Florian Borchert, Ignacio Llorca, Roland Roller, Bert Arnrich, Matthieu-P Schapranow
{"title":"xMEN:用于跨语言医疗实体规范化的模块化工具包。","authors":"Florian Borchert, Ignacio Llorca, Roland Roller, Bert Arnrich, Matthieu-P Schapranow","doi":"10.1093/jamiaopen/ooae147","DOIUrl":null,"url":null,"abstract":"<p><strong>Objective: </strong>To improve performance of medical entity normalization across many languages, especially when fewer language resources are available compared to English.</p><p><strong>Materials and methods: </strong>We propose xMEN, a modular system for cross-lingual (x) medical entity normalization (MEN), accommodating both low- and high-resource scenarios. To account for the scarcity of aliases for many target languages and terminologies, we leverage multilingual aliases via cross-lingual candidate generation. For candidate ranking, we incorporate a trainable cross-encoder (CE) model if annotations for the target task are available. To balance the output of general-purpose candidate generators with subsequent trainable re-rankers, we introduce a novel rank regularization term in the loss function for training CEs. For re-ranking without gold-standard annotations, we introduce multiple new weakly labeled datasets using machine translation and projection of annotations from a high-resource language.</p><p><strong>Results: </strong>xMEN improves the state-of-the-art performance across various benchmark datasets for several European languages. Weakly supervised CEs are effective when no training data is available for the target task.</p><p><strong>Discussion: </strong>We perform an analysis of normalization errors, revealing that complex entities are still challenging to normalize. New modules and benchmark datasets can be easily integrated in the future.</p><p><strong>Conclusion: </strong>xMEN exhibits strong performance for medical entity normalization in many languages, even when no labeled data and few terminology aliases for the target language are available. To enable reproducible benchmarks in the future, we make the system available as an open-source Python toolkit. The pre-trained models and source code are available online: https://github.com/hpi-dhc/xmen.</p>","PeriodicalId":36278,"journal":{"name":"JAMIA Open","volume":"8 1","pages":"ooae147"},"PeriodicalIF":3.4000,"publicationDate":"2024-12-26","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC11671143/pdf/","citationCount":"0","resultStr":"{\"title\":\"xMEN: a modular toolkit for cross-lingual medical entity normalization.\",\"authors\":\"Florian Borchert, Ignacio Llorca, Roland Roller, Bert Arnrich, Matthieu-P Schapranow\",\"doi\":\"10.1093/jamiaopen/ooae147\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><strong>Objective: </strong>To improve performance of medical entity normalization across many languages, especially when fewer language resources are available compared to English.</p><p><strong>Materials and methods: </strong>We propose xMEN, a modular system for cross-lingual (x) medical entity normalization (MEN), accommodating both low- and high-resource scenarios. To account for the scarcity of aliases for many target languages and terminologies, we leverage multilingual aliases via cross-lingual candidate generation. For candidate ranking, we incorporate a trainable cross-encoder (CE) model if annotations for the target task are available. To balance the output of general-purpose candidate generators with subsequent trainable re-rankers, we introduce a novel rank regularization term in the loss function for training CEs. For re-ranking without gold-standard annotations, we introduce multiple new weakly labeled datasets using machine translation and projection of annotations from a high-resource language.</p><p><strong>Results: </strong>xMEN improves the state-of-the-art performance across various benchmark datasets for several European languages. Weakly supervised CEs are effective when no training data is available for the target task.</p><p><strong>Discussion: </strong>We perform an analysis of normalization errors, revealing that complex entities are still challenging to normalize. New modules and benchmark datasets can be easily integrated in the future.</p><p><strong>Conclusion: </strong>xMEN exhibits strong performance for medical entity normalization in many languages, even when no labeled data and few terminology aliases for the target language are available. To enable reproducible benchmarks in the future, we make the system available as an open-source Python toolkit. The pre-trained models and source code are available online: https://github.com/hpi-dhc/xmen.</p>\",\"PeriodicalId\":36278,\"journal\":{\"name\":\"JAMIA Open\",\"volume\":\"8 1\",\"pages\":\"ooae147\"},\"PeriodicalIF\":3.4000,\"publicationDate\":\"2024-12-26\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC11671143/pdf/\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"JAMIA Open\",\"FirstCategoryId\":\"1085\",\"ListUrlMain\":\"https://doi.org/10.1093/jamiaopen/ooae147\",\"RegionNum\":0,\"RegionCategory\":null,\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"2025/2/1 0:00:00\",\"PubModel\":\"eCollection\",\"JCR\":\"Q2\",\"JCRName\":\"HEALTH CARE SCIENCES & SERVICES\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"JAMIA Open","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.1093/jamiaopen/ooae147","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2025/2/1 0:00:00","PubModel":"eCollection","JCR":"Q2","JCRName":"HEALTH CARE SCIENCES & SERVICES","Score":null,"Total":0}
xMEN: a modular toolkit for cross-lingual medical entity normalization.
Objective: To improve performance of medical entity normalization across many languages, especially when fewer language resources are available compared to English.
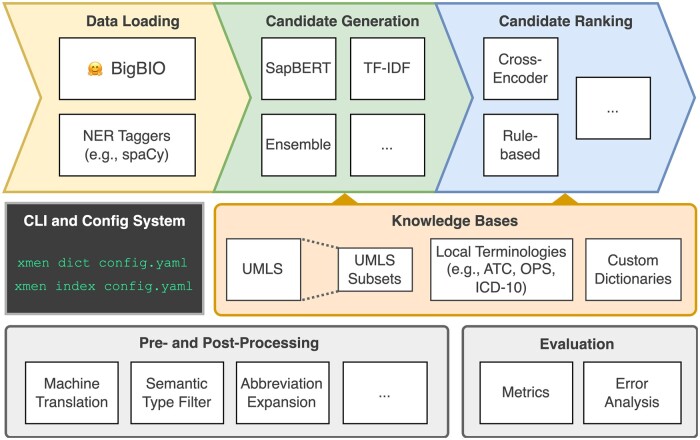
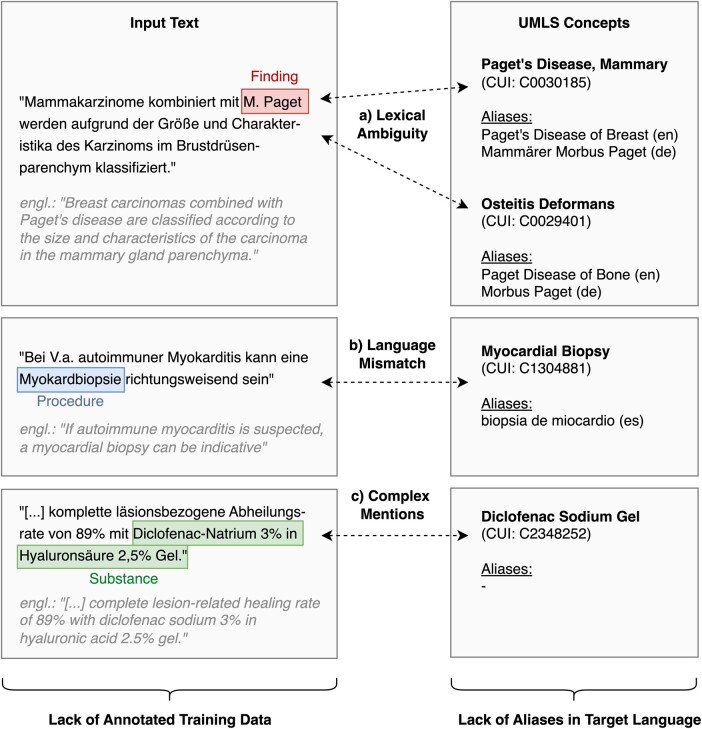
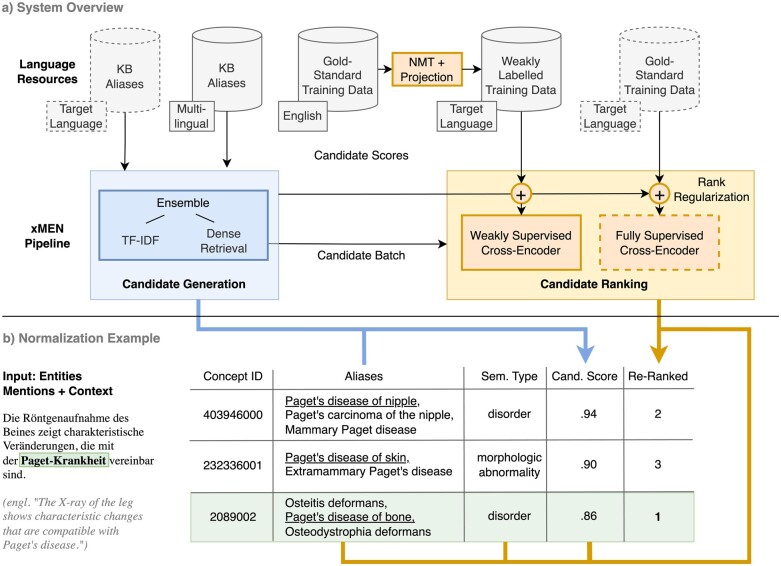
Materials and methods: We propose xMEN, a modular system for cross-lingual (x) medical entity normalization (MEN), accommodating both low- and high-resource scenarios. To account for the scarcity of aliases for many target languages and terminologies, we leverage multilingual aliases via cross-lingual candidate generation. For candidate ranking, we incorporate a trainable cross-encoder (CE) model if annotations for the target task are available. To balance the output of general-purpose candidate generators with subsequent trainable re-rankers, we introduce a novel rank regularization term in the loss function for training CEs. For re-ranking without gold-standard annotations, we introduce multiple new weakly labeled datasets using machine translation and projection of annotations from a high-resource language.
Results: xMEN improves the state-of-the-art performance across various benchmark datasets for several European languages. Weakly supervised CEs are effective when no training data is available for the target task.
Discussion: We perform an analysis of normalization errors, revealing that complex entities are still challenging to normalize. New modules and benchmark datasets can be easily integrated in the future.
Conclusion: xMEN exhibits strong performance for medical entity normalization in many languages, even when no labeled data and few terminology aliases for the target language are available. To enable reproducible benchmarks in the future, we make the system available as an open-source Python toolkit. The pre-trained models and source code are available online: https://github.com/hpi-dhc/xmen.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


