{"title":"Pred-AHCP:通过机器学习对抗丙型肝炎肽的序列特异性进行稳健的特征选择预测。","authors":"Akash Saraswat, Utsav Sharma, Aryan Gandotra, Lakshit Wasan, Sainithin Artham, Arijit Maitra, Bipin Singh","doi":"10.1021/acs.jcim.4c00900","DOIUrl":null,"url":null,"abstract":"<p><p>Every year, an estimated 1.5 million people worldwide contract Hepatitis C, a significant contributor to liver problems. Although many studies have explored machine learning's potential to predict antiviral peptides, very few have addressed the problem of predicting peptides against specific viruses such as Hepatitis C. In this study, we demonstrate the application and fine-tuning of machine learning (ML) algorithms to predict peptides that are effective against Hepatitis C virus (HCV). We developed a fine-tuned and explainable ML model that harnesses the amino acid sequence of a peptide to predict its anti-hepatitis C potential. Specifically, features were computed based on sequence and physicochemical properties. The feature selection was performed using a combined strategy of mutual information and variance inflation factor. This facilitated the removal of redundant and multicollinear features, enhancing the model's generalizability in predicting anti-hepatitis C peptides (AHCPs). The model using the random forest algorithm produced the best performance with an accuracy of about 92%. The feature analysis highlights that the distributions of hydrophobicity, polarizability, coil-forming residues, frequency of glycine residues and the existence of dipeptide motifs VL, LV, and CC emerged as the key predictors for identifying AHCPs targeting different components of HCV. The developed model can be accessed through the Pred-AHCP web server, provided at http://tinyurl.com/web-Pred-AHCP. This resource facilitates the prediction and re-engineering of AHCPs for designing peptide-based therapeutics while also proposing an exploration of similar strategies for designing peptide inhibitors effective against other viruses. The developed ML model can also be used for validating peptide sequences generated using generative artificial intelligence methods for further optimization.</p>","PeriodicalId":44,"journal":{"name":"Journal of Chemical Information and Modeling ","volume":" ","pages":"9111-9124"},"PeriodicalIF":5.3000,"publicationDate":"2024-12-23","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":"{\"title\":\"Pred-AHCP: Robust Feature Selection-Enabled Sequence-Specific Prediction of Anti-Hepatitis C Peptides via Machine Learning.\",\"authors\":\"Akash Saraswat, Utsav Sharma, Aryan Gandotra, Lakshit Wasan, Sainithin Artham, Arijit Maitra, Bipin Singh\",\"doi\":\"10.1021/acs.jcim.4c00900\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><p>Every year, an estimated 1.5 million people worldwide contract Hepatitis C, a significant contributor to liver problems. Although many studies have explored machine learning's potential to predict antiviral peptides, very few have addressed the problem of predicting peptides against specific viruses such as Hepatitis C. In this study, we demonstrate the application and fine-tuning of machine learning (ML) algorithms to predict peptides that are effective against Hepatitis C virus (HCV). We developed a fine-tuned and explainable ML model that harnesses the amino acid sequence of a peptide to predict its anti-hepatitis C potential. Specifically, features were computed based on sequence and physicochemical properties. The feature selection was performed using a combined strategy of mutual information and variance inflation factor. This facilitated the removal of redundant and multicollinear features, enhancing the model's generalizability in predicting anti-hepatitis C peptides (AHCPs). The model using the random forest algorithm produced the best performance with an accuracy of about 92%. The feature analysis highlights that the distributions of hydrophobicity, polarizability, coil-forming residues, frequency of glycine residues and the existence of dipeptide motifs VL, LV, and CC emerged as the key predictors for identifying AHCPs targeting different components of HCV. The developed model can be accessed through the Pred-AHCP web server, provided at http://tinyurl.com/web-Pred-AHCP. This resource facilitates the prediction and re-engineering of AHCPs for designing peptide-based therapeutics while also proposing an exploration of similar strategies for designing peptide inhibitors effective against other viruses. The developed ML model can also be used for validating peptide sequences generated using generative artificial intelligence methods for further optimization.</p>\",\"PeriodicalId\":44,\"journal\":{\"name\":\"Journal of Chemical Information and Modeling \",\"volume\":\" \",\"pages\":\"9111-9124\"},\"PeriodicalIF\":5.3000,\"publicationDate\":\"2024-12-23\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Journal of Chemical Information and Modeling \",\"FirstCategoryId\":\"92\",\"ListUrlMain\":\"https://doi.org/10.1021/acs.jcim.4c00900\",\"RegionNum\":2,\"RegionCategory\":\"化学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"2024/11/6 0:00:00\",\"PubModel\":\"Epub\",\"JCR\":\"Q1\",\"JCRName\":\"CHEMISTRY, MEDICINAL\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Journal of Chemical Information and Modeling ","FirstCategoryId":"92","ListUrlMain":"https://doi.org/10.1021/acs.jcim.4c00900","RegionNum":2,"RegionCategory":"化学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2024/11/6 0:00:00","PubModel":"Epub","JCR":"Q1","JCRName":"CHEMISTRY, MEDICINAL","Score":null,"Total":0}
引用次数: 0
摘要
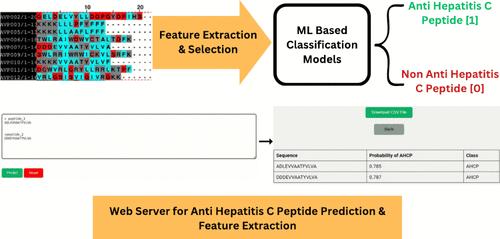
每年,全球估计有 150 万人感染丙型肝炎,这是导致肝脏问题的一个重要因素。虽然许多研究都探索了机器学习预测抗病毒多肽的潜力,但很少有人解决预测抗丙型肝炎等特定病毒的多肽的问题。我们开发了一种微调且可解释的 ML 模型,利用多肽的氨基酸序列来预测其抗丙型肝炎的潜力。具体来说,特征是根据序列和理化性质计算出来的。特征选择采用互信息和方差膨胀因子相结合的策略。这有助于去除冗余和多共线性特征,提高模型在预测抗丙型肝炎肽(AHCPs)方面的通用性。使用随机森林算法的模型性能最佳,准确率约为 92%。特征分析表明,疏水性、极化性、线圈形成残基的分布、甘氨酸残基的频率以及二肽基序 VL、LV 和 CC 的存在是识别针对 HCV 不同成分的 AHCP 的关键预测因子。开发的模型可通过 http://tinyurl.com/web-Pred-AHCP 上的 Pred-AHCP 网络服务器访问。该资源有助于预测和重新设计 AHCPs,以设计基于多肽的疗法,同时还建议探索类似的策略,以设计对其他病毒有效的多肽抑制剂。开发的 ML 模型还可用于验证使用生成式人工智能方法生成的多肽序列,以便进一步优化。
Pred-AHCP: Robust Feature Selection-Enabled Sequence-Specific Prediction of Anti-Hepatitis C Peptides via Machine Learning.
Every year, an estimated 1.5 million people worldwide contract Hepatitis C, a significant contributor to liver problems. Although many studies have explored machine learning's potential to predict antiviral peptides, very few have addressed the problem of predicting peptides against specific viruses such as Hepatitis C. In this study, we demonstrate the application and fine-tuning of machine learning (ML) algorithms to predict peptides that are effective against Hepatitis C virus (HCV). We developed a fine-tuned and explainable ML model that harnesses the amino acid sequence of a peptide to predict its anti-hepatitis C potential. Specifically, features were computed based on sequence and physicochemical properties. The feature selection was performed using a combined strategy of mutual information and variance inflation factor. This facilitated the removal of redundant and multicollinear features, enhancing the model's generalizability in predicting anti-hepatitis C peptides (AHCPs). The model using the random forest algorithm produced the best performance with an accuracy of about 92%. The feature analysis highlights that the distributions of hydrophobicity, polarizability, coil-forming residues, frequency of glycine residues and the existence of dipeptide motifs VL, LV, and CC emerged as the key predictors for identifying AHCPs targeting different components of HCV. The developed model can be accessed through the Pred-AHCP web server, provided at http://tinyurl.com/web-Pred-AHCP. This resource facilitates the prediction and re-engineering of AHCPs for designing peptide-based therapeutics while also proposing an exploration of similar strategies for designing peptide inhibitors effective against other viruses. The developed ML model can also be used for validating peptide sequences generated using generative artificial intelligence methods for further optimization.
期刊介绍:
The Journal of Chemical Information and Modeling publishes papers reporting new methodology and/or important applications in the fields of chemical informatics and molecular modeling. Specific topics include the representation and computer-based searching of chemical databases, molecular modeling, computer-aided molecular design of new materials, catalysts, or ligands, development of new computational methods or efficient algorithms for chemical software, and biopharmaceutical chemistry including analyses of biological activity and other issues related to drug discovery.
Astute chemists, computer scientists, and information specialists look to this monthly’s insightful research studies, programming innovations, and software reviews to keep current with advances in this integral, multidisciplinary field.
As a subscriber you’ll stay abreast of database search systems, use of graph theory in chemical problems, substructure search systems, pattern recognition and clustering, analysis of chemical and physical data, molecular modeling, graphics and natural language interfaces, bibliometric and citation analysis, and synthesis design and reactions databases.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


