Tianying Zhao, Shuai Xu, Jie Ping, Guochong Jia, Yongchao Dou, Jill E. Henry, Bing Zhang, Xingyi Guo, Michele L. Cote, Qiuyin Cai, Xiao-Ou Shu, Wei Zheng, Jirong Long
{"title":"一项全蛋白质组关联研究确定了乳腺癌风险的潜在致病蛋白质。","authors":"Tianying Zhao, Shuai Xu, Jie Ping, Guochong Jia, Yongchao Dou, Jill E. Henry, Bing Zhang, Xingyi Guo, Michele L. Cote, Qiuyin Cai, Xiao-Ou Shu, Wei Zheng, Jirong Long","doi":"10.1038/s41416-024-02879-1","DOIUrl":null,"url":null,"abstract":"Genome-wide association studies (GWAS) have identified more than 200 breast cancer risk-associated genetic loci, yet the causal genes and biological mechanisms for most loci remain elusive. Proteins, as final gene products, are pivotal in cellular function. In this study, we conducted a proteome-wide association study (PWAS) to identify proteins in breast tissue related to breast cancer risk. We profiled the proteome in fresh frozen breast tissue samples from 120 cancer-free European-ancestry women from the Susan G. Komen Tissue Bank (KTB). Protein expression levels were log2-transformed then normalized via quantile and inverse-rank transformations. GWAS data were also generated for these 120 samples. These data were used to build statistical models to predict protein expression levels via cis-genetic variants using the elastic net method. The prediction models were then applied to the GWAS summary statistics data of 133,384 breast cancer cases and 113,789 controls to assess the associations of genetically predicted protein expression levels with breast cancer risk overall and its subtypes using the S-PrediXcan method. A total of 6388 proteins were detected in the normal breast tissue samples from 120 women with a high detection false discovery rate (FDR) p value < 0.01. Among the 5820 proteins detected in more than 80% of participants, prediction models were successfully built for 2060 proteins with R > 0.1 and P < 0.05. Among these 2060 proteins, five proteins were significantly associated with overall breast cancer risk at an FDR p value < 0.1. Among these five proteins, the corresponding genes for proteins COPG1, DCTN3, and DDX6 were located at least 1 Megabase away from the GWAS-identified breast cancer risk variants. COPG1 was associated with an increased risk of breast cancer with a p value of 8.54 × 10–4. Both DCTN3 and DDX6 were associated with a decreased risk of breast cancer with p values of 1.01 × 10–3 and 3.25 × 10–4, respectively. The corresponding genes for the remaining two proteins, LSP1 and DNAJA3, were located in previously GWAS-identified breast cancer risk loci. After adjusting for GWAS-identified risk variants, the association for DNAJA3 was still significant (p value of 9.15 × 10–5 and adjusted p value of 1.94 × 10–4). However, the significance for LSP1 became weaker with a p value of 0.62. Stratification analyses by breast cancer subtypes identified three proteins, SMARCC1, LSP1, and NCKAP1L, associated with luminal A, luminal B, and ER-positive breast cancer. NCKAP1L was located at least 1Mb away from the GWAS-identified breast cancer risk variants. After adjusting for GWAS-identified breast cancer risk variants, the association for protein LSP1 was still significant (adjusted p value of 6.43 × 10–3 for luminal B subtype). We conducted the first breast-tissue-based PWAS and identified seven proteins associated with breast cancer, including five proteins not previously implicated. These findings help improve our understanding of the underlying genetic mechanism of breast cancer development.","PeriodicalId":9243,"journal":{"name":"British Journal of Cancer","volume":"131 11","pages":"1796-1804"},"PeriodicalIF":6.4000,"publicationDate":"2024-10-28","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.nature.com/articles/s41416-024-02879-1.pdf","citationCount":"0","resultStr":"{\"title\":\"A proteome-wide association study identifies putative causal proteins for breast cancer risk\",\"authors\":\"Tianying Zhao, Shuai Xu, Jie Ping, Guochong Jia, Yongchao Dou, Jill E. Henry, Bing Zhang, Xingyi Guo, Michele L. Cote, Qiuyin Cai, Xiao-Ou Shu, Wei Zheng, Jirong Long\",\"doi\":\"10.1038/s41416-024-02879-1\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"Genome-wide association studies (GWAS) have identified more than 200 breast cancer risk-associated genetic loci, yet the causal genes and biological mechanisms for most loci remain elusive. Proteins, as final gene products, are pivotal in cellular function. In this study, we conducted a proteome-wide association study (PWAS) to identify proteins in breast tissue related to breast cancer risk. We profiled the proteome in fresh frozen breast tissue samples from 120 cancer-free European-ancestry women from the Susan G. Komen Tissue Bank (KTB). Protein expression levels were log2-transformed then normalized via quantile and inverse-rank transformations. GWAS data were also generated for these 120 samples. These data were used to build statistical models to predict protein expression levels via cis-genetic variants using the elastic net method. The prediction models were then applied to the GWAS summary statistics data of 133,384 breast cancer cases and 113,789 controls to assess the associations of genetically predicted protein expression levels with breast cancer risk overall and its subtypes using the S-PrediXcan method. A total of 6388 proteins were detected in the normal breast tissue samples from 120 women with a high detection false discovery rate (FDR) p value < 0.01. Among the 5820 proteins detected in more than 80% of participants, prediction models were successfully built for 2060 proteins with R > 0.1 and P < 0.05. Among these 2060 proteins, five proteins were significantly associated with overall breast cancer risk at an FDR p value < 0.1. Among these five proteins, the corresponding genes for proteins COPG1, DCTN3, and DDX6 were located at least 1 Megabase away from the GWAS-identified breast cancer risk variants. COPG1 was associated with an increased risk of breast cancer with a p value of 8.54 × 10–4. Both DCTN3 and DDX6 were associated with a decreased risk of breast cancer with p values of 1.01 × 10–3 and 3.25 × 10–4, respectively. The corresponding genes for the remaining two proteins, LSP1 and DNAJA3, were located in previously GWAS-identified breast cancer risk loci. After adjusting for GWAS-identified risk variants, the association for DNAJA3 was still significant (p value of 9.15 × 10–5 and adjusted p value of 1.94 × 10–4). However, the significance for LSP1 became weaker with a p value of 0.62. Stratification analyses by breast cancer subtypes identified three proteins, SMARCC1, LSP1, and NCKAP1L, associated with luminal A, luminal B, and ER-positive breast cancer. NCKAP1L was located at least 1Mb away from the GWAS-identified breast cancer risk variants. After adjusting for GWAS-identified breast cancer risk variants, the association for protein LSP1 was still significant (adjusted p value of 6.43 × 10–3 for luminal B subtype). We conducted the first breast-tissue-based PWAS and identified seven proteins associated with breast cancer, including five proteins not previously implicated. These findings help improve our understanding of the underlying genetic mechanism of breast cancer development.\",\"PeriodicalId\":9243,\"journal\":{\"name\":\"British Journal of Cancer\",\"volume\":\"131 11\",\"pages\":\"1796-1804\"},\"PeriodicalIF\":6.4000,\"publicationDate\":\"2024-10-28\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.nature.com/articles/s41416-024-02879-1.pdf\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"British Journal of Cancer\",\"FirstCategoryId\":\"3\",\"ListUrlMain\":\"https://www.nature.com/articles/s41416-024-02879-1\",\"RegionNum\":1,\"RegionCategory\":\"医学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q1\",\"JCRName\":\"ONCOLOGY\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"British Journal of Cancer","FirstCategoryId":"3","ListUrlMain":"https://www.nature.com/articles/s41416-024-02879-1","RegionNum":1,"RegionCategory":"医学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"ONCOLOGY","Score":null,"Total":0}
A proteome-wide association study identifies putative causal proteins for breast cancer risk
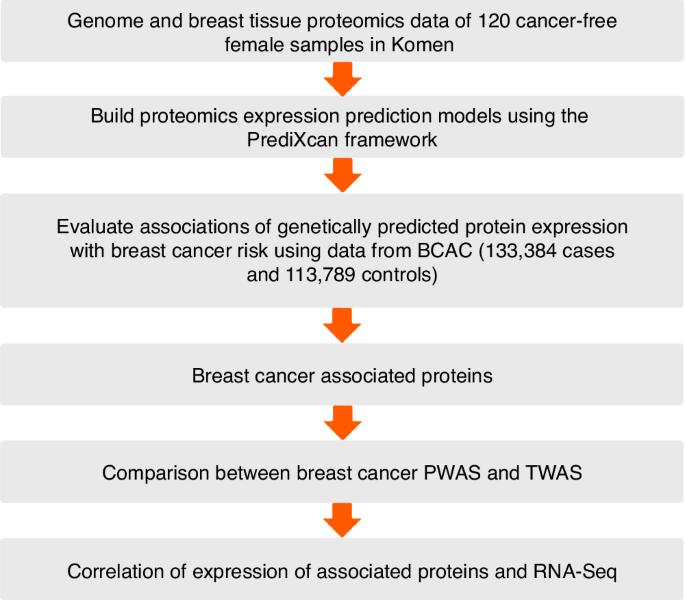
Genome-wide association studies (GWAS) have identified more than 200 breast cancer risk-associated genetic loci, yet the causal genes and biological mechanisms for most loci remain elusive. Proteins, as final gene products, are pivotal in cellular function. In this study, we conducted a proteome-wide association study (PWAS) to identify proteins in breast tissue related to breast cancer risk. We profiled the proteome in fresh frozen breast tissue samples from 120 cancer-free European-ancestry women from the Susan G. Komen Tissue Bank (KTB). Protein expression levels were log2-transformed then normalized via quantile and inverse-rank transformations. GWAS data were also generated for these 120 samples. These data were used to build statistical models to predict protein expression levels via cis-genetic variants using the elastic net method. The prediction models were then applied to the GWAS summary statistics data of 133,384 breast cancer cases and 113,789 controls to assess the associations of genetically predicted protein expression levels with breast cancer risk overall and its subtypes using the S-PrediXcan method. A total of 6388 proteins were detected in the normal breast tissue samples from 120 women with a high detection false discovery rate (FDR) p value < 0.01. Among the 5820 proteins detected in more than 80% of participants, prediction models were successfully built for 2060 proteins with R > 0.1 and P < 0.05. Among these 2060 proteins, five proteins were significantly associated with overall breast cancer risk at an FDR p value < 0.1. Among these five proteins, the corresponding genes for proteins COPG1, DCTN3, and DDX6 were located at least 1 Megabase away from the GWAS-identified breast cancer risk variants. COPG1 was associated with an increased risk of breast cancer with a p value of 8.54 × 10–4. Both DCTN3 and DDX6 were associated with a decreased risk of breast cancer with p values of 1.01 × 10–3 and 3.25 × 10–4, respectively. The corresponding genes for the remaining two proteins, LSP1 and DNAJA3, were located in previously GWAS-identified breast cancer risk loci. After adjusting for GWAS-identified risk variants, the association for DNAJA3 was still significant (p value of 9.15 × 10–5 and adjusted p value of 1.94 × 10–4). However, the significance for LSP1 became weaker with a p value of 0.62. Stratification analyses by breast cancer subtypes identified three proteins, SMARCC1, LSP1, and NCKAP1L, associated with luminal A, luminal B, and ER-positive breast cancer. NCKAP1L was located at least 1Mb away from the GWAS-identified breast cancer risk variants. After adjusting for GWAS-identified breast cancer risk variants, the association for protein LSP1 was still significant (adjusted p value of 6.43 × 10–3 for luminal B subtype). We conducted the first breast-tissue-based PWAS and identified seven proteins associated with breast cancer, including five proteins not previously implicated. These findings help improve our understanding of the underlying genetic mechanism of breast cancer development.
期刊介绍:
The British Journal of Cancer is one of the most-cited general cancer journals, publishing significant advances in translational and clinical cancer research.It also publishes high-quality reviews and thought-provoking comment on all aspects of cancer prevention,diagnosis and treatment.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


