M. I. Rudakov, A. N. Beznosikov, Ya. A. Kholodov, A. V. Gasnikov
{"title":"用于模型并行训练的激活和梯度压缩","authors":"M. I. Rudakov, A. N. Beznosikov, Ya. A. Kholodov, A. V. Gasnikov","doi":"10.1134/S1064562423701314","DOIUrl":null,"url":null,"abstract":"<p>Large neural networks require enormous computational clusters of machines. Model-parallel training, when the model architecture is partitioned sequentially between workers, is a popular approach for training modern models. Information compression can be applied to decrease workers’ communication time, as it is often a bottleneck in such systems. This work explores how simultaneous compression of activations and gradients in model-parallel distributed training setup affects convergence. We analyze compression methods such as quantization and TopK compression, and also experiment with error compensation techniques. Moreover, we employ TopK with AQ-SGD per-batch error feedback approach. We conduct experiments on image classification and language model fine-tuning tasks. Our findings demonstrate that gradients require milder compression rates than activations. We observe that <span>\\(K = 10\\% \\)</span> is the lowest TopK compression level, which does not harm model convergence severely. Experiments also show that models trained with TopK perform well only when compression is also applied during inference. We find that error feedback techniques do not improve model-parallel training compared to plain compression, but allow model inference without compression with almost no quality drop. Finally, when applied with the AQ-SGD approach, TopK stronger than with <span>\\(K = 30\\% \\)</span> worsens model performance significantly.</p>","PeriodicalId":531,"journal":{"name":"Doklady Mathematics","volume":"108 2 supplement","pages":"S272 - S281"},"PeriodicalIF":0.5000,"publicationDate":"2024-03-25","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":"{\"title\":\"Activations and Gradients Compression for Model-Parallel Training\",\"authors\":\"M. I. Rudakov, A. N. Beznosikov, Ya. A. Kholodov, A. V. Gasnikov\",\"doi\":\"10.1134/S1064562423701314\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p>Large neural networks require enormous computational clusters of machines. Model-parallel training, when the model architecture is partitioned sequentially between workers, is a popular approach for training modern models. Information compression can be applied to decrease workers’ communication time, as it is often a bottleneck in such systems. This work explores how simultaneous compression of activations and gradients in model-parallel distributed training setup affects convergence. We analyze compression methods such as quantization and TopK compression, and also experiment with error compensation techniques. Moreover, we employ TopK with AQ-SGD per-batch error feedback approach. We conduct experiments on image classification and language model fine-tuning tasks. Our findings demonstrate that gradients require milder compression rates than activations. We observe that <span>\\\\(K = 10\\\\% \\\\)</span> is the lowest TopK compression level, which does not harm model convergence severely. Experiments also show that models trained with TopK perform well only when compression is also applied during inference. We find that error feedback techniques do not improve model-parallel training compared to plain compression, but allow model inference without compression with almost no quality drop. Finally, when applied with the AQ-SGD approach, TopK stronger than with <span>\\\\(K = 30\\\\% \\\\)</span> worsens model performance significantly.</p>\",\"PeriodicalId\":531,\"journal\":{\"name\":\"Doklady Mathematics\",\"volume\":\"108 2 supplement\",\"pages\":\"S272 - S281\"},\"PeriodicalIF\":0.5000,\"publicationDate\":\"2024-03-25\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Doklady Mathematics\",\"FirstCategoryId\":\"100\",\"ListUrlMain\":\"https://link.springer.com/article/10.1134/S1064562423701314\",\"RegionNum\":4,\"RegionCategory\":\"数学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q3\",\"JCRName\":\"MATHEMATICS\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Doklady Mathematics","FirstCategoryId":"100","ListUrlMain":"https://link.springer.com/article/10.1134/S1064562423701314","RegionNum":4,"RegionCategory":"数学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q3","JCRName":"MATHEMATICS","Score":null,"Total":0}
Activations and Gradients Compression for Model-Parallel Training
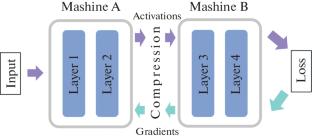
Large neural networks require enormous computational clusters of machines. Model-parallel training, when the model architecture is partitioned sequentially between workers, is a popular approach for training modern models. Information compression can be applied to decrease workers’ communication time, as it is often a bottleneck in such systems. This work explores how simultaneous compression of activations and gradients in model-parallel distributed training setup affects convergence. We analyze compression methods such as quantization and TopK compression, and also experiment with error compensation techniques. Moreover, we employ TopK with AQ-SGD per-batch error feedback approach. We conduct experiments on image classification and language model fine-tuning tasks. Our findings demonstrate that gradients require milder compression rates than activations. We observe that \(K = 10\% \) is the lowest TopK compression level, which does not harm model convergence severely. Experiments also show that models trained with TopK perform well only when compression is also applied during inference. We find that error feedback techniques do not improve model-parallel training compared to plain compression, but allow model inference without compression with almost no quality drop. Finally, when applied with the AQ-SGD approach, TopK stronger than with \(K = 30\% \) worsens model performance significantly.
期刊介绍:
Doklady Mathematics is a journal of the Presidium of the Russian Academy of Sciences. It contains English translations of papers published in Doklady Akademii Nauk (Proceedings of the Russian Academy of Sciences), which was founded in 1933 and is published 36 times a year. Doklady Mathematics includes the materials from the following areas: mathematics, mathematical physics, computer science, control theory, and computers. It publishes brief scientific reports on previously unpublished significant new research in mathematics and its applications. The main contributors to the journal are Members of the RAS, Corresponding Members of the RAS, and scientists from the former Soviet Union and other foreign countries. Among the contributors are the outstanding Russian mathematicians.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


