Zhilin Li, Lei Lei, Gaoqing Shen, Xiaochang Liu, Xiaojiao Liu
{"title":"无人机群安全保障成群运动的数字孪生深度强化学习","authors":"Zhilin Li, Lei Lei, Gaoqing Shen, Xiaochang Liu, Xiaojiao Liu","doi":"10.1002/ett.70011","DOIUrl":null,"url":null,"abstract":"<div>\n \n <p>Multi-agent deep reinforcement learning (MADRL) has become a typical paradigm for the flocking motion of UAV swarm in dynamic, stochastic environments. However, sim-to-real problems, such as reality gap, training efficiency, and safety issues, restrict the application of MADRL in flocking motion scenarios. To address these problems, we first propose a digital twin (DT)-enabled training framework. With the assistance of high-fidelity digital twin simulation, effective policies can be efficiently trained. Based on the multi-agent proximal policy optimization (MAPPO) algorithm, we then design the learning approach for flocking motion with matching observation space, action space, and reward function. Afterward, we employ a distributed flocking center estimation algorithm based on position consensus. The estimated center is used as a policy input to improve the aggregation behavior. Moreover, we introduce a repulsion scheme, which applies an additional repulsion force to the action to prevent UAVs from colliding with neighbors and obstacles. Simulation results show that our method performs well in maintaining flocking formation and avoiding collisions, and has better decision-making ability in near-realistic environments.</p>\n </div>","PeriodicalId":23282,"journal":{"name":"Transactions on Emerging Telecommunications Technologies","volume":"35 11","pages":""},"PeriodicalIF":2.5000,"publicationDate":"2024-11-06","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":"{\"title\":\"Digital Twin-Enabled Deep Reinforcement Learning for Safety-Guaranteed Flocking Motion of UAV Swarm\",\"authors\":\"Zhilin Li, Lei Lei, Gaoqing Shen, Xiaochang Liu, Xiaojiao Liu\",\"doi\":\"10.1002/ett.70011\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<div>\\n \\n <p>Multi-agent deep reinforcement learning (MADRL) has become a typical paradigm for the flocking motion of UAV swarm in dynamic, stochastic environments. However, sim-to-real problems, such as reality gap, training efficiency, and safety issues, restrict the application of MADRL in flocking motion scenarios. To address these problems, we first propose a digital twin (DT)-enabled training framework. With the assistance of high-fidelity digital twin simulation, effective policies can be efficiently trained. Based on the multi-agent proximal policy optimization (MAPPO) algorithm, we then design the learning approach for flocking motion with matching observation space, action space, and reward function. Afterward, we employ a distributed flocking center estimation algorithm based on position consensus. The estimated center is used as a policy input to improve the aggregation behavior. Moreover, we introduce a repulsion scheme, which applies an additional repulsion force to the action to prevent UAVs from colliding with neighbors and obstacles. Simulation results show that our method performs well in maintaining flocking formation and avoiding collisions, and has better decision-making ability in near-realistic environments.</p>\\n </div>\",\"PeriodicalId\":23282,\"journal\":{\"name\":\"Transactions on Emerging Telecommunications Technologies\",\"volume\":\"35 11\",\"pages\":\"\"},\"PeriodicalIF\":2.5000,\"publicationDate\":\"2024-11-06\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Transactions on Emerging Telecommunications Technologies\",\"FirstCategoryId\":\"94\",\"ListUrlMain\":\"https://onlinelibrary.wiley.com/doi/10.1002/ett.70011\",\"RegionNum\":4,\"RegionCategory\":\"计算机科学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q3\",\"JCRName\":\"TELECOMMUNICATIONS\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Transactions on Emerging Telecommunications Technologies","FirstCategoryId":"94","ListUrlMain":"https://onlinelibrary.wiley.com/doi/10.1002/ett.70011","RegionNum":4,"RegionCategory":"计算机科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q3","JCRName":"TELECOMMUNICATIONS","Score":null,"Total":0}
Digital Twin-Enabled Deep Reinforcement Learning for Safety-Guaranteed Flocking Motion of UAV Swarm
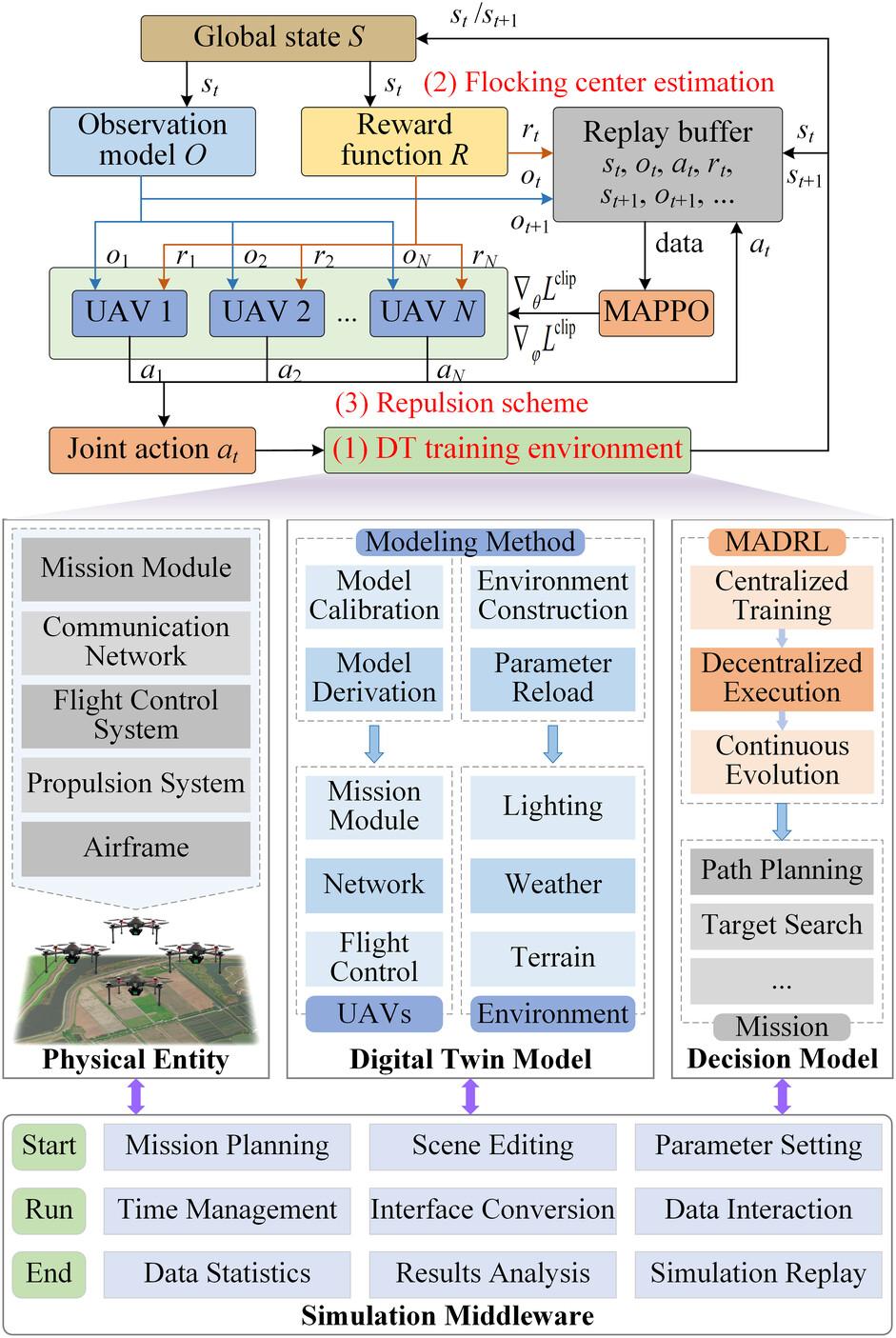
Multi-agent deep reinforcement learning (MADRL) has become a typical paradigm for the flocking motion of UAV swarm in dynamic, stochastic environments. However, sim-to-real problems, such as reality gap, training efficiency, and safety issues, restrict the application of MADRL in flocking motion scenarios. To address these problems, we first propose a digital twin (DT)-enabled training framework. With the assistance of high-fidelity digital twin simulation, effective policies can be efficiently trained. Based on the multi-agent proximal policy optimization (MAPPO) algorithm, we then design the learning approach for flocking motion with matching observation space, action space, and reward function. Afterward, we employ a distributed flocking center estimation algorithm based on position consensus. The estimated center is used as a policy input to improve the aggregation behavior. Moreover, we introduce a repulsion scheme, which applies an additional repulsion force to the action to prevent UAVs from colliding with neighbors and obstacles. Simulation results show that our method performs well in maintaining flocking formation and avoiding collisions, and has better decision-making ability in near-realistic environments.
期刊介绍:
ransactions on Emerging Telecommunications Technologies (ETT), formerly known as European Transactions on Telecommunications (ETT), has the following aims:
- to attract cutting-edge publications from leading researchers and research groups around the world
- to become a highly cited source of timely research findings in emerging fields of telecommunications
- to limit revision and publication cycles to a few months and thus significantly increase attractiveness to publish
- to become the leading journal for publishing the latest developments in telecommunications

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


