Casey Choong, Alan Brnabic, Chanadda Chinthammit, Meena Ravuri, Kendra Terrell, Hong Kan
{"title":"利用美国健康管理索赔数据库,采用机器学习方法预测肥胖风险。","authors":"Casey Choong, Alan Brnabic, Chanadda Chinthammit, Meena Ravuri, Kendra Terrell, Hong Kan","doi":"10.1136/bmjdrc-2024-004193","DOIUrl":null,"url":null,"abstract":"<p><strong>Introduction: </strong>Body mass index (BMI) is inadequately recorded in US administrative claims databases. We aimed to validate the sensitivity and positive predictive value (PPV) of BMI-related diagnosis codes using an electronic medical records (EMR) claims-linked database. Additionally, we applied machine learning (ML) to identify features in US claims databases to predict obesity status.</p><p><strong>Research design and methods: </strong>This observational, retrospective analysis included 692 119 people ≥18 years of age, with ≥1 BMI reading in MarketScan Explorys Claims-EMR data (January 2013-December 2019). Claims-based obesity status was compared with EMR-based BMI (gold standard) to assess BMI-related diagnosis code sensitivity and PPV. Logistic regression (LR), penalized LR with L1 penalty (Least Absolute Shrinkage and Selection Operator), extreme gradient boosting (XGBoost) and random forest, with features drawn from insurance claims, were trained to predict obesity status (BMI≥30 kg/m<sup>2</sup>) from EMR as the gold standard. Model performance was compared using several metrics, including the area under the receiver operating characteristic curve. The best-performing model was applied to assess feature importance. Obesity risk scores were computed from the best model generated from the claims database and compared against the BMI recorded in the EMR.</p><p><strong>Results: </strong>The PPV of diagnosis codes from claims alone remained high over the study period (85.4-89.2%); sensitivity was low (16.8-44.8%). XGBoost performed the best at predicting obesity with the highest area under the curve (AUC; 79.4%) and the lowest Brier score. The number of obesity diagnoses and obesity diagnoses from inpatient settings were the most important predictors of obesity. XGBoost showed an AUC of 74.1% when trained without an obesity diagnosis.</p><p><strong>Conclusions: </strong>Obesity prevalence is under-reported in claims databases. ML models, with or without explicit obesity, show promise in improving obesity prediction accuracy compared with obesity codes alone. Improved obesity status prediction may assist practitioners and payors to estimate the burden of obesity and investigate the potential unmet needs of current treatments.</p>","PeriodicalId":9151,"journal":{"name":"BMJ Open Diabetes Research & Care","volume":"12 5","pages":""},"PeriodicalIF":4.1000,"publicationDate":"2024-09-26","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC11429277/pdf/","citationCount":"0","resultStr":"{\"title\":\"Applying machine learning approaches for predicting obesity risk using US health administrative claims database.\",\"authors\":\"Casey Choong, Alan Brnabic, Chanadda Chinthammit, Meena Ravuri, Kendra Terrell, Hong Kan\",\"doi\":\"10.1136/bmjdrc-2024-004193\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><strong>Introduction: </strong>Body mass index (BMI) is inadequately recorded in US administrative claims databases. We aimed to validate the sensitivity and positive predictive value (PPV) of BMI-related diagnosis codes using an electronic medical records (EMR) claims-linked database. Additionally, we applied machine learning (ML) to identify features in US claims databases to predict obesity status.</p><p><strong>Research design and methods: </strong>This observational, retrospective analysis included 692 119 people ≥18 years of age, with ≥1 BMI reading in MarketScan Explorys Claims-EMR data (January 2013-December 2019). Claims-based obesity status was compared with EMR-based BMI (gold standard) to assess BMI-related diagnosis code sensitivity and PPV. Logistic regression (LR), penalized LR with L1 penalty (Least Absolute Shrinkage and Selection Operator), extreme gradient boosting (XGBoost) and random forest, with features drawn from insurance claims, were trained to predict obesity status (BMI≥30 kg/m<sup>2</sup>) from EMR as the gold standard. Model performance was compared using several metrics, including the area under the receiver operating characteristic curve. The best-performing model was applied to assess feature importance. Obesity risk scores were computed from the best model generated from the claims database and compared against the BMI recorded in the EMR.</p><p><strong>Results: </strong>The PPV of diagnosis codes from claims alone remained high over the study period (85.4-89.2%); sensitivity was low (16.8-44.8%). XGBoost performed the best at predicting obesity with the highest area under the curve (AUC; 79.4%) and the lowest Brier score. The number of obesity diagnoses and obesity diagnoses from inpatient settings were the most important predictors of obesity. XGBoost showed an AUC of 74.1% when trained without an obesity diagnosis.</p><p><strong>Conclusions: </strong>Obesity prevalence is under-reported in claims databases. ML models, with or without explicit obesity, show promise in improving obesity prediction accuracy compared with obesity codes alone. Improved obesity status prediction may assist practitioners and payors to estimate the burden of obesity and investigate the potential unmet needs of current treatments.</p>\",\"PeriodicalId\":9151,\"journal\":{\"name\":\"BMJ Open Diabetes Research & Care\",\"volume\":\"12 5\",\"pages\":\"\"},\"PeriodicalIF\":4.1000,\"publicationDate\":\"2024-09-26\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC11429277/pdf/\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"BMJ Open Diabetes Research & Care\",\"FirstCategoryId\":\"3\",\"ListUrlMain\":\"https://doi.org/10.1136/bmjdrc-2024-004193\",\"RegionNum\":2,\"RegionCategory\":\"医学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q2\",\"JCRName\":\"ENDOCRINOLOGY & METABOLISM\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"BMJ Open Diabetes Research & Care","FirstCategoryId":"3","ListUrlMain":"https://doi.org/10.1136/bmjdrc-2024-004193","RegionNum":2,"RegionCategory":"医学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q2","JCRName":"ENDOCRINOLOGY & METABOLISM","Score":null,"Total":0}
Applying machine learning approaches for predicting obesity risk using US health administrative claims database.
Introduction: Body mass index (BMI) is inadequately recorded in US administrative claims databases. We aimed to validate the sensitivity and positive predictive value (PPV) of BMI-related diagnosis codes using an electronic medical records (EMR) claims-linked database. Additionally, we applied machine learning (ML) to identify features in US claims databases to predict obesity status.
Research design and methods: This observational, retrospective analysis included 692 119 people ≥18 years of age, with ≥1 BMI reading in MarketScan Explorys Claims-EMR data (January 2013-December 2019). Claims-based obesity status was compared with EMR-based BMI (gold standard) to assess BMI-related diagnosis code sensitivity and PPV. Logistic regression (LR), penalized LR with L1 penalty (Least Absolute Shrinkage and Selection Operator), extreme gradient boosting (XGBoost) and random forest, with features drawn from insurance claims, were trained to predict obesity status (BMI≥30 kg/m2) from EMR as the gold standard. Model performance was compared using several metrics, including the area under the receiver operating characteristic curve. The best-performing model was applied to assess feature importance. Obesity risk scores were computed from the best model generated from the claims database and compared against the BMI recorded in the EMR.
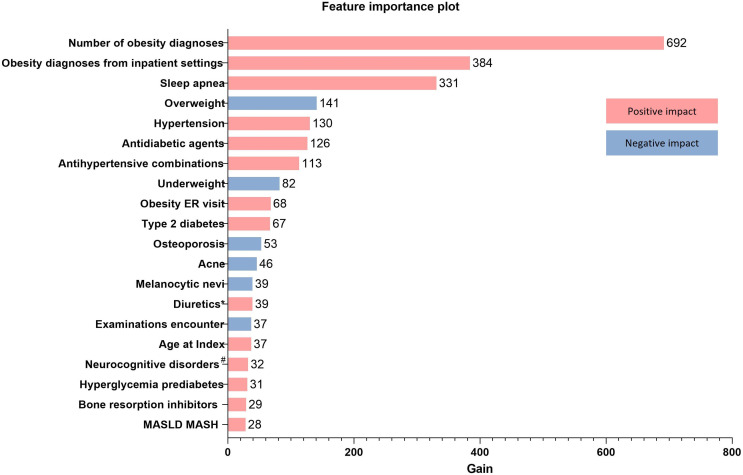
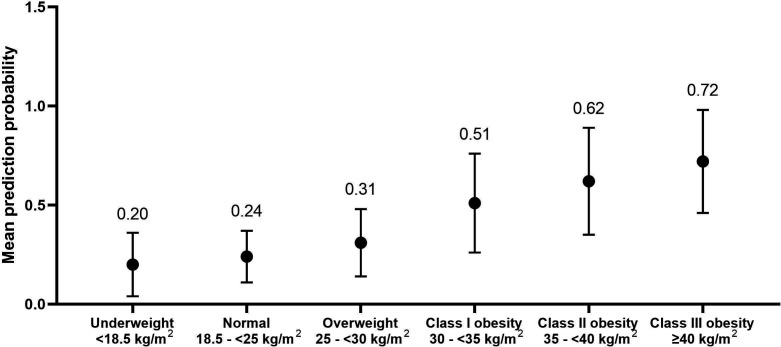
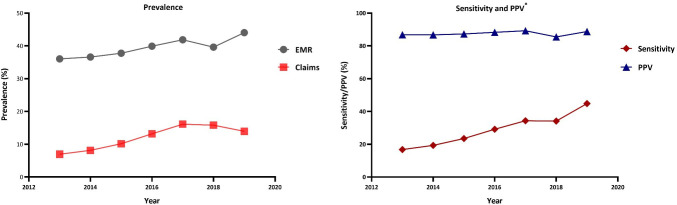
Results: The PPV of diagnosis codes from claims alone remained high over the study period (85.4-89.2%); sensitivity was low (16.8-44.8%). XGBoost performed the best at predicting obesity with the highest area under the curve (AUC; 79.4%) and the lowest Brier score. The number of obesity diagnoses and obesity diagnoses from inpatient settings were the most important predictors of obesity. XGBoost showed an AUC of 74.1% when trained without an obesity diagnosis.
Conclusions: Obesity prevalence is under-reported in claims databases. ML models, with or without explicit obesity, show promise in improving obesity prediction accuracy compared with obesity codes alone. Improved obesity status prediction may assist practitioners and payors to estimate the burden of obesity and investigate the potential unmet needs of current treatments.
期刊介绍:
BMJ Open Diabetes Research & Care is an open access journal committed to publishing high-quality, basic and clinical research articles regarding type 1 and type 2 diabetes, and associated complications. Only original content will be accepted, and submissions are subject to rigorous peer review to ensure the publication of
high-quality — and evidence-based — original research articles.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


