Ismat Mohd Sulaiman, Awang Bulgiba, Sameem Abdul Kareem, Abdul Aziz Latip
{"title":"使用机器学习破译马来西亚临床记录中的缩写。","authors":"Ismat Mohd Sulaiman, Awang Bulgiba, Sameem Abdul Kareem, Abdul Aziz Latip","doi":"10.1055/a-2521-4372","DOIUrl":null,"url":null,"abstract":"<p><strong>Objective: </strong> This is the first Malaysian machine learning model to detect and disambiguate abbreviations in clinical notes. The model has been designed to be incorporated into MyHarmony, a natural language processing system, that extracts clinical information for health care management. The model utilizes word embedding to ensure feasibility of use, not in real-time but for secondary analysis, within the constraints of low-resource settings.</p><p><strong>Methods: </strong> A Malaysian clinical embedding, based on Word2Vec model, was developed using 29,895 electronic discharge summaries. The embedding was compared against conventional rule-based and FastText embedding on two tasks: abbreviation detection and abbreviation disambiguation. Machine learning classifiers were applied to assess performance.</p><p><strong>Results: </strong> The Malaysian clinical word embedding contained 7 million word tokens, 24,352 unique vocabularies, and 100 dimensions. For abbreviation detection, the Decision Tree classifier augmented with the Malaysian clinical embedding showed the best performance (F-score of 0.9519). For abbreviation disambiguation, the classifier with the Malaysian clinical embedding had the best performance for most of the abbreviations (F-score of 0.9903).</p><p><strong>Conclusion: </strong> Despite having a smaller vocabulary and dimension, our local clinical word embedding performed better than the larger nonclinical FastText embedding. Word embedding with simple machine learning algorithms can decipher abbreviations well. It also requires lower computational resources and is suitable for implementation in low-resource settings such as Malaysia. The integration of this model into MyHarmony will improve recognition of clinical terms, thus improving the information generated for monitoring Malaysian health care services and policymaking.</p>","PeriodicalId":49822,"journal":{"name":"Methods of Information in Medicine","volume":" ","pages":"195-202"},"PeriodicalIF":1.8000,"publicationDate":"2024-12-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12196825/pdf/","citationCount":"0","resultStr":"{\"title\":\"Deciphering Abbreviations in Malaysian Clinical Notes Using Machine Learning.\",\"authors\":\"Ismat Mohd Sulaiman, Awang Bulgiba, Sameem Abdul Kareem, Abdul Aziz Latip\",\"doi\":\"10.1055/a-2521-4372\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><strong>Objective: </strong> This is the first Malaysian machine learning model to detect and disambiguate abbreviations in clinical notes. The model has been designed to be incorporated into MyHarmony, a natural language processing system, that extracts clinical information for health care management. The model utilizes word embedding to ensure feasibility of use, not in real-time but for secondary analysis, within the constraints of low-resource settings.</p><p><strong>Methods: </strong> A Malaysian clinical embedding, based on Word2Vec model, was developed using 29,895 electronic discharge summaries. The embedding was compared against conventional rule-based and FastText embedding on two tasks: abbreviation detection and abbreviation disambiguation. Machine learning classifiers were applied to assess performance.</p><p><strong>Results: </strong> The Malaysian clinical word embedding contained 7 million word tokens, 24,352 unique vocabularies, and 100 dimensions. For abbreviation detection, the Decision Tree classifier augmented with the Malaysian clinical embedding showed the best performance (F-score of 0.9519). For abbreviation disambiguation, the classifier with the Malaysian clinical embedding had the best performance for most of the abbreviations (F-score of 0.9903).</p><p><strong>Conclusion: </strong> Despite having a smaller vocabulary and dimension, our local clinical word embedding performed better than the larger nonclinical FastText embedding. Word embedding with simple machine learning algorithms can decipher abbreviations well. It also requires lower computational resources and is suitable for implementation in low-resource settings such as Malaysia. The integration of this model into MyHarmony will improve recognition of clinical terms, thus improving the information generated for monitoring Malaysian health care services and policymaking.</p>\",\"PeriodicalId\":49822,\"journal\":{\"name\":\"Methods of Information in Medicine\",\"volume\":\" \",\"pages\":\"195-202\"},\"PeriodicalIF\":1.8000,\"publicationDate\":\"2024-12-01\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12196825/pdf/\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Methods of Information in Medicine\",\"FirstCategoryId\":\"3\",\"ListUrlMain\":\"https://doi.org/10.1055/a-2521-4372\",\"RegionNum\":4,\"RegionCategory\":\"医学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"2025/1/22 0:00:00\",\"PubModel\":\"Epub\",\"JCR\":\"Q3\",\"JCRName\":\"COMPUTER SCIENCE, INFORMATION SYSTEMS\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Methods of Information in Medicine","FirstCategoryId":"3","ListUrlMain":"https://doi.org/10.1055/a-2521-4372","RegionNum":4,"RegionCategory":"医学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2025/1/22 0:00:00","PubModel":"Epub","JCR":"Q3","JCRName":"COMPUTER SCIENCE, INFORMATION SYSTEMS","Score":null,"Total":0}
Deciphering Abbreviations in Malaysian Clinical Notes Using Machine Learning.
Objective: This is the first Malaysian machine learning model to detect and disambiguate abbreviations in clinical notes. The model has been designed to be incorporated into MyHarmony, a natural language processing system, that extracts clinical information for health care management. The model utilizes word embedding to ensure feasibility of use, not in real-time but for secondary analysis, within the constraints of low-resource settings.
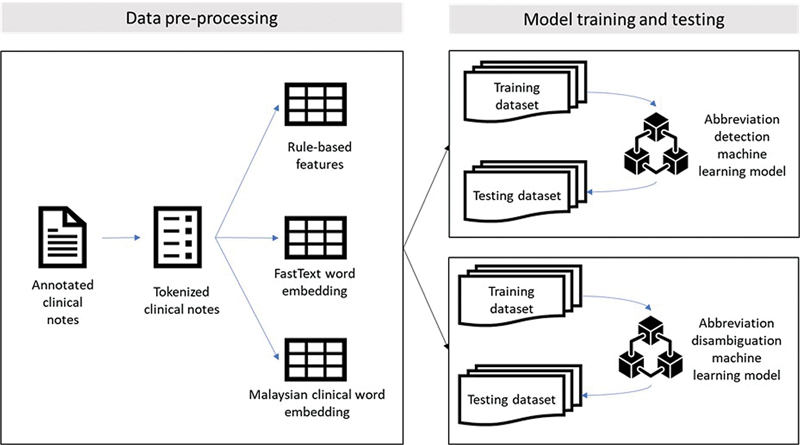
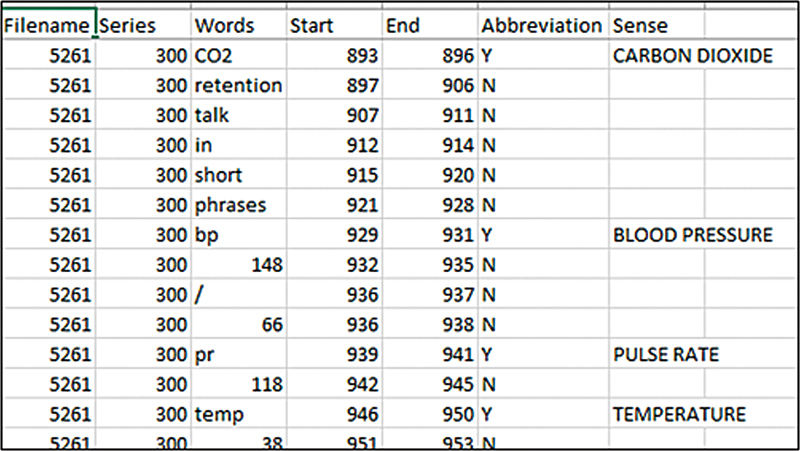
Methods: A Malaysian clinical embedding, based on Word2Vec model, was developed using 29,895 electronic discharge summaries. The embedding was compared against conventional rule-based and FastText embedding on two tasks: abbreviation detection and abbreviation disambiguation. Machine learning classifiers were applied to assess performance.
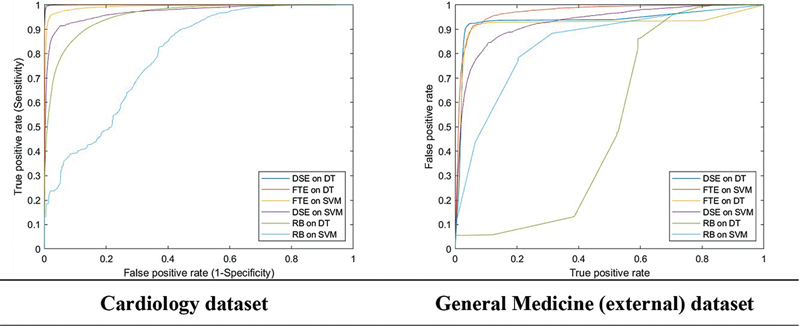
Results: The Malaysian clinical word embedding contained 7 million word tokens, 24,352 unique vocabularies, and 100 dimensions. For abbreviation detection, the Decision Tree classifier augmented with the Malaysian clinical embedding showed the best performance (F-score of 0.9519). For abbreviation disambiguation, the classifier with the Malaysian clinical embedding had the best performance for most of the abbreviations (F-score of 0.9903).
Conclusion: Despite having a smaller vocabulary and dimension, our local clinical word embedding performed better than the larger nonclinical FastText embedding. Word embedding with simple machine learning algorithms can decipher abbreviations well. It also requires lower computational resources and is suitable for implementation in low-resource settings such as Malaysia. The integration of this model into MyHarmony will improve recognition of clinical terms, thus improving the information generated for monitoring Malaysian health care services and policymaking.
期刊介绍:
Good medicine and good healthcare demand good information. Since the journal''s founding in 1962, Methods of Information in Medicine has stressed the methodology and scientific fundamentals of organizing, representing and analyzing data, information and knowledge in biomedicine and health care. Covering publications in the fields of biomedical and health informatics, medical biometry, and epidemiology, the journal publishes original papers, reviews, reports, opinion papers, editorials, and letters to the editor. From time to time, the journal publishes articles on particular focus themes as part of a journal''s issue.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


