基于历史感知跨模态特征融合的室内环境视觉语言导航
IF 7.6
1区 计算机科学
Q1 COMPUTER SCIENCE, ARTIFICIAL INTELLIGENCE
引用次数: 0
摘要
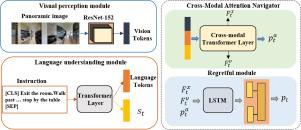
视觉语言导航(VLN)是一项具有挑战性的任务,它要求代理使用自然语言指令在室内环境中导航。传统的 VLN 采用了跨模态特征融合技术,将视觉信息和文本信息结合起来,引导机器人导航。然而,对感知信息的不完全使用、特定领域训练数据的匮乏,以及图像和语言输入的多样性,都会导致性能不尽如人意。在此,我们提出了一种跨模态特征融合 VLN 历史感知信息,它能利用代理的过往经验做出更明智的导航决策。我们添加了后悔模型和自我监控模型,并采用优势行动者批判(A2C)强化学习算法来提高导航成功率、减少行动冗余并缩短导航路径。随后,我们引入了一种基于扬声器数据的数据增强方法,以提高模型的泛化能力。我们在 "房间对房间"(R2R)和 "房间对房间"(R4R)基准上评估了所提出的算法,实验结果表明,通过比较,所提出的算法优于最先进的方法。本文章由计算机程序翻译,如有差异,请以英文原文为准。
Vision-and-language navigation based on history-aware cross-modal feature fusion in indoor environment
Vision-and-language navigation (VLN) is a challenging task that requires an agent to navigate an indoor environment using natural language instructions. Traditional VLN employs cross-modal feature fusion, where visual and textual information are combined to guide the agent’s navigation. However, incomplete use of perceptual information, scarcity of domain-specific training data, and diverse image and language inputs result in suboptimal performance. Herein, we propose a cross-modal feature fusion VLN history-aware information, that leverages an agent’s past experiences to make more informed navigation decisions. The regretful model and self-monitoring models are added, and the advantage actor critic(A2C) reinforcement learning algorithm is employed to improve the navigation success rate, reduce action redundancy, and shorten navigation paths. Subsequently, a data augmentation method based on speaker data is introduced to improve the model generalizability. We evaluate the proposed algorithm on the room-to-room (R2R) and room-for-room (R4R) benchmarks, and the experimental results demonstrate that, by comparison, the proposed algorithm outperforms state-of-the-art methods.
求助全文
通过发布文献求助,成功后即可免费获取论文全文。
去求助
来源期刊

Knowledge-Based Systems
工程技术-计算机:人工智能
CiteScore
14.80
自引率
12.50%
发文量
1245
审稿时长
7.8 months
期刊介绍:
Knowledge-Based Systems, an international and interdisciplinary journal in artificial intelligence, publishes original, innovative, and creative research results in the field. It focuses on knowledge-based and other artificial intelligence techniques-based systems. The journal aims to support human prediction and decision-making through data science and computation techniques, provide a balanced coverage of theory and practical study, and encourage the development and implementation of knowledge-based intelligence models, methods, systems, and software tools. Applications in business, government, education, engineering, and healthcare are emphasized.
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


