Parastoo Semnani, Mihail Bogojeski, Florian Bley, Zizheng Zhang, Qiong Wu, Thomas Kneib, Jan Herrmann, Christoph Weisser, Florina Patcas, Klaus-Robert Müller
{"title":"为不平衡实验催化剂发现量身定制的机器学习和可解释的AI框架","authors":"Parastoo Semnani, Mihail Bogojeski, Florian Bley, Zizheng Zhang, Qiong Wu, Thomas Kneib, Jan Herrmann, Christoph Weisser, Florina Patcas, Klaus-Robert Müller","doi":"10.1021/acs.jpcc.4c05332","DOIUrl":null,"url":null,"abstract":"The successful application of machine learning (ML) in catalyst design has been made difficult by the challenges associated with collecting high-quality and diverse data. Due to the complex interactions between catalyst components, the design of novel catalysts has long relied on trial-and-error, a costly and labor-intensive process that results in scarce data that is heavily biased toward undesired, low-yield catalysts. Such data presents a challenge for training ML models that generalize well to novel compositions, which is necessary for the success of ML-guided catalyst discovery. Despite the growing popularity of ML applications in this field, most efforts so far have not focused on dealing with the challenges presented by such experimental data. In this work, we introduce a robust ML and explainable artificial intelligence (XAI) framework that incorporates a series of well-established ML methods designed to improve model performance and provide reliable evaluations for catalytic yield classification in the context of scarce and class-imbalanced data. We apply this framework to classify the yields of different catalyst combinations in the oxidative coupling of methane reaction and use it to evaluate the performance of a range of ML models: tree-based models (such as decision trees, random forest, and gradient boosted trees), logistic regression, support vector machines, and neural networks. Our experiments demonstrate that the methods used in our framework lead to more robust performance estimates and reduce the effect of class imbalance on model training, resulting in significant improvements in the predictive capability of all but one of the evaluated models. Additionally, the XAI component of the framework analyzes the decision-making process of each ML model by identifying the most important features for predicting catalyst performance. Our analysis found that XAI methods that provide class-aware explanations, such as Layer-wise Relevance Propagation, managed to identify key components that contribute specifically to high-yield catalysts. These findings align with chemical intuition and existing literature, reinforcing their validity. We believe this framework can serve as a blueprint and a set of best practices for ML applications in catalysis, driving future research while delivering robust models and actionable insights that can assist chemists in designing and discovering novel catalysts with superior performance.","PeriodicalId":61,"journal":{"name":"The Journal of Physical Chemistry C","volume":"8 1","pages":""},"PeriodicalIF":3.2000,"publicationDate":"2024-12-06","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":"{\"title\":\"A Machine Learning and Explainable AI Framework Tailored for Unbalanced Experimental Catalyst Discovery\",\"authors\":\"Parastoo Semnani, Mihail Bogojeski, Florian Bley, Zizheng Zhang, Qiong Wu, Thomas Kneib, Jan Herrmann, Christoph Weisser, Florina Patcas, Klaus-Robert Müller\",\"doi\":\"10.1021/acs.jpcc.4c05332\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"The successful application of machine learning (ML) in catalyst design has been made difficult by the challenges associated with collecting high-quality and diverse data. Due to the complex interactions between catalyst components, the design of novel catalysts has long relied on trial-and-error, a costly and labor-intensive process that results in scarce data that is heavily biased toward undesired, low-yield catalysts. Such data presents a challenge for training ML models that generalize well to novel compositions, which is necessary for the success of ML-guided catalyst discovery. Despite the growing popularity of ML applications in this field, most efforts so far have not focused on dealing with the challenges presented by such experimental data. In this work, we introduce a robust ML and explainable artificial intelligence (XAI) framework that incorporates a series of well-established ML methods designed to improve model performance and provide reliable evaluations for catalytic yield classification in the context of scarce and class-imbalanced data. We apply this framework to classify the yields of different catalyst combinations in the oxidative coupling of methane reaction and use it to evaluate the performance of a range of ML models: tree-based models (such as decision trees, random forest, and gradient boosted trees), logistic regression, support vector machines, and neural networks. Our experiments demonstrate that the methods used in our framework lead to more robust performance estimates and reduce the effect of class imbalance on model training, resulting in significant improvements in the predictive capability of all but one of the evaluated models. Additionally, the XAI component of the framework analyzes the decision-making process of each ML model by identifying the most important features for predicting catalyst performance. Our analysis found that XAI methods that provide class-aware explanations, such as Layer-wise Relevance Propagation, managed to identify key components that contribute specifically to high-yield catalysts. These findings align with chemical intuition and existing literature, reinforcing their validity. We believe this framework can serve as a blueprint and a set of best practices for ML applications in catalysis, driving future research while delivering robust models and actionable insights that can assist chemists in designing and discovering novel catalysts with superior performance.\",\"PeriodicalId\":61,\"journal\":{\"name\":\"The Journal of Physical Chemistry C\",\"volume\":\"8 1\",\"pages\":\"\"},\"PeriodicalIF\":3.2000,\"publicationDate\":\"2024-12-06\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"The Journal of Physical Chemistry C\",\"FirstCategoryId\":\"1\",\"ListUrlMain\":\"https://doi.org/10.1021/acs.jpcc.4c05332\",\"RegionNum\":3,\"RegionCategory\":\"化学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q2\",\"JCRName\":\"CHEMISTRY, PHYSICAL\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"The Journal of Physical Chemistry C","FirstCategoryId":"1","ListUrlMain":"https://doi.org/10.1021/acs.jpcc.4c05332","RegionNum":3,"RegionCategory":"化学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q2","JCRName":"CHEMISTRY, PHYSICAL","Score":null,"Total":0}
A Machine Learning and Explainable AI Framework Tailored for Unbalanced Experimental Catalyst Discovery
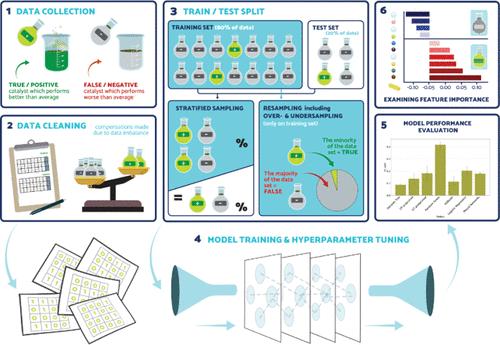
The successful application of machine learning (ML) in catalyst design has been made difficult by the challenges associated with collecting high-quality and diverse data. Due to the complex interactions between catalyst components, the design of novel catalysts has long relied on trial-and-error, a costly and labor-intensive process that results in scarce data that is heavily biased toward undesired, low-yield catalysts. Such data presents a challenge for training ML models that generalize well to novel compositions, which is necessary for the success of ML-guided catalyst discovery. Despite the growing popularity of ML applications in this field, most efforts so far have not focused on dealing with the challenges presented by such experimental data. In this work, we introduce a robust ML and explainable artificial intelligence (XAI) framework that incorporates a series of well-established ML methods designed to improve model performance and provide reliable evaluations for catalytic yield classification in the context of scarce and class-imbalanced data. We apply this framework to classify the yields of different catalyst combinations in the oxidative coupling of methane reaction and use it to evaluate the performance of a range of ML models: tree-based models (such as decision trees, random forest, and gradient boosted trees), logistic regression, support vector machines, and neural networks. Our experiments demonstrate that the methods used in our framework lead to more robust performance estimates and reduce the effect of class imbalance on model training, resulting in significant improvements in the predictive capability of all but one of the evaluated models. Additionally, the XAI component of the framework analyzes the decision-making process of each ML model by identifying the most important features for predicting catalyst performance. Our analysis found that XAI methods that provide class-aware explanations, such as Layer-wise Relevance Propagation, managed to identify key components that contribute specifically to high-yield catalysts. These findings align with chemical intuition and existing literature, reinforcing their validity. We believe this framework can serve as a blueprint and a set of best practices for ML applications in catalysis, driving future research while delivering robust models and actionable insights that can assist chemists in designing and discovering novel catalysts with superior performance.
期刊介绍:
The Journal of Physical Chemistry A/B/C is devoted to reporting new and original experimental and theoretical basic research of interest to physical chemists, biophysical chemists, and chemical physicists.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


