{"title":"基于聚类集合学习的软件缺陷预测方法","authors":"Hongwei Tao, Qiaoling Cao, Haoran Chen, Yanting Li, Xiaoxu Niu, Tao Wang, Zhenhao Geng, Songtao Shang","doi":"10.1049/2024/6294422","DOIUrl":null,"url":null,"abstract":"<p>The technique of software defect prediction aims to assess and predict potential defects in software projects and has made significant progress in recent years within software development. In previous studies, this technique largely relied on supervised learning methods, requiring a substantial amount of labeled historical defect data to train the models. However, obtaining these labeled data often demands significant time and resources. In contrast, software defect prediction based on unsupervised learning does not depend on known labeled data, eliminating the need for large-scale data labeling, thereby saving considerable time and resources while providing a more flexible solution for ensuring software quality. This paper conducts software defect prediction using unsupervised learning methods on data from 16 projects across two public datasets (PROMISE and NASA). During the feature selection step, a chi-squared sparse feature selection method is proposed. This feature selection strategy combines chi-squared tests with sparse principal component analysis (SPCA). Specifically, the chi-squared test is first used to filter out the most statistically significant features, and then the SPCA is applied to reduce the dimensionality of these significant features. In the clustering step, the dot product matrix and Pearson correlation coefficient (PCC) matrix are used to construct weighted adjacency matrices, and a clustering overlap method is proposed. This method integrates spectral clustering, Newman clustering, fluid clustering, and Clauset–Newman–Moore (CNM) clustering through ensemble learning. Experimental results indicate that, in the absence of labeled data, using the chi-squared sparse method for feature selection demonstrates superior performance, and the proposed clustering overlap method outperforms or is comparable to the effectiveness of the four baseline clustering methods.</p>","PeriodicalId":50378,"journal":{"name":"IET Software","volume":"2024 1","pages":""},"PeriodicalIF":1.3000,"publicationDate":"2024-11-19","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://onlinelibrary.wiley.com/doi/epdf/10.1049/2024/6294422","citationCount":"0","resultStr":"{\"title\":\"Software Defect Prediction Method Based on Clustering Ensemble Learning\",\"authors\":\"Hongwei Tao, Qiaoling Cao, Haoran Chen, Yanting Li, Xiaoxu Niu, Tao Wang, Zhenhao Geng, Songtao Shang\",\"doi\":\"10.1049/2024/6294422\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p>The technique of software defect prediction aims to assess and predict potential defects in software projects and has made significant progress in recent years within software development. In previous studies, this technique largely relied on supervised learning methods, requiring a substantial amount of labeled historical defect data to train the models. However, obtaining these labeled data often demands significant time and resources. In contrast, software defect prediction based on unsupervised learning does not depend on known labeled data, eliminating the need for large-scale data labeling, thereby saving considerable time and resources while providing a more flexible solution for ensuring software quality. This paper conducts software defect prediction using unsupervised learning methods on data from 16 projects across two public datasets (PROMISE and NASA). During the feature selection step, a chi-squared sparse feature selection method is proposed. This feature selection strategy combines chi-squared tests with sparse principal component analysis (SPCA). Specifically, the chi-squared test is first used to filter out the most statistically significant features, and then the SPCA is applied to reduce the dimensionality of these significant features. In the clustering step, the dot product matrix and Pearson correlation coefficient (PCC) matrix are used to construct weighted adjacency matrices, and a clustering overlap method is proposed. This method integrates spectral clustering, Newman clustering, fluid clustering, and Clauset–Newman–Moore (CNM) clustering through ensemble learning. Experimental results indicate that, in the absence of labeled data, using the chi-squared sparse method for feature selection demonstrates superior performance, and the proposed clustering overlap method outperforms or is comparable to the effectiveness of the four baseline clustering methods.</p>\",\"PeriodicalId\":50378,\"journal\":{\"name\":\"IET Software\",\"volume\":\"2024 1\",\"pages\":\"\"},\"PeriodicalIF\":1.3000,\"publicationDate\":\"2024-11-19\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://onlinelibrary.wiley.com/doi/epdf/10.1049/2024/6294422\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"IET Software\",\"FirstCategoryId\":\"94\",\"ListUrlMain\":\"https://ietresearch.onlinelibrary.wiley.com/doi/10.1049/2024/6294422\",\"RegionNum\":4,\"RegionCategory\":\"计算机科学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q3\",\"JCRName\":\"COMPUTER SCIENCE, SOFTWARE ENGINEERING\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"IET Software","FirstCategoryId":"94","ListUrlMain":"https://ietresearch.onlinelibrary.wiley.com/doi/10.1049/2024/6294422","RegionNum":4,"RegionCategory":"计算机科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q3","JCRName":"COMPUTER SCIENCE, SOFTWARE ENGINEERING","Score":null,"Total":0}
Software Defect Prediction Method Based on Clustering Ensemble Learning
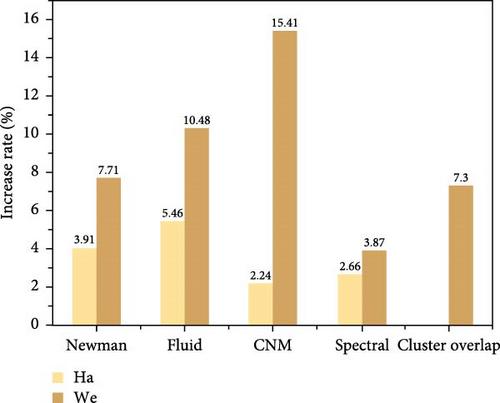
The technique of software defect prediction aims to assess and predict potential defects in software projects and has made significant progress in recent years within software development. In previous studies, this technique largely relied on supervised learning methods, requiring a substantial amount of labeled historical defect data to train the models. However, obtaining these labeled data often demands significant time and resources. In contrast, software defect prediction based on unsupervised learning does not depend on known labeled data, eliminating the need for large-scale data labeling, thereby saving considerable time and resources while providing a more flexible solution for ensuring software quality. This paper conducts software defect prediction using unsupervised learning methods on data from 16 projects across two public datasets (PROMISE and NASA). During the feature selection step, a chi-squared sparse feature selection method is proposed. This feature selection strategy combines chi-squared tests with sparse principal component analysis (SPCA). Specifically, the chi-squared test is first used to filter out the most statistically significant features, and then the SPCA is applied to reduce the dimensionality of these significant features. In the clustering step, the dot product matrix and Pearson correlation coefficient (PCC) matrix are used to construct weighted adjacency matrices, and a clustering overlap method is proposed. This method integrates spectral clustering, Newman clustering, fluid clustering, and Clauset–Newman–Moore (CNM) clustering through ensemble learning. Experimental results indicate that, in the absence of labeled data, using the chi-squared sparse method for feature selection demonstrates superior performance, and the proposed clustering overlap method outperforms or is comparable to the effectiveness of the four baseline clustering methods.
期刊介绍:
IET Software publishes papers on all aspects of the software lifecycle, including design, development, implementation and maintenance. The focus of the journal is on the methods used to develop and maintain software, and their practical application.
Authors are especially encouraged to submit papers on the following topics, although papers on all aspects of software engineering are welcome:
Software and systems requirements engineering
Formal methods, design methods, practice and experience
Software architecture, aspect and object orientation, reuse and re-engineering
Testing, verification and validation techniques
Software dependability and measurement
Human systems engineering and human-computer interaction
Knowledge engineering; expert and knowledge-based systems, intelligent agents
Information systems engineering
Application of software engineering in industry and commerce
Software engineering technology transfer
Management of software development
Theoretical aspects of software development
Machine learning
Big data and big code
Cloud computing
Current Special Issue. Call for papers:
Knowledge Discovery for Software Development - https://digital-library.theiet.org/files/IET_SEN_CFP_KDSD.pdf
Big Data Analytics for Sustainable Software Development - https://digital-library.theiet.org/files/IET_SEN_CFP_BDASSD.pdf


 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


