Wanling Gao, Jun Zhao, Jianfeng Gui, Zehan Wang, Jie Chen* and Zhenyu Yue*,
{"title":"全面评估基于 BERT 的抗菌肽预测方法","authors":"Wanling Gao, Jun Zhao, Jianfeng Gui, Zehan Wang, Jie Chen* and Zhenyu Yue*, ","doi":"10.1021/acs.jcim.4c0050710.1021/acs.jcim.4c00507","DOIUrl":null,"url":null,"abstract":"<p >In recent years, the prediction of antimicrobial peptides (AMPs) has gained prominence due to their high antibacterial activity and reduced susceptibility to drug resistance, making them potential antibiotic substitutes. To advance the field of AMP recognition, an increasing number of natural language processing methods are being applied. These methods exhibit diversity in terms of pretraining models, pretraining data sets, word vector embeddings, feature encoding methods, and downstream classification models. Here, we provide a comprehensive survey of current BERT-based methods for AMP prediction. An independent benchmark test data set is constructed to evaluate the predictive capabilities of the surveyed tools. Furthermore, we compared the predictive performance of these computational methods based on six different AMP public databases. LM_pred (BFD) outperformed all other surveyed tools due to abundant pretraining data set and the unique vector embedding approach. To avoid the impact of varying training data sets used by different methods on prediction performance, we performed the 5-fold cross-validation experiments using the same data set, involving retraining. Additionally, to explore the applicability and generalization ability of the models, we constructed a short peptide data set and an external data set to test the retrained models. Although these prediction methods based on BERT can achieve good prediction performance, there is still room for improvement in recognition accuracy. With the continuous enhancement of protein language model, we proposed an AMP prediction method based on the ESM-2 pretrained model called iAMP-bert. Experimental results demonstrate that iAMP-bert outperforms other approaches. iAMP-bert is freely accessible to the public at http://iamp.aielab.cc/.</p>","PeriodicalId":44,"journal":{"name":"Journal of Chemical Information and Modeling ","volume":"64 19","pages":"7772–7785 7772–7785"},"PeriodicalIF":5.3000,"publicationDate":"2024-09-24","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":"{\"title\":\"Comprehensive Assessment of BERT-Based Methods for Predicting Antimicrobial Peptides\",\"authors\":\"Wanling Gao, Jun Zhao, Jianfeng Gui, Zehan Wang, Jie Chen* and Zhenyu Yue*, \",\"doi\":\"10.1021/acs.jcim.4c0050710.1021/acs.jcim.4c00507\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p >In recent years, the prediction of antimicrobial peptides (AMPs) has gained prominence due to their high antibacterial activity and reduced susceptibility to drug resistance, making them potential antibiotic substitutes. To advance the field of AMP recognition, an increasing number of natural language processing methods are being applied. These methods exhibit diversity in terms of pretraining models, pretraining data sets, word vector embeddings, feature encoding methods, and downstream classification models. Here, we provide a comprehensive survey of current BERT-based methods for AMP prediction. An independent benchmark test data set is constructed to evaluate the predictive capabilities of the surveyed tools. Furthermore, we compared the predictive performance of these computational methods based on six different AMP public databases. LM_pred (BFD) outperformed all other surveyed tools due to abundant pretraining data set and the unique vector embedding approach. To avoid the impact of varying training data sets used by different methods on prediction performance, we performed the 5-fold cross-validation experiments using the same data set, involving retraining. Additionally, to explore the applicability and generalization ability of the models, we constructed a short peptide data set and an external data set to test the retrained models. Although these prediction methods based on BERT can achieve good prediction performance, there is still room for improvement in recognition accuracy. With the continuous enhancement of protein language model, we proposed an AMP prediction method based on the ESM-2 pretrained model called iAMP-bert. Experimental results demonstrate that iAMP-bert outperforms other approaches. iAMP-bert is freely accessible to the public at http://iamp.aielab.cc/.</p>\",\"PeriodicalId\":44,\"journal\":{\"name\":\"Journal of Chemical Information and Modeling \",\"volume\":\"64 19\",\"pages\":\"7772–7785 7772–7785\"},\"PeriodicalIF\":5.3000,\"publicationDate\":\"2024-09-24\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Journal of Chemical Information and Modeling \",\"FirstCategoryId\":\"92\",\"ListUrlMain\":\"https://pubs.acs.org/doi/10.1021/acs.jcim.4c00507\",\"RegionNum\":2,\"RegionCategory\":\"化学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q1\",\"JCRName\":\"CHEMISTRY, MEDICINAL\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Journal of Chemical Information and Modeling ","FirstCategoryId":"92","ListUrlMain":"https://pubs.acs.org/doi/10.1021/acs.jcim.4c00507","RegionNum":2,"RegionCategory":"化学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"CHEMISTRY, MEDICINAL","Score":null,"Total":0}
Comprehensive Assessment of BERT-Based Methods for Predicting Antimicrobial Peptides
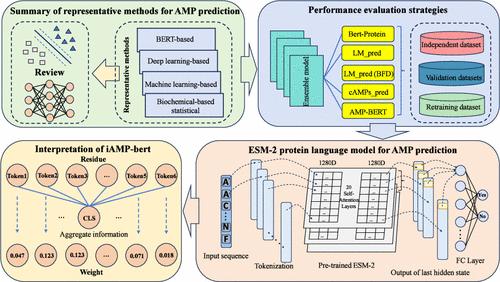
In recent years, the prediction of antimicrobial peptides (AMPs) has gained prominence due to their high antibacterial activity and reduced susceptibility to drug resistance, making them potential antibiotic substitutes. To advance the field of AMP recognition, an increasing number of natural language processing methods are being applied. These methods exhibit diversity in terms of pretraining models, pretraining data sets, word vector embeddings, feature encoding methods, and downstream classification models. Here, we provide a comprehensive survey of current BERT-based methods for AMP prediction. An independent benchmark test data set is constructed to evaluate the predictive capabilities of the surveyed tools. Furthermore, we compared the predictive performance of these computational methods based on six different AMP public databases. LM_pred (BFD) outperformed all other surveyed tools due to abundant pretraining data set and the unique vector embedding approach. To avoid the impact of varying training data sets used by different methods on prediction performance, we performed the 5-fold cross-validation experiments using the same data set, involving retraining. Additionally, to explore the applicability and generalization ability of the models, we constructed a short peptide data set and an external data set to test the retrained models. Although these prediction methods based on BERT can achieve good prediction performance, there is still room for improvement in recognition accuracy. With the continuous enhancement of protein language model, we proposed an AMP prediction method based on the ESM-2 pretrained model called iAMP-bert. Experimental results demonstrate that iAMP-bert outperforms other approaches. iAMP-bert is freely accessible to the public at http://iamp.aielab.cc/.
期刊介绍:
The Journal of Chemical Information and Modeling publishes papers reporting new methodology and/or important applications in the fields of chemical informatics and molecular modeling. Specific topics include the representation and computer-based searching of chemical databases, molecular modeling, computer-aided molecular design of new materials, catalysts, or ligands, development of new computational methods or efficient algorithms for chemical software, and biopharmaceutical chemistry including analyses of biological activity and other issues related to drug discovery.
Astute chemists, computer scientists, and information specialists look to this monthly’s insightful research studies, programming innovations, and software reviews to keep current with advances in this integral, multidisciplinary field.
As a subscriber you’ll stay abreast of database search systems, use of graph theory in chemical problems, substructure search systems, pattern recognition and clustering, analysis of chemical and physical data, molecular modeling, graphics and natural language interfaces, bibliometric and citation analysis, and synthesis design and reactions databases.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


