关于AI自噬的注意事项
IF 18.8
1区 计算机科学
Q1 COMPUTER SCIENCE, ARTIFICIAL INTELLIGENCE
引用次数: 0
摘要
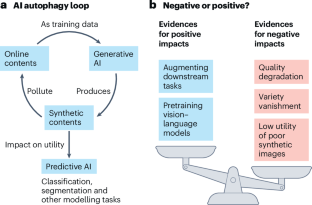
生成式人工智能(AI)技术和大型模型正在各种领域(如图像、文本、语音和音乐)产生逼真的输出。创建这些高级生成模型需要大量资源,特别是大型和高质量的数据集。为了最大限度地减少训练费用,许多算法开发人员使用模型本身创建的数据作为经济有效的训练解决方案。然而,并非所有合成数据都能有效地提高模型性能,因此需要在使用真实数据和合成数据之间取得战略平衡,以优化结果。目前,以前控制良好的真实数据和合成数据的集成正在变得不可控。合成数据在网上的广泛和不受监管的传播,导致传统上通过网络抓取汇编的数据集受到污染,现在与未标记的合成数据混合在一起。这种趋势被称为人工智能自噬现象,它表明,未来生成式人工智能系统可能会越来越多地在没有识别的情况下消耗自己的输出,这引发了对模型性能、可靠性和伦理影响的担忧。如果生成式人工智能不断地消耗自己而没有洞察力,会发生什么?我们可以采取什么措施来减轻潜在的不利影响?为了解决这些研究问题,本展望研究了现有文献,深入研究了人工智能自噬的后果,分析了相关风险,并探索了减轻其影响的策略。我们的目标是对这一现象提供一个全面的视角,倡导一种平衡的方法,促进大模型时代生成人工智能技术的可持续发展。本文章由计算机程序翻译,如有差异,请以英文原文为准。

On the caveats of AI autophagy
Generative artificial intelligence (AI) technologies and large models are producing realistic outputs across various domains, such as images, text, speech and music. Creating these advanced generative models requires significant resources, particularly large and high-quality datasets. To minimize training expenses, many algorithm developers use data created by the models themselves as a cost-effective training solution. However, not all synthetic data effectively improve model performance, necessitating a strategic balance in the use of real versus synthetic data to optimize outcomes. Currently, the previously well-controlled integration of real and synthetic data is becoming uncontrollable. The widespread and unregulated dissemination of synthetic data online leads to the contamination of datasets traditionally compiled through web scraping, now mixed with unlabelled synthetic data. This trend, known as the AI autophagy phenomenon, suggests a future where generative AI systems may increasingly consume their own outputs without discernment, raising concerns about model performance, reliability and ethical implications. What will happen if generative AI continuously consumes itself without discernment? What measures can we take to mitigate the potential adverse effects? To address these research questions, this Perspective examines the existing literature, delving into the consequences of AI autophagy, analysing the associated risks and exploring strategies to mitigate its impact. Our aim is to provide a comprehensive perspective on this phenomenon advocating for a balanced approach that promotes the sustainable development of generative AI technologies in the era of large models. With widespread generation and availability of synthetic data, AI systems are increasingly trained on their own outputs, leading to various technical and ethical challenges. The authors analyse this development and discuss measures to mitigate the potential adverse effects of ‘AI eating itself’.
求助全文
通过发布文献求助,成功后即可免费获取论文全文。
去求助
来源期刊

Nature Machine Intelligence
Multiple-
CiteScore
36.90
自引率
2.10%
发文量
127
期刊介绍:
Nature Machine Intelligence is a distinguished publication that presents original research and reviews on various topics in machine learning, robotics, and AI. Our focus extends beyond these fields, exploring their profound impact on other scientific disciplines, as well as societal and industrial aspects. We recognize limitless possibilities wherein machine intelligence can augment human capabilities and knowledge in domains like scientific exploration, healthcare, medical diagnostics, and the creation of safe and sustainable cities, transportation, and agriculture. Simultaneously, we acknowledge the emergence of ethical, social, and legal concerns due to the rapid pace of advancements.
To foster interdisciplinary discussions on these far-reaching implications, Nature Machine Intelligence serves as a platform for dialogue facilitated through Comments, News Features, News & Views articles, and Correspondence. Our goal is to encourage a comprehensive examination of these subjects.
Similar to all Nature-branded journals, Nature Machine Intelligence operates under the guidance of a team of skilled editors. We adhere to a fair and rigorous peer-review process, ensuring high standards of copy-editing and production, swift publication, and editorial independence.
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


