基于知识蒸馏的药物发现数据驱动的联邦学习
IF 23.9
1区 计算机科学
Q1 COMPUTER SCIENCE, ARTIFICIAL INTELLIGENCE
引用次数: 0
摘要
人工智能在科学研究中的一个主要挑战是确保获得足够的、高质量的数据,以开发有影响力的模型。尽管有大量的公共数据,但最有价值的知识往往仍隐藏在机密的企业数据孤岛中。尽管行业越来越愿意分享非竞争性的见解,但这种合作往往受到底层数据保密性的限制。联邦学习可以在不损害数据隐私的情况下共享知识,但它有明显的局限性。在这里,我们介绍FLuID(使用信息蒸馏的联邦学习),这是一种以数据为中心的联邦蒸馏应用程序,专为药物发现量身定制,旨在保护数据隐私。我们在两个实验中验证了FLuID,第一个实验涉及模拟虚拟财团的公共数据,第二个实验涉及八家制药公司之间的现实研究合作。尽管将模型与合作伙伴的特定领域保持一致仍然具有挑战性,但FLuID的数据驱动特性为减轻领域转移提供了几种途径。FLuID促进了制药组织之间的知识共享,为在生物活性预测中具有增强性能和扩展适用性的新一代模型铺平了道路。本文章由计算机程序翻译,如有差异,请以英文原文为准。

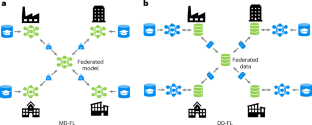
Data-driven federated learning in drug discovery with knowledge distillation
A main challenge for artificial intelligence in scientific research is ensuring access to sufficient, high-quality data for the development of impactful models. Despite the abundance of public data, the most valuable knowledge often remains embedded within confidential corporate data silos. Although industries are increasingly open to sharing non-competitive insights, such collaboration is often constrained by the confidentiality of the underlying data. Federated learning makes it possible to share knowledge without compromising data privacy, but it has notable limitations. Here, we introduce FLuID (federated learning using information distillation), a data-centric application of federated distillation tailored to drug discovery aiming to preserve data privacy. We validate FLuID in two experiments, first involving public data simulating a virtual consortium and second in a real-world research collaboration between eight pharmaceutical companies. Although the alignment of the models with the partner specific domain remains challenging, the data-driven nature of FLuID offers several avenues to mitigate domain shift. FLuID fosters knowledge sharing among pharmaceutical organizations, paving the way for a new generation of models with enhanced performance and an expanded applicability domain in biological activity predictions. FLuID enables privacy-preserving knowledge sharing in drug discovery using knowledge distillation. The results show that the approach expands applicability domains and fosters collaboration across organizations without compromising data privacy or security.
求助全文
通过发布文献求助,成功后即可免费获取论文全文。
去求助
来源期刊

Nature Machine Intelligence
Multiple-
CiteScore
36.90
自引率
2.10%
发文量
127
期刊介绍:
Nature Machine Intelligence is a distinguished publication that presents original research and reviews on various topics in machine learning, robotics, and AI. Our focus extends beyond these fields, exploring their profound impact on other scientific disciplines, as well as societal and industrial aspects. We recognize limitless possibilities wherein machine intelligence can augment human capabilities and knowledge in domains like scientific exploration, healthcare, medical diagnostics, and the creation of safe and sustainable cities, transportation, and agriculture. Simultaneously, we acknowledge the emergence of ethical, social, and legal concerns due to the rapid pace of advancements.
To foster interdisciplinary discussions on these far-reaching implications, Nature Machine Intelligence serves as a platform for dialogue facilitated through Comments, News Features, News & Views articles, and Correspondence. Our goal is to encourage a comprehensive examination of these subjects.
Similar to all Nature-branded journals, Nature Machine Intelligence operates under the guidance of a team of skilled editors. We adhere to a fair and rigorous peer-review process, ensuring high standards of copy-editing and production, swift publication, and editorial independence.
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


