{"title":"苏丹新生儿和产妇住院异质性建模:伽马分布非参数随机效应模型。","authors":"Amani Almohaimeed, Ishag Adam","doi":"10.1186/s13040-024-00403-y","DOIUrl":null,"url":null,"abstract":"<p><strong>Objective: </strong>Studies looking into patient and institutional variables linked to extended hospital stays have arisen as a result of the increased focus on severe maternal morbidity and mortality. Understanding the length of hospitalization of patients after delivery is important to gain insights into when hospitals will reach capacity and to predict corresponding staffing or equipment requirements. In Sudan, the distribution of the length of stay during delivery hospitalizations is heavily skewed, with the average length of stay of 2 to 3 days. This study aimed to investigate the use of non-parametric random effect model with Gamma distributed response for analyzing skewed hospital length of stay data in Sudan in neonatal and maternal unit.</p><p><strong>Methods: </strong>We applied Gamma regression models with unknown random effects, estimated using the non-parametric maximum likelihood (NPML) technique [5]. The NPML reduces the heterogeneity in the distribution of the response and produce a robust estimation since it does not require any assumptions on the distribution. The same applies to the log-Gamma link that does not require any transformation for the data distribution and it can handle the outliers in the data points. In this study, the models are fitted with and without covariates and compared using AIC and BIC values.</p><p><strong>Results: </strong>The findings imply that in the context of health care database investigations, Gamma regression models with non-parametric random effect consistently reduce heterogeneity and improve model accuracy. The generalized linear model with covariates and random effect (k = 4) had the best fit, indicating that Sudanese hospital length of stay data could be classified into four groups with varying average stays influenced by maternal, neonatal, and obstetrics data.</p><p><strong>Conclusion: </strong>Identifying factors contributing to longer stays allows hospitals to implement strategies for improvement. Non-parametric random effect model with Gamma distributed response effectively accounts for unobserved heterogeneity and individual-level variability, leading to more accurate inferences and improved patient care. Including random effects can significantly affect variable significance in statistical models, emphasizing the need to consider unobserved heterogeneity when analyzing data containing potential individual-level variability. The findings emphasise the importance of making robust methodological choices in healthcare research in order to inform accurate policy decisions.</p>","PeriodicalId":48947,"journal":{"name":"Biodata Mining","volume":"17 1","pages":"47"},"PeriodicalIF":6.1000,"publicationDate":"2024-11-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC11529257/pdf/","citationCount":"0","resultStr":"{\"title\":\"Modeling heterogeneity of Sudanese hospital stay in neonatal and maternal unit: non-parametric random effect models with Gamma distribution.\",\"authors\":\"Amani Almohaimeed, Ishag Adam\",\"doi\":\"10.1186/s13040-024-00403-y\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><strong>Objective: </strong>Studies looking into patient and institutional variables linked to extended hospital stays have arisen as a result of the increased focus on severe maternal morbidity and mortality. Understanding the length of hospitalization of patients after delivery is important to gain insights into when hospitals will reach capacity and to predict corresponding staffing or equipment requirements. In Sudan, the distribution of the length of stay during delivery hospitalizations is heavily skewed, with the average length of stay of 2 to 3 days. This study aimed to investigate the use of non-parametric random effect model with Gamma distributed response for analyzing skewed hospital length of stay data in Sudan in neonatal and maternal unit.</p><p><strong>Methods: </strong>We applied Gamma regression models with unknown random effects, estimated using the non-parametric maximum likelihood (NPML) technique [5]. The NPML reduces the heterogeneity in the distribution of the response and produce a robust estimation since it does not require any assumptions on the distribution. The same applies to the log-Gamma link that does not require any transformation for the data distribution and it can handle the outliers in the data points. In this study, the models are fitted with and without covariates and compared using AIC and BIC values.</p><p><strong>Results: </strong>The findings imply that in the context of health care database investigations, Gamma regression models with non-parametric random effect consistently reduce heterogeneity and improve model accuracy. The generalized linear model with covariates and random effect (k = 4) had the best fit, indicating that Sudanese hospital length of stay data could be classified into four groups with varying average stays influenced by maternal, neonatal, and obstetrics data.</p><p><strong>Conclusion: </strong>Identifying factors contributing to longer stays allows hospitals to implement strategies for improvement. Non-parametric random effect model with Gamma distributed response effectively accounts for unobserved heterogeneity and individual-level variability, leading to more accurate inferences and improved patient care. Including random effects can significantly affect variable significance in statistical models, emphasizing the need to consider unobserved heterogeneity when analyzing data containing potential individual-level variability. The findings emphasise the importance of making robust methodological choices in healthcare research in order to inform accurate policy decisions.</p>\",\"PeriodicalId\":48947,\"journal\":{\"name\":\"Biodata Mining\",\"volume\":\"17 1\",\"pages\":\"47\"},\"PeriodicalIF\":6.1000,\"publicationDate\":\"2024-11-01\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC11529257/pdf/\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Biodata Mining\",\"FirstCategoryId\":\"99\",\"ListUrlMain\":\"https://doi.org/10.1186/s13040-024-00403-y\",\"RegionNum\":3,\"RegionCategory\":\"生物学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q1\",\"JCRName\":\"MATHEMATICAL & COMPUTATIONAL BIOLOGY\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Biodata Mining","FirstCategoryId":"99","ListUrlMain":"https://doi.org/10.1186/s13040-024-00403-y","RegionNum":3,"RegionCategory":"生物学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"MATHEMATICAL & COMPUTATIONAL BIOLOGY","Score":null,"Total":0}
Modeling heterogeneity of Sudanese hospital stay in neonatal and maternal unit: non-parametric random effect models with Gamma distribution.
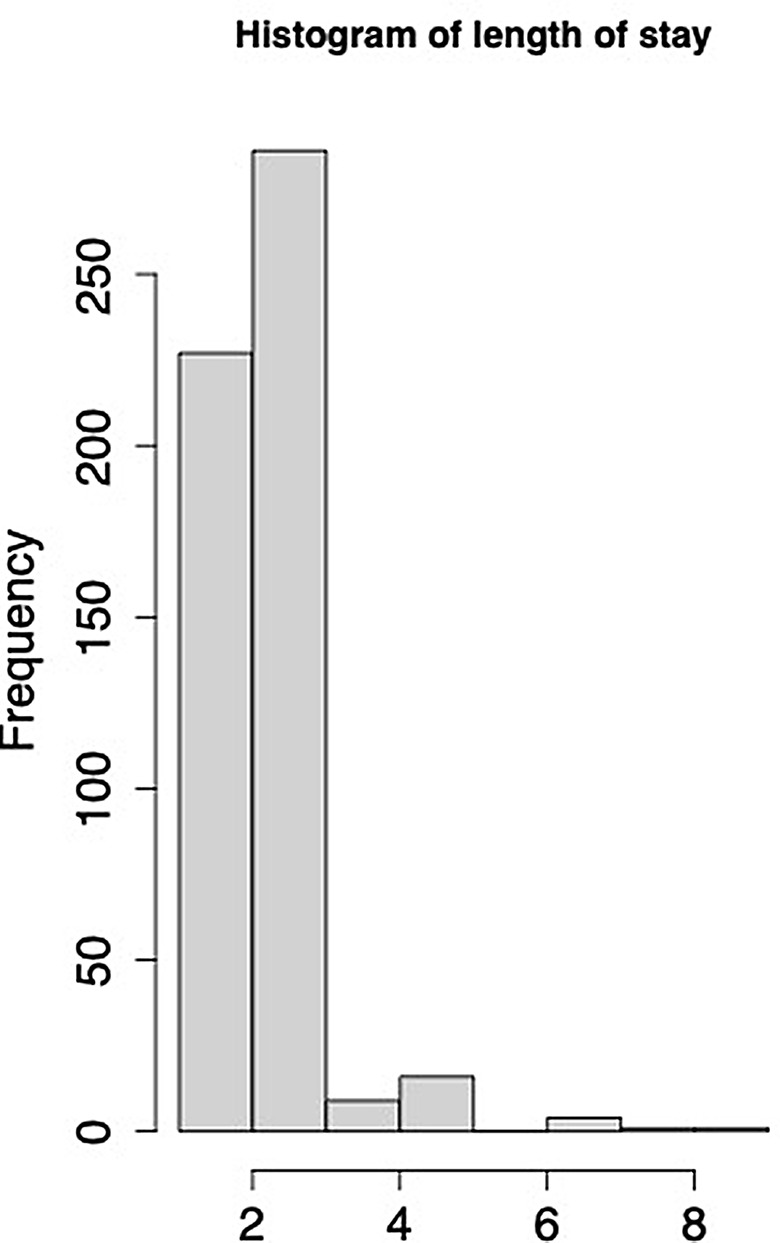
Objective: Studies looking into patient and institutional variables linked to extended hospital stays have arisen as a result of the increased focus on severe maternal morbidity and mortality. Understanding the length of hospitalization of patients after delivery is important to gain insights into when hospitals will reach capacity and to predict corresponding staffing or equipment requirements. In Sudan, the distribution of the length of stay during delivery hospitalizations is heavily skewed, with the average length of stay of 2 to 3 days. This study aimed to investigate the use of non-parametric random effect model with Gamma distributed response for analyzing skewed hospital length of stay data in Sudan in neonatal and maternal unit.
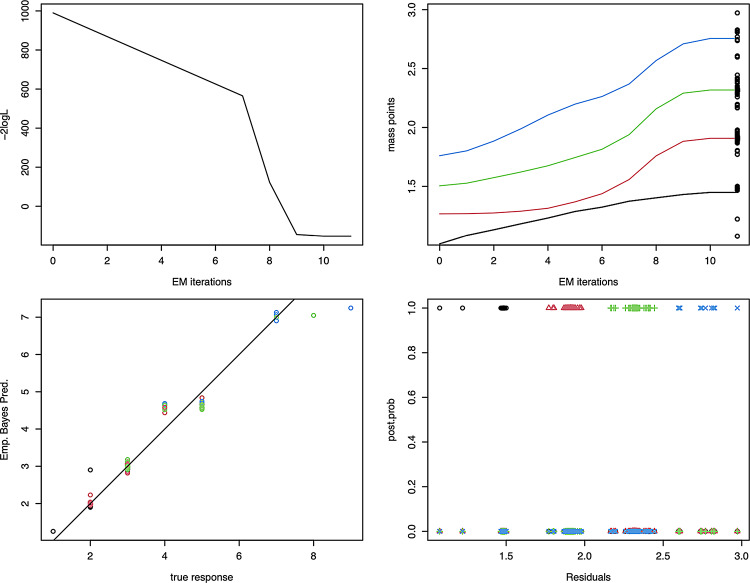
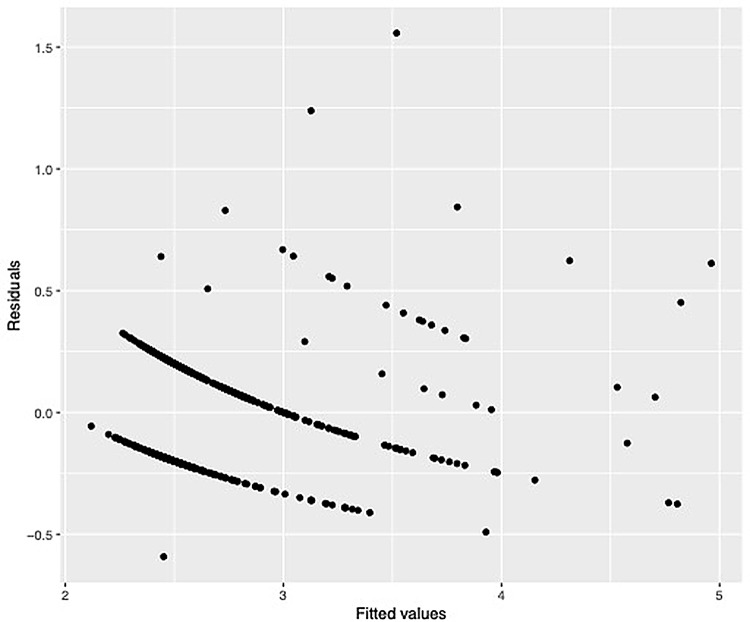
Methods: We applied Gamma regression models with unknown random effects, estimated using the non-parametric maximum likelihood (NPML) technique [5]. The NPML reduces the heterogeneity in the distribution of the response and produce a robust estimation since it does not require any assumptions on the distribution. The same applies to the log-Gamma link that does not require any transformation for the data distribution and it can handle the outliers in the data points. In this study, the models are fitted with and without covariates and compared using AIC and BIC values.
Results: The findings imply that in the context of health care database investigations, Gamma regression models with non-parametric random effect consistently reduce heterogeneity and improve model accuracy. The generalized linear model with covariates and random effect (k = 4) had the best fit, indicating that Sudanese hospital length of stay data could be classified into four groups with varying average stays influenced by maternal, neonatal, and obstetrics data.
Conclusion: Identifying factors contributing to longer stays allows hospitals to implement strategies for improvement. Non-parametric random effect model with Gamma distributed response effectively accounts for unobserved heterogeneity and individual-level variability, leading to more accurate inferences and improved patient care. Including random effects can significantly affect variable significance in statistical models, emphasizing the need to consider unobserved heterogeneity when analyzing data containing potential individual-level variability. The findings emphasise the importance of making robust methodological choices in healthcare research in order to inform accurate policy decisions.
期刊介绍:
BioData Mining is an open access, open peer-reviewed journal encompassing research on all aspects of data mining applied to high-dimensional biological and biomedical data, focusing on computational aspects of knowledge discovery from large-scale genetic, transcriptomic, genomic, proteomic, and metabolomic data.
Topical areas include, but are not limited to:
-Development, evaluation, and application of novel data mining and machine learning algorithms.
-Adaptation, evaluation, and application of traditional data mining and machine learning algorithms.
-Open-source software for the application of data mining and machine learning algorithms.
-Design, development and integration of databases, software and web services for the storage, management, retrieval, and analysis of data from large scale studies.
-Pre-processing, post-processing, modeling, and interpretation of data mining and machine learning results for biological interpretation and knowledge discovery.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


