估算数字心理健康干预中机器学习预测的最小数据集大小
IF 12.4
1区 医学
Q1 HEALTH CARE SCIENCES & SERVICES
引用次数: 0
摘要
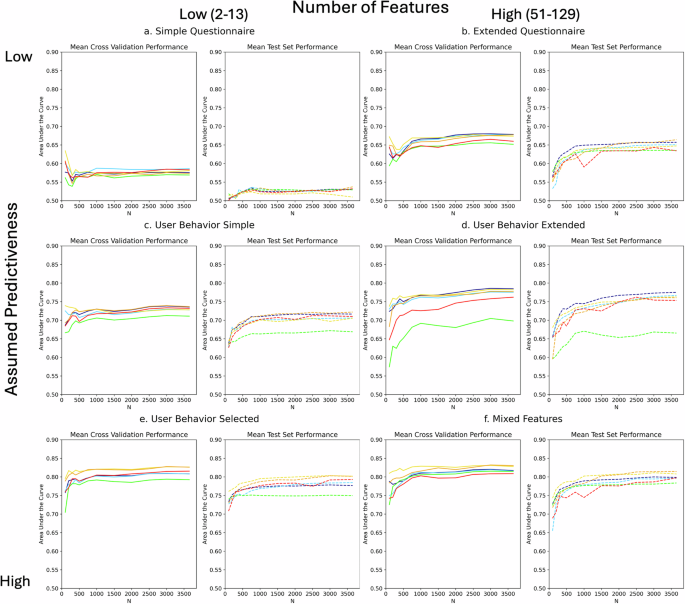
人工智能有望彻底改变心理健康护理,但数据集规模较小和缺乏稳健的方法引发了人们对结果普适性的担忧。为了深入了解最小必要数据集规模,我们基于一项研究(ISRCTN13716228,2016 年 2 月 26 日)中的 3654 名用户,探索了数字干预辍学预测的特定领域学习曲线。我们根据数据集规模(N = 100-3654)、特征组(F = 2-129)和算法选择(从奈夫贝叶到神经网络)对预测性能进行了分析。结果证实了人们的担忧,即小数据集(N ≤ 300)会高估预测能力。对于无信息特征组,样本内预测性能与数据集大小呈负相关。复杂的模型在小数据集中过度拟合,但在大数据集中却能最大限度地保持测试结果。虽然 N = 500 可以缓解过度拟合,但直到 N = 750-1500 时,性能才会收敛。因此,我们建议最小数据集大小为 N = 500-1000。因此,本研究为研究人员设计或解释数字心理健康干预数据的人工智能研究提供了经验参考。本文章由计算机程序翻译,如有差异,请以英文原文为准。

Estimation of minimal data sets sizes for machine learning predictions in digital mental health interventions
Artificial intelligence promises to revolutionize mental health care, but small dataset sizes and lack of robust methods raise concerns about result generalizability. To provide insights on minimal necessary data set sizes, we explore domain-specific learning curves for digital intervention dropout predictions based on 3654 users from a single study (ISRCTN13716228, 26/02/2016). Prediction performance is analyzed based on dataset size (N = 100–3654), feature groups (F = 2–129), and algorithm choice (from Naive Bayes to Neural Networks). The results substantiate the concern that small datasets (N ≤ 300) overestimate predictive power. For uninformative feature groups, in-sample prediction performance was negatively correlated with dataset size. Sophisticated models overfitted in small datasets but maximized holdout test results in larger datasets. While N = 500 mitigated overfitting, performance did not converge until N = 750–1500. Consequently, we propose minimum dataset sizes of N = 500–1000. As such, this study offers an empirical reference for researchers designing or interpreting AI studies on Digital Mental Health Intervention data.
求助全文
通过发布文献求助,成功后即可免费获取论文全文。
去求助
来源期刊

NPJ Digital Medicine
Multiple-
CiteScore
25.10
自引率
3.30%
发文量
170
审稿时长
15 weeks
期刊介绍:
npj Digital Medicine is an online open-access journal that focuses on publishing peer-reviewed research in the field of digital medicine. The journal covers various aspects of digital medicine, including the application and implementation of digital and mobile technologies in clinical settings, virtual healthcare, and the use of artificial intelligence and informatics.
The primary goal of the journal is to support innovation and the advancement of healthcare through the integration of new digital and mobile technologies. When determining if a manuscript is suitable for publication, the journal considers four important criteria: novelty, clinical relevance, scientific rigor, and digital innovation.
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


