan, Misung Yi, Amy R Peck, Hallgeir Rui, Inna Chervoneva","doi":"10.1007/s11222-025-10596-9","DOIUrl":null,"url":null,"abstract":"<p><p>A finite mixture of distributions is a popular statistical model, which is especially meaningful when the population of interest may include distinct subpopulations. This work is motivated by analysis of protein expression levels quantified using immunofluorescence immunohistochemistry assays of human tissues. The distributions of cellular protein expression levels in a tissue often exhibit multimodality, skewness and heavy tails, but there is a substantial variability between distributions in different tissues from different subjects, while some of these mixture distributions include components consistent with the assumption of a normal distribution. To accommodate such diversity, we propose a mixture of 4-parameter Tukey's <i>g</i>- &-<i>h</i> distributions for fitting finite mixtures with both Gaussian and non-Gaussian components. Tukey's <i>g</i>- &-<i>h</i> distribution is a flexible model that allows variable degree of skewness and kurtosis in mixture components, including normal distribution as a particular case. Since the likelihood of the Tukey's <i>g</i>- &-<i>h</i> mixtures does not have a closed analytical form, we propose a quantile least Mahalanobis distance (QLMD) estimator for parameters of such mixtures. QLMD is an indirect estimator minimizing the Mahalanobis distance between the sample and model-based quantiles, and its asymptotic properties follow from the general theory of indirect estimation. We have developed a stepwise algorithm to select a parsimonious Tukey's <i>g</i>- &-<i>h</i> mixture model and implemented all proposed methods in the R package QuantileGH available on CRAN. A simulation study was conducted to evaluate performance of the Tukey's <i>g</i>- &-<i>h</i> mixtures and compare to performance of mixtures of skew-normal or skew-<i>t</i> distributions. The Tukey's <i>g</i>- &-<i>h</i> mixtures were applied to model cellular expressions of Cyclin D1 protein in breast cancer tissues, and resulting parameter estimates evaluated as predictors of progression-free survival.</p>","PeriodicalId":22058,"journal":{"name":"Statistics and Computing","volume":"35 3","pages":"67"},"PeriodicalIF":1.6000,"publicationDate":"2025-01-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC11910465/pdf/","citationCount":"0","resultStr":"{\"title\":\"Estimation and model selection for finite mixtures of Tukey's <i>g</i>- &-<i>h</i> distributions.\",\"authors\":\"Tingting Zhan, Misung Yi, Amy R Peck, Hallgeir Rui, Inna Chervoneva\",\"doi\":\"10.1007/s11222-025-10596-9\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><p>A finite mixture of distributions is a popular statistical model, which is especially meaningful when the population of interest may include distinct subpopulations. This work is motivated by analysis of protein expression levels quantified using immunofluorescence immunohistochemistry assays of human tissues. The distributions of cellular protein expression levels in a tissue often exhibit multimodality, skewness and heavy tails, but there is a substantial variability between distributions in different tissues from different subjects, while some of these mixture distributions include components consistent with the assumption of a normal distribution. To accommodate such diversity, we propose a mixture of 4-parameter Tukey's <i>g</i>- &-<i>h</i> distributions for fitting finite mixtures with both Gaussian and non-Gaussian components. Tukey's <i>g</i>- &-<i>h</i> distribution is a flexible model that allows variable degree of skewness and kurtosis in mixture components, including normal distribution as a particular case. Since the likelihood of the Tukey's <i>g</i>- &-<i>h</i> mixtures does not have a closed analytical form, we propose a quantile least Mahalanobis distance (QLMD) estimator for parameters of such mixtures. QLMD is an indirect estimator minimizing the Mahalanobis distance between the sample and model-based quantiles, and its asymptotic properties follow from the general theory of indirect estimation. We have developed a stepwise algorithm to select a parsimonious Tukey's <i>g</i>- &-<i>h</i> mixture model and implemented all proposed methods in the R package QuantileGH available on CRAN. A simulation study was conducted to evaluate performance of the Tukey's <i>g</i>- &-<i>h</i> mixtures and compare to performance of mixtures of skew-normal or skew-<i>t</i> distributions. The Tukey's <i>g</i>- &-<i>h</i> mixtures were applied to model cellular expressions of Cyclin D1 protein in breast cancer tissues, and resulting parameter estimates evaluated as predictors of progression-free survival.</p>\",\"PeriodicalId\":22058,\"journal\":{\"name\":\"Statistics and Computing\",\"volume\":\"35 3\",\"pages\":\"67\"},\"PeriodicalIF\":1.6000,\"publicationDate\":\"2025-01-01\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC11910465/pdf/\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Statistics and Computing\",\"FirstCategoryId\":\"100\",\"ListUrlMain\":\"https://doi.org/10.1007/s11222-025-10596-9\",\"RegionNum\":2,\"RegionCategory\":\"数学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"2025/3/15 0:00:00\",\"PubModel\":\"Epub\",\"JCR\":\"Q2\",\"JCRName\":\"COMPUTER SCIENCE, THEORY & METHODS\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Statistics and Computing","FirstCategoryId":"100","ListUrlMain":"https://doi.org/10.1007/s11222-025-10596-9","RegionNum":2,"RegionCategory":"数学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2025/3/15 0:00:00","PubModel":"Epub","JCR":"Q2","JCRName":"COMPUTER SCIENCE, THEORY & METHODS","Score":null,"Total":0}
Estimation and model selection for finite mixtures of Tukey's g- &-h distributions.
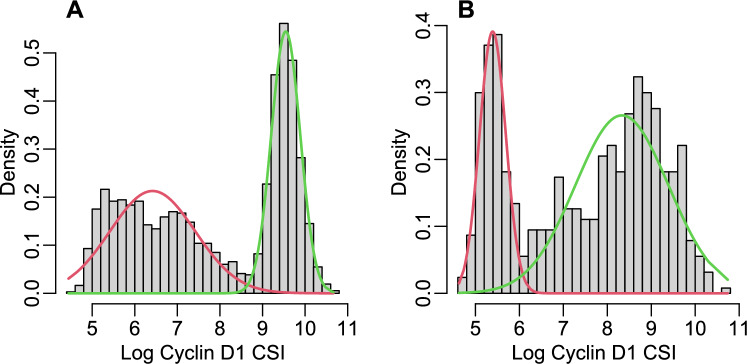
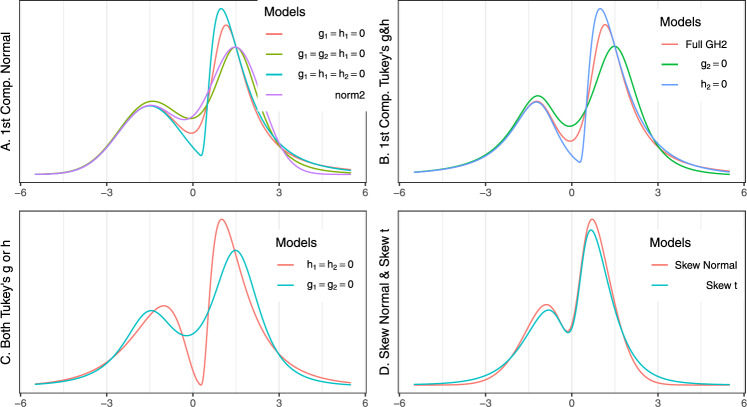
A finite mixture of distributions is a popular statistical model, which is especially meaningful when the population of interest may include distinct subpopulations. This work is motivated by analysis of protein expression levels quantified using immunofluorescence immunohistochemistry assays of human tissues. The distributions of cellular protein expression levels in a tissue often exhibit multimodality, skewness and heavy tails, but there is a substantial variability between distributions in different tissues from different subjects, while some of these mixture distributions include components consistent with the assumption of a normal distribution. To accommodate such diversity, we propose a mixture of 4-parameter Tukey's g- &-h distributions for fitting finite mixtures with both Gaussian and non-Gaussian components. Tukey's g- &-h distribution is a flexible model that allows variable degree of skewness and kurtosis in mixture components, including normal distribution as a particular case. Since the likelihood of the Tukey's g- &-h mixtures does not have a closed analytical form, we propose a quantile least Mahalanobis distance (QLMD) estimator for parameters of such mixtures. QLMD is an indirect estimator minimizing the Mahalanobis distance between the sample and model-based quantiles, and its asymptotic properties follow from the general theory of indirect estimation. We have developed a stepwise algorithm to select a parsimonious Tukey's g- &-h mixture model and implemented all proposed methods in the R package QuantileGH available on CRAN. A simulation study was conducted to evaluate performance of the Tukey's g- &-h mixtures and compare to performance of mixtures of skew-normal or skew-t distributions. The Tukey's g- &-h mixtures were applied to model cellular expressions of Cyclin D1 protein in breast cancer tissues, and resulting parameter estimates evaluated as predictors of progression-free survival.
期刊介绍:
Statistics and Computing is a bi-monthly refereed journal which publishes papers covering the range of the interface between the statistical and computing sciences.
In particular, it addresses the use of statistical concepts in computing science, for example in machine learning, computer vision and data analytics, as well as the use of computers in data modelling, prediction and analysis. Specific topics which are covered include: techniques for evaluating analytically intractable problems such as bootstrap resampling, Markov chain Monte Carlo, sequential Monte Carlo, approximate Bayesian computation, search and optimization methods, stochastic simulation and Monte Carlo, graphics, computer environments, statistical approaches to software errors, information retrieval, machine learning, statistics of databases and database technology, huge data sets and big data analytics, computer algebra, graphical models, image processing, tomography, inverse problems and uncertainty quantification.
In addition, the journal contains original research reports, authoritative review papers, discussed papers, and occasional special issues on particular topics or carrying proceedings of relevant conferences. Statistics and Computing also publishes book review and software review sections.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


