Laila Musib, Roberta Coletti, Marta B Lopes, Helena Mouriño, Eunice Carrasquinha
{"title":"基于多组学数据的二元疾病结果预测优先级弹性网","authors":"Laila Musib, Roberta Coletti, Marta B Lopes, Helena Mouriño, Eunice Carrasquinha","doi":"10.1186/s13040-024-00401-0","DOIUrl":null,"url":null,"abstract":"<p><strong>Background: </strong>High-dimensional omics data integration has emerged as a prominent avenue within the healthcare industry, presenting substantial potential to improve predictive models. However, the data integration process faces several challenges, including data heterogeneity, priority sequence in which data blocks are prioritized for rendering predictive information contained in multiple blocks, assessing the flow of information from one omics level to the other and multicollinearity.</p><p><strong>Methods: </strong>We propose the Priority-Elastic net algorithm, a hierarchical regression method extending Priority-Lasso for the binary logistic regression model by incorporating a priority order for blocks of variables while fitting Elastic-net models sequentially for each block. The fitted values from each step are then used as an offset in the subsequent step. Additionally, we considered the adaptive elastic-net penalty within our priority framework to compare the results.</p><p><strong>Results: </strong>The Priority-Elastic net and Priority-Adaptive Elastic net algorithms were evaluated on a brain tumor dataset available from The Cancer Genome Atlas (TCGA), accounting for transcriptomics, proteomics, and clinical information measured over two glioma types: Lower-grade glioma (LGG) and glioblastoma (GBM).</p><p><strong>Conclusion: </strong>Our findings suggest that the Priority-Elastic net is a highly advantageous choice for a wide range of applications. It offers moderate computational complexity, flexibility in integrating prior knowledge while introducing a hierarchical modeling perspective, and, importantly, improved stability and accuracy in predictions, making it superior to the other methods discussed. This evolution marks a significant step forward in predictive modeling, offering a sophisticated tool for navigating the complexities of multi-omics datasets in pursuit of precision medicine's ultimate goal: personalized treatment optimization based on a comprehensive array of patient-specific data. This framework can be generalized to time-to-event, Cox proportional hazards regression and multicategorical outcomes. A practical implementation of this method is available upon request in R script, complete with an example to facilitate its application.</p>","PeriodicalId":48947,"journal":{"name":"Biodata Mining","volume":"17 1","pages":"45"},"PeriodicalIF":6.1000,"publicationDate":"2024-10-29","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC11523883/pdf/","citationCount":"0","resultStr":"{\"title\":\"Priority-Elastic net for binary disease outcome prediction based on multi-omics data.\",\"authors\":\"Laila Musib, Roberta Coletti, Marta B Lopes, Helena Mouriño, Eunice Carrasquinha\",\"doi\":\"10.1186/s13040-024-00401-0\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><strong>Background: </strong>High-dimensional omics data integration has emerged as a prominent avenue within the healthcare industry, presenting substantial potential to improve predictive models. However, the data integration process faces several challenges, including data heterogeneity, priority sequence in which data blocks are prioritized for rendering predictive information contained in multiple blocks, assessing the flow of information from one omics level to the other and multicollinearity.</p><p><strong>Methods: </strong>We propose the Priority-Elastic net algorithm, a hierarchical regression method extending Priority-Lasso for the binary logistic regression model by incorporating a priority order for blocks of variables while fitting Elastic-net models sequentially for each block. The fitted values from each step are then used as an offset in the subsequent step. Additionally, we considered the adaptive elastic-net penalty within our priority framework to compare the results.</p><p><strong>Results: </strong>The Priority-Elastic net and Priority-Adaptive Elastic net algorithms were evaluated on a brain tumor dataset available from The Cancer Genome Atlas (TCGA), accounting for transcriptomics, proteomics, and clinical information measured over two glioma types: Lower-grade glioma (LGG) and glioblastoma (GBM).</p><p><strong>Conclusion: </strong>Our findings suggest that the Priority-Elastic net is a highly advantageous choice for a wide range of applications. It offers moderate computational complexity, flexibility in integrating prior knowledge while introducing a hierarchical modeling perspective, and, importantly, improved stability and accuracy in predictions, making it superior to the other methods discussed. This evolution marks a significant step forward in predictive modeling, offering a sophisticated tool for navigating the complexities of multi-omics datasets in pursuit of precision medicine's ultimate goal: personalized treatment optimization based on a comprehensive array of patient-specific data. This framework can be generalized to time-to-event, Cox proportional hazards regression and multicategorical outcomes. A practical implementation of this method is available upon request in R script, complete with an example to facilitate its application.</p>\",\"PeriodicalId\":48947,\"journal\":{\"name\":\"Biodata Mining\",\"volume\":\"17 1\",\"pages\":\"45\"},\"PeriodicalIF\":6.1000,\"publicationDate\":\"2024-10-29\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC11523883/pdf/\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Biodata Mining\",\"FirstCategoryId\":\"99\",\"ListUrlMain\":\"https://doi.org/10.1186/s13040-024-00401-0\",\"RegionNum\":3,\"RegionCategory\":\"生物学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q1\",\"JCRName\":\"MATHEMATICAL & COMPUTATIONAL BIOLOGY\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Biodata Mining","FirstCategoryId":"99","ListUrlMain":"https://doi.org/10.1186/s13040-024-00401-0","RegionNum":3,"RegionCategory":"生物学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"MATHEMATICAL & COMPUTATIONAL BIOLOGY","Score":null,"Total":0}
引用次数: 0
摘要
背景:高维整体组学数据整合已成为医疗保健行业的一个重要途径,为改进预测模型提供了巨大潜力。然而,数据整合过程面临着一些挑战,包括数据异质性、数据块优先顺序以呈现包含在多个数据块中的预测信息、评估从一个整体组学层次到另一个整体组学层次的信息流以及多重共线性:我们提出了 "优先级弹性网算法",这是一种分层回归方法,它将优先级拉索(Priority-Lasso)扩展到了二元逻辑回归模型中,在为每个数据块依次拟合弹性网模型的同时,为变量块设定了优先级顺序。每一步的拟合值都会被用作后续步骤的偏移量。此外,我们还在优先级框架内考虑了自适应弹性网惩罚,以比较结果:我们在癌症基因组图谱(TCGA)提供的脑肿瘤数据集上对优先级弹性网算法和优先级自适应弹性网算法进行了评估,其中包括两种胶质瘤类型的转录组学、蛋白质组学和临床信息:结论:我们的研究结果表明,优先级弹性网是一种非常有利的选择,适用于广泛的应用领域。它具有适度的计算复杂性、整合先验知识的灵活性,同时引入了分层建模视角,更重要的是,它提高了预测的稳定性和准确性,使其优于所讨论的其他方法。这一演变标志着预测建模向前迈进了一大步,为驾驭复杂的多组学数据集提供了先进的工具,以实现精准医学的终极目标:基于一系列患者特定数据的个性化治疗优化。这一框架可推广到时间到事件、Cox 比例危险回归和多分类结果。如果您需要,我们可以用 R 脚本提供这种方法的实际应用,并提供一个示例以方便应用。
Priority-Elastic net for binary disease outcome prediction based on multi-omics data.
Background: High-dimensional omics data integration has emerged as a prominent avenue within the healthcare industry, presenting substantial potential to improve predictive models. However, the data integration process faces several challenges, including data heterogeneity, priority sequence in which data blocks are prioritized for rendering predictive information contained in multiple blocks, assessing the flow of information from one omics level to the other and multicollinearity.
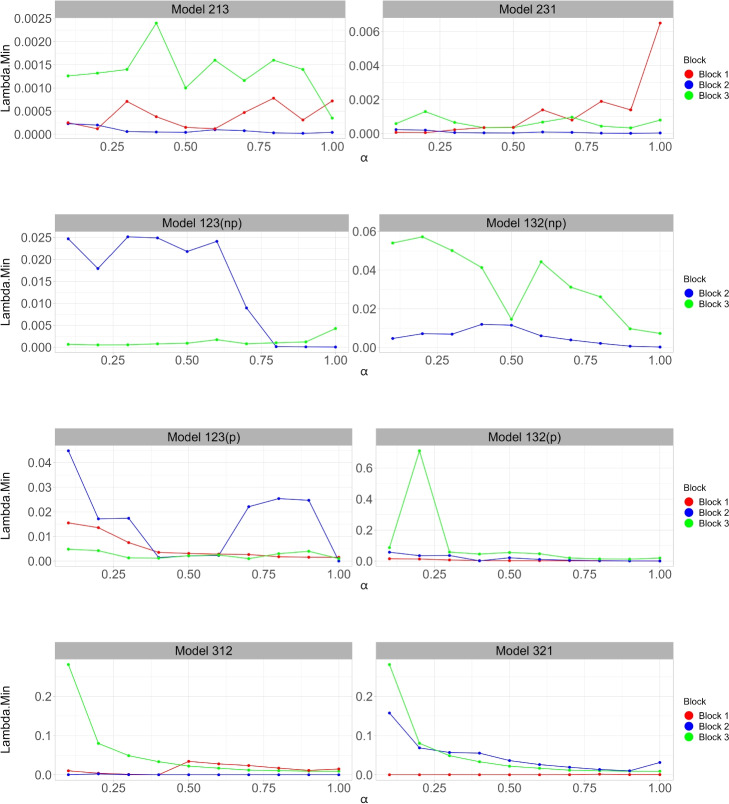
Methods: We propose the Priority-Elastic net algorithm, a hierarchical regression method extending Priority-Lasso for the binary logistic regression model by incorporating a priority order for blocks of variables while fitting Elastic-net models sequentially for each block. The fitted values from each step are then used as an offset in the subsequent step. Additionally, we considered the adaptive elastic-net penalty within our priority framework to compare the results.
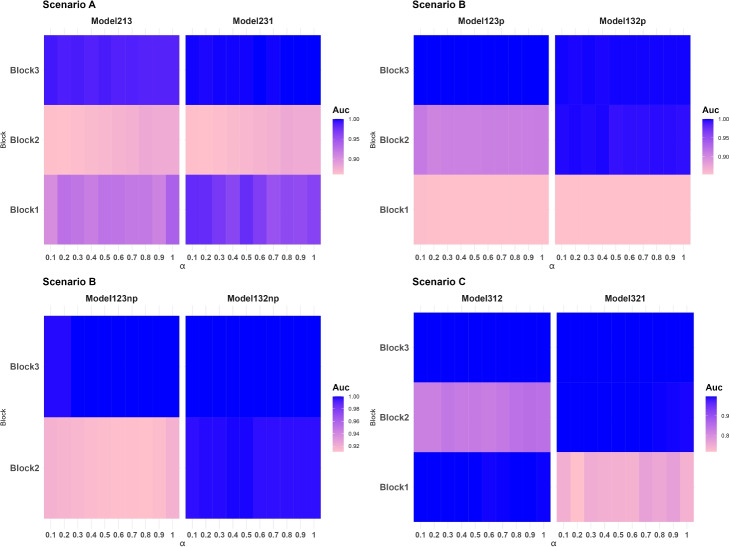
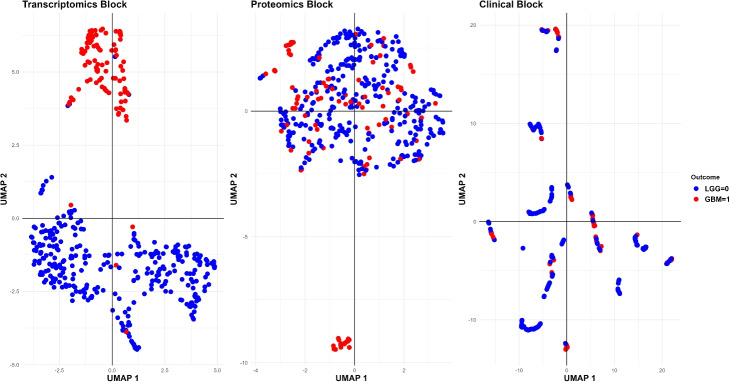
Results: The Priority-Elastic net and Priority-Adaptive Elastic net algorithms were evaluated on a brain tumor dataset available from The Cancer Genome Atlas (TCGA), accounting for transcriptomics, proteomics, and clinical information measured over two glioma types: Lower-grade glioma (LGG) and glioblastoma (GBM).
Conclusion: Our findings suggest that the Priority-Elastic net is a highly advantageous choice for a wide range of applications. It offers moderate computational complexity, flexibility in integrating prior knowledge while introducing a hierarchical modeling perspective, and, importantly, improved stability and accuracy in predictions, making it superior to the other methods discussed. This evolution marks a significant step forward in predictive modeling, offering a sophisticated tool for navigating the complexities of multi-omics datasets in pursuit of precision medicine's ultimate goal: personalized treatment optimization based on a comprehensive array of patient-specific data. This framework can be generalized to time-to-event, Cox proportional hazards regression and multicategorical outcomes. A practical implementation of this method is available upon request in R script, complete with an example to facilitate its application.
期刊介绍:
BioData Mining is an open access, open peer-reviewed journal encompassing research on all aspects of data mining applied to high-dimensional biological and biomedical data, focusing on computational aspects of knowledge discovery from large-scale genetic, transcriptomic, genomic, proteomic, and metabolomic data.
Topical areas include, but are not limited to:
-Development, evaluation, and application of novel data mining and machine learning algorithms.
-Adaptation, evaluation, and application of traditional data mining and machine learning algorithms.
-Open-source software for the application of data mining and machine learning algorithms.
-Design, development and integration of databases, software and web services for the storage, management, retrieval, and analysis of data from large scale studies.
-Pre-processing, post-processing, modeling, and interpretation of data mining and machine learning results for biological interpretation and knowledge discovery.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


