面部组件中的地标:实现基于闭塞的面部地标定位
IF 4.2
3区 计算机科学
Q2 COMPUTER SCIENCE, ARTIFICIAL INTELLIGENCE
引用次数: 0
摘要
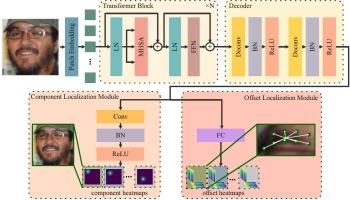
尽管近年来人们在研究稳健的面部地标定位方法方面做出了巨大努力,但遮挡仍然是一个挑战。为了应对这一挑战,我们提出了一个名为 "面部地标-组件网络"(LFCNet)的模型。与专注于边界信息的主流模型不同,LFCNet 利用面部解剖学固有的强大结构约束来解决闭塞问题。具体来说,LFCNet 设计了两个关键模块,即组件定位模块和偏移定位模块。根据面部组件对地标进行分组后,组件定位模块完成面部组件的粗定位。偏移定位模块根据粗定位结果对地标进行精细定位,这也可以看作是对面部组件形状的划分。这两个模块构成了从粗定位到精细定位的流水线,也能使 LFCNet 更好地学习人脸的形状约束,从而增强 LFCNet 对遮挡的鲁棒性。LFCNet 在 WFLW 数据集的遮挡子集上实现了 4.82% 的归一化平均误差,在遮挡 300W 数据集上实现了 6.33% 的归一化平均误差。结果表明,与最先进的方法相比,LFCNet 取得了优异的性能,尤其是在遮挡数据集上。本文章由计算机程序翻译,如有差异,请以英文原文为准。
Landmark-in-facial-component: Towards occlusion-robust facial landmark localization
Despite great efforts in recent years to research robust facial landmark localization methods, occlusion remains a challenge. To tackle this challenge, we propose a model called the Landmark-in-Facial-Component Network (LFCNet). Unlike mainstream models that focus on boundary information, LFCNet utilizes the strong structural constraints inherent in facial anatomy to address occlusion. Specifically, two key modules are designed, a component localization module and an offset localization module. After grouping landmarks based on facial components, the component localization module accomplishes coarse localization of facial components. Offset localization module performs fine localization of landmarks based on the coarse localization results, which can also be seen as delineating the shape of facial components. These two modules form a coarse-to-fine localization pipeline and can also enable LFCNet to better learn the shape constraint of human faces, thereby enhancing LFCNet's robustness to occlusion. LFCNet achieves 4.82% normalized mean error on occlusion subset of WFLW dataset and 6.33% normalized mean error on Masked 300W dataset. The results demonstrate that LFCNet achieves excellent performance in comparison to state-of-the-art methods, especially on occlusion datasets.
求助全文
通过发布文献求助,成功后即可免费获取论文全文。
去求助
来源期刊

Image and Vision Computing
工程技术-工程:电子与电气
CiteScore
8.50
自引率
8.50%
发文量
143
审稿时长
7.8 months
期刊介绍:
Image and Vision Computing has as a primary aim the provision of an effective medium of interchange for the results of high quality theoretical and applied research fundamental to all aspects of image interpretation and computer vision. The journal publishes work that proposes new image interpretation and computer vision methodology or addresses the application of such methods to real world scenes. It seeks to strengthen a deeper understanding in the discipline by encouraging the quantitative comparison and performance evaluation of the proposed methodology. The coverage includes: image interpretation, scene modelling, object recognition and tracking, shape analysis, monitoring and surveillance, active vision and robotic systems, SLAM, biologically-inspired computer vision, motion analysis, stereo vision, document image understanding, character and handwritten text recognition, face and gesture recognition, biometrics, vision-based human-computer interaction, human activity and behavior understanding, data fusion from multiple sensor inputs, image databases.
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


