利用强化学习在院外心脏骤停的现场复苏时间内做出个性化决策
IF 12.4
1区 医学
Q1 HEALTH CARE SCIENCES & SERVICES
引用次数: 0
摘要
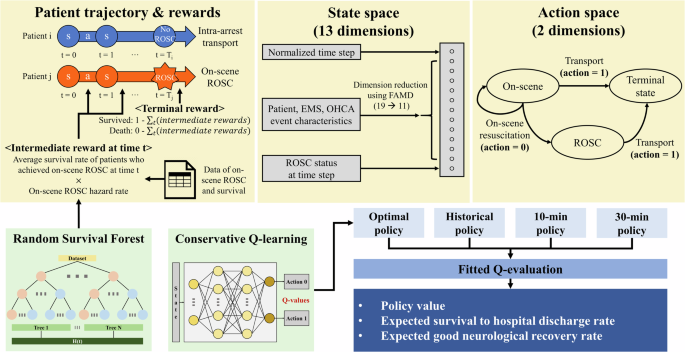
现场复苏时间与院外心脏骤停(OHCA)的预后有关。我们利用韩国全国范围内的数据,开发并验证了个性化现场复苏时间强化学习模型。我们纳入了因医学原因导致心跳骤停的成人 OHCA 患者(N = 73905)。通过保守的 Q-learning(Q-learning)方法得出了最优策略,从而最大限度地提高了存活率。随机生存森林估算出的现场自主循环恢复危险率被用作中间奖励,以处理稀疏奖励,而患者的历史存活率则反映在最终奖励中。最佳策略将出院生存率从 9.6% 提高到 12.5%(95% CI:12.2-12.8),神经功能恢复良好率从 5.4% 提高到 7.5%(95% CI:7.3-7.7)。建议患者的最长现场复苏时间呈双峰分布,因患者、急救医疗服务和 OHCA 特征而异。我们基于生存分析的方法能产生可解释的奖励,减少了强化学习中的主观性。本文章由计算机程序翻译,如有差异,请以英文原文为准。
Individualized decision making in on-scene resuscitation time for out-of-hospital cardiac arrest using reinforcement learning
On-scene resuscitation time is associated with out-of-hospital cardiac arrest (OHCA) outcomes. We developed and validated reinforcement learning models for individualized on-scene resuscitation times, leveraging nationwide Korean data. Adult OHCA patients with a medical cause of arrest were included (N = 73,905). The optimal policy was derived from conservative Q-learning to maximize survival. The on-scene return of spontaneous circulation hazard rates estimated from the Random Survival Forest were used as intermediate rewards to handle sparse rewards, while patients’ historical survival was reflected in the terminal rewards. The optimal policy increased the survival to hospital discharge rate from 9.6% to 12.5% (95% CI: 12.2–12.8) and the good neurological recovery rate from 5.4% to 7.5% (95% CI: 7.3–7.7). The recommended maximum on-scene resuscitation times for patients demonstrated a bimodal distribution, varying with patient, emergency medical services, and OHCA characteristics. Our survival analysis-based approach generates explainable rewards, reducing subjectivity in reinforcement learning.
求助全文
通过发布文献求助,成功后即可免费获取论文全文。
去求助
来源期刊

NPJ Digital Medicine
Multiple-
CiteScore
25.10
自引率
3.30%
发文量
170
审稿时长
15 weeks
期刊介绍:
npj Digital Medicine is an online open-access journal that focuses on publishing peer-reviewed research in the field of digital medicine. The journal covers various aspects of digital medicine, including the application and implementation of digital and mobile technologies in clinical settings, virtual healthcare, and the use of artificial intelligence and informatics.
The primary goal of the journal is to support innovation and the advancement of healthcare through the integration of new digital and mobile technologies. When determining if a manuscript is suitable for publication, the journal considers four important criteria: novelty, clinical relevance, scientific rigor, and digital innovation.
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


