优化基于序列的基因调控深度学习模型的社区努力
IF 41.7
1区 生物学
Q1 BIOTECHNOLOGY & APPLIED MICROBIOLOGY
引用次数: 0
摘要
我们需要对模型架构和训练策略如何影响基因组学模型性能进行系统评估。为了弥补这一不足,我们举办了一次 DREAM 挑战赛,让参赛者在数百万个随机启动子 DNA 序列和相应表达水平的数据集上训练模型,这些数据是在酵母中通过实验确定的。为了对模型进行稳健的评估,我们设计了一套涵盖各种序列类型的综合基准。所有表现优异的模型都使用了神经网络,但在架构和训练策略上存在差异。为了剖析架构和训练选择对性能的影响,我们开发了 Prix Fixe 框架,将模型划分为模块化构件。我们测试了前三名模型的所有可能组合,进一步提高了它们的性能。DREAM 挑战赛的模型不仅在我们的综合酵母数据集上取得了最先进的结果,而且还不断超越果蝇和人类基因组数据集上的现有基准,证明了黄金标准基因组学数据集可以推动进步。本文章由计算机程序翻译,如有差异,请以英文原文为准。
A community effort to optimize sequence-based deep learning models of gene regulation
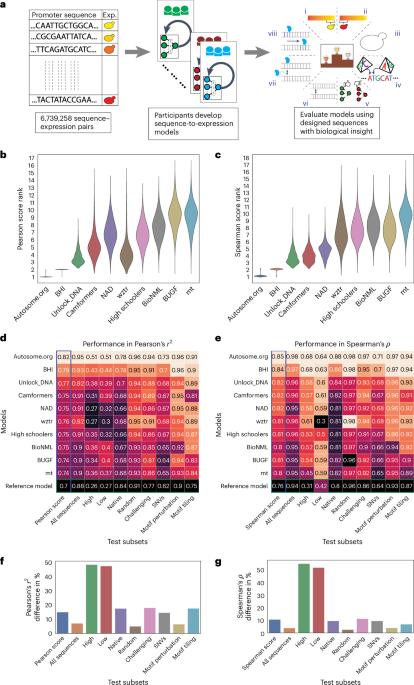
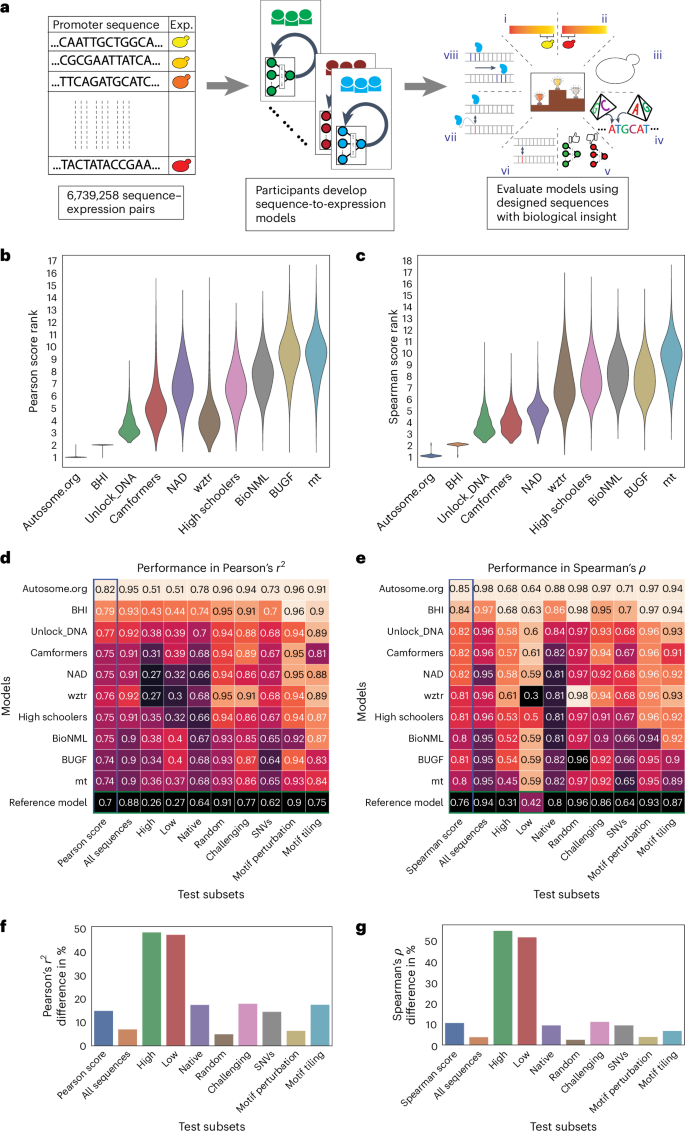
A systematic evaluation of how model architectures and training strategies impact genomics model performance is needed. To address this gap, we held a DREAM Challenge where competitors trained models on a dataset of millions of random promoter DNA sequences and corresponding expression levels, experimentally determined in yeast. For a robust evaluation of the models, we designed a comprehensive suite of benchmarks encompassing various sequence types. All top-performing models used neural networks but diverged in architectures and training strategies. To dissect how architectural and training choices impact performance, we developed the Prix Fixe framework to divide models into modular building blocks. We tested all possible combinations for the top three models, further improving their performance. The DREAM Challenge models not only achieved state-of-the-art results on our comprehensive yeast dataset but also consistently surpassed existing benchmarks on Drosophila and human genomic datasets, demonstrating the progress that can be driven by gold-standard genomics datasets. A benchmarking competition improves tools that predict how regulatory regions control gene expression.
求助全文
通过发布文献求助,成功后即可免费获取论文全文。
去求助
来源期刊
Nature biotechnology
工程技术-生物工程与应用微生物
CiteScore
63.00
自引率
1.70%
发文量
382
审稿时长
3 months
期刊介绍:
Nature Biotechnology is a monthly journal that focuses on the science and business of biotechnology. It covers a wide range of topics including technology/methodology advancements in the biological, biomedical, agricultural, and environmental sciences. The journal also explores the commercial, political, ethical, legal, and societal aspects of this research.
The journal serves researchers by providing peer-reviewed research papers in the field of biotechnology. It also serves the business community by delivering news about research developments. This approach ensures that both the scientific and business communities are well-informed and able to stay up-to-date on the latest advancements and opportunities in the field.
Some key areas of interest in which the journal actively seeks research papers include molecular engineering of nucleic acids and proteins, molecular therapy, large-scale biology, computational biology, regenerative medicine, imaging technology, analytical biotechnology, applied immunology, food and agricultural biotechnology, and environmental biotechnology.
In summary, Nature Biotechnology is a comprehensive journal that covers both the scientific and business aspects of biotechnology. It strives to provide researchers with valuable research papers and news while also delivering important scientific advancements to the business community.
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


