Mingye Gao, Aman Varshney, Shan Chen, Vikram Goddla, Jack Gallifant, Patrick Doyle, Claire Novack, Maeve Dillon-Martin, Teresia Perkins, Xinrong Correia, Erik Duhaime, Howard Isenstein, Elad Sharon, Lisa Soleymani Lehmann, David Kozono, Brian Anthony, Dmitriy Dligach, Danielle S Bitterman
{"title":"使用大型语言模型来增强癌症临床试验教材。","authors":"Mingye Gao, Aman Varshney, Shan Chen, Vikram Goddla, Jack Gallifant, Patrick Doyle, Claire Novack, Maeve Dillon-Martin, Teresia Perkins, Xinrong Correia, Erik Duhaime, Howard Isenstein, Elad Sharon, Lisa Soleymani Lehmann, David Kozono, Brian Anthony, Dmitriy Dligach, Danielle S Bitterman","doi":"10.1093/jncics/pkaf021","DOIUrl":null,"url":null,"abstract":"<p><strong>Background: </strong>Adequate patient awareness and understanding of cancer clinical trials is essential for trial recruitment, informed decision making, and protocol adherence. Although large language models (LLMs) have shown promise for patient education, their role in enhancing patient awareness of clinical trials remains unexplored. This study explored the performance and risks of LLMs in generating trial-specific educational content for potential participants.</p><p><strong>Methods: </strong>Generative Pretrained Transformer 4 (GPT4) was prompted to generate short clinical trial summaries and multiple-choice question-answer pairs from informed consent forms from ClinicalTrials.gov. Zero-shot learning was used for summaries, using a direct summarization, sequential extraction, and summarization approach. One-shot learning was used for question-answer pairs development. We evaluated performance through patient surveys of summary effectiveness and crowdsourced annotation of question-answer pair accuracy, using held-out cancer trial informed consent forms not used in prompt development.</p><p><strong>Results: </strong>For summaries, both prompting approaches achieved comparable results for readability and core content. Patients found summaries to be understandable and to improve clinical trial comprehension and interest in learning more about trials. The generated multiple-choice questions achieved high accuracy and agreement with crowdsourced annotators. For both summaries and multiple-choice questions, GPT4 was most likely to include inaccurate information when prompted to provide information that was not adequately described in the informed consent forms.</p><p><strong>Conclusions: </strong>LLMs such as GPT4 show promise in generating patient-friendly educational content for clinical trials with minimal trial-specific engineering. The findings serve as a proof of concept for the role of LLMs in improving patient education and engagement in clinical trials, as well as the need for ongoing human oversight.</p>","PeriodicalId":14681,"journal":{"name":"JNCI Cancer Spectrum","volume":" ","pages":""},"PeriodicalIF":4.1000,"publicationDate":"2025-03-03","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12362247/pdf/","citationCount":"0","resultStr":"{\"title\":\"The use of large language models to enhance cancer clinical trial educational materials.\",\"authors\":\"Mingye Gao, Aman Varshney, Shan Chen, Vikram Goddla, Jack Gallifant, Patrick Doyle, Claire Novack, Maeve Dillon-Martin, Teresia Perkins, Xinrong Correia, Erik Duhaime, Howard Isenstein, Elad Sharon, Lisa Soleymani Lehmann, David Kozono, Brian Anthony, Dmitriy Dligach, Danielle S Bitterman\",\"doi\":\"10.1093/jncics/pkaf021\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><strong>Background: </strong>Adequate patient awareness and understanding of cancer clinical trials is essential for trial recruitment, informed decision making, and protocol adherence. Although large language models (LLMs) have shown promise for patient education, their role in enhancing patient awareness of clinical trials remains unexplored. This study explored the performance and risks of LLMs in generating trial-specific educational content for potential participants.</p><p><strong>Methods: </strong>Generative Pretrained Transformer 4 (GPT4) was prompted to generate short clinical trial summaries and multiple-choice question-answer pairs from informed consent forms from ClinicalTrials.gov. Zero-shot learning was used for summaries, using a direct summarization, sequential extraction, and summarization approach. One-shot learning was used for question-answer pairs development. We evaluated performance through patient surveys of summary effectiveness and crowdsourced annotation of question-answer pair accuracy, using held-out cancer trial informed consent forms not used in prompt development.</p><p><strong>Results: </strong>For summaries, both prompting approaches achieved comparable results for readability and core content. Patients found summaries to be understandable and to improve clinical trial comprehension and interest in learning more about trials. The generated multiple-choice questions achieved high accuracy and agreement with crowdsourced annotators. For both summaries and multiple-choice questions, GPT4 was most likely to include inaccurate information when prompted to provide information that was not adequately described in the informed consent forms.</p><p><strong>Conclusions: </strong>LLMs such as GPT4 show promise in generating patient-friendly educational content for clinical trials with minimal trial-specific engineering. The findings serve as a proof of concept for the role of LLMs in improving patient education and engagement in clinical trials, as well as the need for ongoing human oversight.</p>\",\"PeriodicalId\":14681,\"journal\":{\"name\":\"JNCI Cancer Spectrum\",\"volume\":\" \",\"pages\":\"\"},\"PeriodicalIF\":4.1000,\"publicationDate\":\"2025-03-03\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12362247/pdf/\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"JNCI Cancer Spectrum\",\"FirstCategoryId\":\"1085\",\"ListUrlMain\":\"https://doi.org/10.1093/jncics/pkaf021\",\"RegionNum\":0,\"RegionCategory\":null,\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q2\",\"JCRName\":\"ONCOLOGY\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"JNCI Cancer Spectrum","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.1093/jncics/pkaf021","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q2","JCRName":"ONCOLOGY","Score":null,"Total":0}
The use of large language models to enhance cancer clinical trial educational materials.
Background: Adequate patient awareness and understanding of cancer clinical trials is essential for trial recruitment, informed decision making, and protocol adherence. Although large language models (LLMs) have shown promise for patient education, their role in enhancing patient awareness of clinical trials remains unexplored. This study explored the performance and risks of LLMs in generating trial-specific educational content for potential participants.
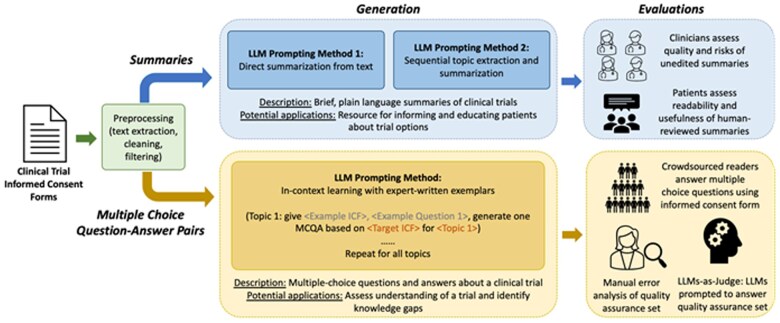
Methods: Generative Pretrained Transformer 4 (GPT4) was prompted to generate short clinical trial summaries and multiple-choice question-answer pairs from informed consent forms from ClinicalTrials.gov. Zero-shot learning was used for summaries, using a direct summarization, sequential extraction, and summarization approach. One-shot learning was used for question-answer pairs development. We evaluated performance through patient surveys of summary effectiveness and crowdsourced annotation of question-answer pair accuracy, using held-out cancer trial informed consent forms not used in prompt development.
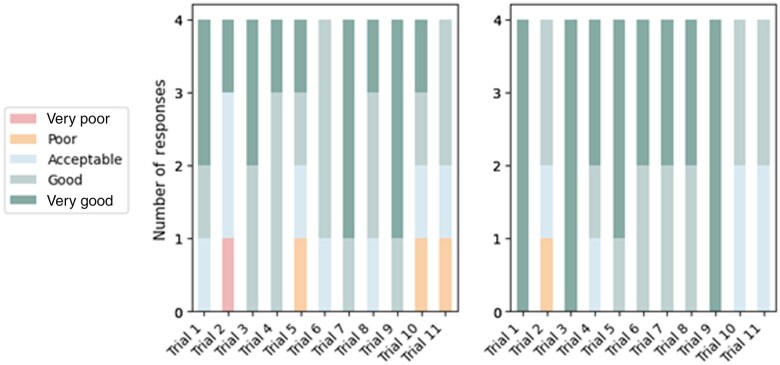
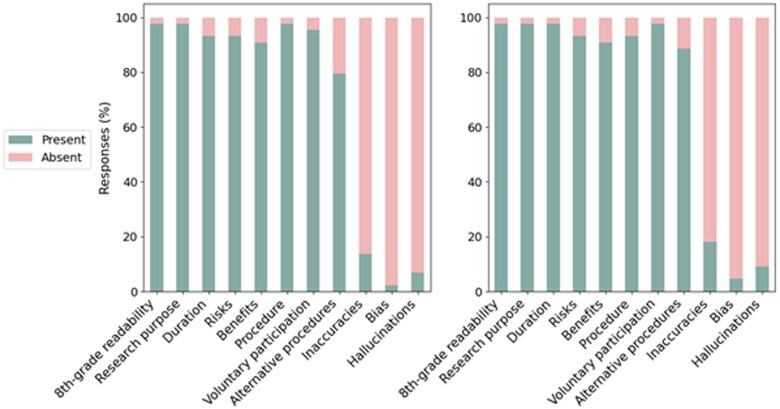
Results: For summaries, both prompting approaches achieved comparable results for readability and core content. Patients found summaries to be understandable and to improve clinical trial comprehension and interest in learning more about trials. The generated multiple-choice questions achieved high accuracy and agreement with crowdsourced annotators. For both summaries and multiple-choice questions, GPT4 was most likely to include inaccurate information when prompted to provide information that was not adequately described in the informed consent forms.
Conclusions: LLMs such as GPT4 show promise in generating patient-friendly educational content for clinical trials with minimal trial-specific engineering. The findings serve as a proof of concept for the role of LLMs in improving patient education and engagement in clinical trials, as well as the need for ongoing human oversight.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


