{"title":"利用两个新激活函数:modExp 和 modExpm 提高神经网络性能","authors":"Heena Kalim, Anuradha Chug, Amit Prakash Singh","doi":"10.3103/S1060992X24700152","DOIUrl":null,"url":null,"abstract":"<p>The paper introduces two novel activation functions known as modExp and modExp<sub>m</sub>. The activation functions possess several desirable properties, such as being continuously differentiable, bounded, smooth, and non-monotonic. Our studies have shown that modExp and modExp<sub>m</sub> consistently outperform ReLU and other activation functions across a range of challenging datasets and complex models. Initially, the experiments involve training and classifying using a multi-layer perceptron (MLP) on benchmark data sets like the Diagnostic Wisconsin Breast Cancer and Iris Flower datasets. Both modExp and modExp<sub>m</sub> demonstrate impressive performance, with modExp achieving 94.15 and 95.56% and modExp<sub>m</sub> achieving 94.15 and 95.56% respectively, when compared to ReLU, ELU, Tanh, Mish, Softsign, Leaky ReLU, and TanhExp. In addition, a series of experiments were carried out on five different depths of deeper neural networks, ranging from five to eight layers, using MNIST datasets. The modExp<sub>m</sub> activation function demonstrated superior performance accuracy on various neural network configurations, achieving 95.56, 95.43, 94.72, 95.14, and 95.61% on wider 5 layers, slimmer 5 layers, 6 layers, 7 layers, and 8 layers respectively. The modExp activation function also performed well, achieving the second highest accuracy of 95.42, 94.33, 94.76, 95.06, and 95.37% on the same network configurations, outperforming ReLU, ELU, Tanh, Mish, Softsign, Leaky ReLU, and TanhExp. The results of the statistical feature measures show that both activation functions have the highest mean accuracy, the lowest standard deviation, the lowest Root Mean squared Error, the lowest variance, and the lowest Mean squared Error. According to the experiment, both functions converge more quickly than ReLU, which is a significant advantage in Neural network learning.</p>","PeriodicalId":721,"journal":{"name":"Optical Memory and Neural Networks","volume":"33 3","pages":"286 - 301"},"PeriodicalIF":0.8000,"publicationDate":"2024-09-26","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":"{\"title\":\"Enhancement of Neural Network Performance with the Use of Two Novel Activation Functions: modExp and modExpm\",\"authors\":\"Heena Kalim, Anuradha Chug, Amit Prakash Singh\",\"doi\":\"10.3103/S1060992X24700152\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p>The paper introduces two novel activation functions known as modExp and modExp<sub>m</sub>. The activation functions possess several desirable properties, such as being continuously differentiable, bounded, smooth, and non-monotonic. Our studies have shown that modExp and modExp<sub>m</sub> consistently outperform ReLU and other activation functions across a range of challenging datasets and complex models. Initially, the experiments involve training and classifying using a multi-layer perceptron (MLP) on benchmark data sets like the Diagnostic Wisconsin Breast Cancer and Iris Flower datasets. Both modExp and modExp<sub>m</sub> demonstrate impressive performance, with modExp achieving 94.15 and 95.56% and modExp<sub>m</sub> achieving 94.15 and 95.56% respectively, when compared to ReLU, ELU, Tanh, Mish, Softsign, Leaky ReLU, and TanhExp. In addition, a series of experiments were carried out on five different depths of deeper neural networks, ranging from five to eight layers, using MNIST datasets. The modExp<sub>m</sub> activation function demonstrated superior performance accuracy on various neural network configurations, achieving 95.56, 95.43, 94.72, 95.14, and 95.61% on wider 5 layers, slimmer 5 layers, 6 layers, 7 layers, and 8 layers respectively. The modExp activation function also performed well, achieving the second highest accuracy of 95.42, 94.33, 94.76, 95.06, and 95.37% on the same network configurations, outperforming ReLU, ELU, Tanh, Mish, Softsign, Leaky ReLU, and TanhExp. The results of the statistical feature measures show that both activation functions have the highest mean accuracy, the lowest standard deviation, the lowest Root Mean squared Error, the lowest variance, and the lowest Mean squared Error. According to the experiment, both functions converge more quickly than ReLU, which is a significant advantage in Neural network learning.</p>\",\"PeriodicalId\":721,\"journal\":{\"name\":\"Optical Memory and Neural Networks\",\"volume\":\"33 3\",\"pages\":\"286 - 301\"},\"PeriodicalIF\":0.8000,\"publicationDate\":\"2024-09-26\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Optical Memory and Neural Networks\",\"FirstCategoryId\":\"1085\",\"ListUrlMain\":\"https://link.springer.com/article/10.3103/S1060992X24700152\",\"RegionNum\":0,\"RegionCategory\":null,\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q4\",\"JCRName\":\"OPTICS\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Optical Memory and Neural Networks","FirstCategoryId":"1085","ListUrlMain":"https://link.springer.com/article/10.3103/S1060992X24700152","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q4","JCRName":"OPTICS","Score":null,"Total":0}
Enhancement of Neural Network Performance with the Use of Two Novel Activation Functions: modExp and modExpm
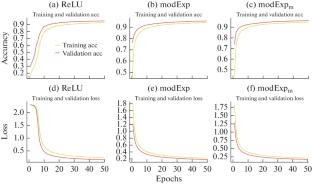
The paper introduces two novel activation functions known as modExp and modExpm. The activation functions possess several desirable properties, such as being continuously differentiable, bounded, smooth, and non-monotonic. Our studies have shown that modExp and modExpm consistently outperform ReLU and other activation functions across a range of challenging datasets and complex models. Initially, the experiments involve training and classifying using a multi-layer perceptron (MLP) on benchmark data sets like the Diagnostic Wisconsin Breast Cancer and Iris Flower datasets. Both modExp and modExpm demonstrate impressive performance, with modExp achieving 94.15 and 95.56% and modExpm achieving 94.15 and 95.56% respectively, when compared to ReLU, ELU, Tanh, Mish, Softsign, Leaky ReLU, and TanhExp. In addition, a series of experiments were carried out on five different depths of deeper neural networks, ranging from five to eight layers, using MNIST datasets. The modExpm activation function demonstrated superior performance accuracy on various neural network configurations, achieving 95.56, 95.43, 94.72, 95.14, and 95.61% on wider 5 layers, slimmer 5 layers, 6 layers, 7 layers, and 8 layers respectively. The modExp activation function also performed well, achieving the second highest accuracy of 95.42, 94.33, 94.76, 95.06, and 95.37% on the same network configurations, outperforming ReLU, ELU, Tanh, Mish, Softsign, Leaky ReLU, and TanhExp. The results of the statistical feature measures show that both activation functions have the highest mean accuracy, the lowest standard deviation, the lowest Root Mean squared Error, the lowest variance, and the lowest Mean squared Error. According to the experiment, both functions converge more quickly than ReLU, which is a significant advantage in Neural network learning.
期刊介绍:
The journal covers a wide range of issues in information optics such as optical memory, mechanisms for optical data recording and processing, photosensitive materials, optical, optoelectronic and holographic nanostructures, and many other related topics. Papers on memory systems using holographic and biological structures and concepts of brain operation are also included. The journal pays particular attention to research in the field of neural net systems that may lead to a new generation of computional technologies by endowing them with intelligence.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


