用于口吃检测和分类的机器学习算法的评估比较
IF 1.9
Q2 MULTIDISCIPLINARY SCIENCES
引用次数: 0
摘要
口吃是一种神经发育性语言障碍,由于不自主的停顿和声音重复而导致说话中断。口吃对心理有深远影响,会影响社会交往和职业发展。自动检测语音记录中的口吃事件可以帮助语言治疗师或语言病理学家跟踪口吃患者(PWS)的流利程度。它还有助于改进现有的口吃患者语音识别系统。本文利用 SEP-28k 数据集进行比较分析,以评估各种机器学习模型在对五种流畅性障碍类型(即延时、插话、词语重复、声音重复和块状)进行分类时的性能。-这项研究的重点是自动检测语音记录中的口吃事件,为语音治疗师提供支持,并改进口吃患者(PWS)的语音识别系统。本文章由计算机程序翻译,如有差异,请以英文原文为准。
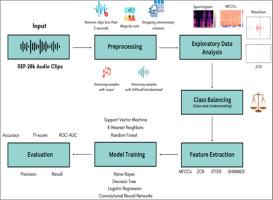
Evaluative comparison of machine learning algorithms for stutter detection and classification
Stuttering is a neuro-developmental speech disorder that interrupts the flow of speech due to involuntary pauses and sound repetitions. It has profound psychological impacts that affect social interactions and professional advancements. Automatically detecting stuttering events in speech recordings could assist speech therapists or speech pathologists track the fluency of people who stutter (PWS). It will also assist in the improvement of the existing speech recognition system for PWS. In this paper, the SEP-28k dataset is utilized to perform comparative analysis to assess the performance of various machine learning models in classifying the five dysfluency types namely Prolongation, Interjection, Word Repetition, Sound Repetition and Blocks.
- •The study focuses on automatically detecting stuttering events in speech recordings to support speech therapists and improve speech recognition systems for people who stutter (PWS).
- •The SEP-28k dataset is used to perform a comparative analysis of different machine learning models.
- •The research examines the impact of key acoustic features on model accuracy while addressing challenges such as class imbalance.
求助全文
通过发布文献求助,成功后即可免费获取论文全文。
去求助
来源期刊

MethodsX
Health Professions-Medical Laboratory Technology
CiteScore
3.60
自引率
5.30%
发文量
314
审稿时长
7 weeks
期刊介绍:
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


