将关系作为已知条件基于标记的关系三提取方法
IF 3.4
3区 计算机科学
Q2 COMPUTER SCIENCE, ARTIFICIAL INTELLIGENCE
引用次数: 0
摘要
关系三元提取是指从自然文本中提取实体和关系,这是构建知识图谱的一项重要任务。近年来,基于标记的方法因其简单有效的结构形式而受到越来越多的关注。其中,两步提取法容易造成类别不平衡的问题。针对这一问题,我们提出了一种新颖的两步提取法,即首先提取主体,为每种关系生成固定大小的嵌入,然后将这些关系视为已知条件,直接提取与所识别主体相关的对象。为了在预测对象时消除无关关系的影响,我们使用了关系特别关注机制和门单元来选择适当的关系。此外,目前大多数模型都没有考虑到任务之间的双向交互,因此我们设计了一个特征交互网络,以实现主体和对象提取任务之间的双向交互,增强它们之间的联系。在 NYT、WebNLG、NYT⋆ 和 WebNLG⋆ 数据集上的实验结果表明,我们的模型在联合提取模型中具有竞争力。本文章由计算机程序翻译,如有差异,请以英文原文为准。
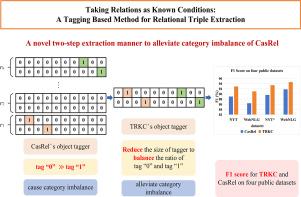
Taking relations as known conditions: A tagging based method for relational triple extraction
Relational triple extraction refers to extracting entities and relations from natural texts, which is a crucial task in the construction of knowledge graph. Recently, tagging based methods have received increasing attention because of their simple and effective structural form. Among them, the two-step extraction method is easy to cause the problem of category imbalance. To address this issue, we propose a novel two-step extraction method, which first extracts subjects, generates a fixed-size embedding for each relation, and then regards these relations as known conditions to extract the objects directly with the identified subjects. In order to eliminate the influence of irrelevant relations when predicting objects, we use a relation-special attention mechanism and a gate unit to select appropriate relations. In addition, most current models do not account for two-way interaction between tasks, so we design a feature interactive network to achieve bidirectional interaction between subject and object extraction tasks and enhance their connection. Experimental results on NYT, WebNLG, NYT and WebNLG datasets show that our model is competitive among joint extraction models.
求助全文
通过发布文献求助,成功后即可免费获取论文全文。
去求助
来源期刊

Computer Speech and Language
工程技术-计算机:人工智能
CiteScore
11.30
自引率
4.70%
发文量
80
审稿时长
22.9 weeks
期刊介绍:
Computer Speech & Language publishes reports of original research related to the recognition, understanding, production, coding and mining of speech and language.
The speech and language sciences have a long history, but it is only relatively recently that large-scale implementation of and experimentation with complex models of speech and language processing has become feasible. Such research is often carried out somewhat separately by practitioners of artificial intelligence, computer science, electronic engineering, information retrieval, linguistics, phonetics, or psychology.
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


