{"title":"利用机器学习对高熵合金和非晶态金属合金进行预测建模。","authors":"Son Gyo Jung, Guwon Jung, Jacqueline M Cole","doi":"10.1021/acs.jcim.4c00873","DOIUrl":null,"url":null,"abstract":"<p><p>High entropy alloys and amorphous metallic alloys represent two distinct classes of advanced alloy materials, each with unique structural characteristics. Their emergence has garnered considerable interest across the materials science and engineering communities, driven by their promising properties, including exceptional strength. However, their extensive compositional diversity poses substantial challenges for systematic exploration, as traditional experimental approaches and high-throughput calculations struggle to efficiently navigate this vast space. While the recent development in data-driven materials discovery could potentially help, such efforts are hindered by the scarcity of comprehensive data and the lack of robust predictive tools that can effectively link alloy composition with specific properties. To address these challenges, we have deployed a machine-learning-based workflow for feature selection and statistical analysis to afford predictive models that accelerate the data-driven discovery and optimization of these advanced materials. Our methodology is validated through two case studies: (i) a regression analysis of the bulk modulus, and (ii) a classification analysis based on glass-forming ability. The Bayesian-optimized regression model trained for the prediction of bulk modulus achieved an <i>R</i><sup>2</sup> of 0.969, an mean absolute error (MAE) of 3.958 GPa, and an root mean square error (RMSE) of 5.411 GPa, while our classification model for predicting glass-forming ability achieved an F1-score of 0.91, an area-under-the-curve of the receiver-operating-characteristic curve of 0.98, and an accuracy of 0.91. Furthermore, by leveraging a wide array of chemical data from diverse literature sources, we have successfully predicted a broad range of properties. This success underscores the efficacy of our modeling approach and emphasizes the importance of a comprehensive feature analysis and judicious feature selection strategy over a mere reliance on complex modeling techniques.</p>","PeriodicalId":44,"journal":{"name":"Journal of Chemical Information and Modeling ","volume":" ","pages":"7313-7336"},"PeriodicalIF":5.3000,"publicationDate":"2024-10-14","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC11480990/pdf/","citationCount":"0","resultStr":"{\"title\":\"Predictive Modeling of High-Entropy Alloys and Amorphous Metallic Alloys Using Machine Learning.\",\"authors\":\"Son Gyo Jung, Guwon Jung, Jacqueline M Cole\",\"doi\":\"10.1021/acs.jcim.4c00873\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><p>High entropy alloys and amorphous metallic alloys represent two distinct classes of advanced alloy materials, each with unique structural characteristics. Their emergence has garnered considerable interest across the materials science and engineering communities, driven by their promising properties, including exceptional strength. However, their extensive compositional diversity poses substantial challenges for systematic exploration, as traditional experimental approaches and high-throughput calculations struggle to efficiently navigate this vast space. While the recent development in data-driven materials discovery could potentially help, such efforts are hindered by the scarcity of comprehensive data and the lack of robust predictive tools that can effectively link alloy composition with specific properties. To address these challenges, we have deployed a machine-learning-based workflow for feature selection and statistical analysis to afford predictive models that accelerate the data-driven discovery and optimization of these advanced materials. Our methodology is validated through two case studies: (i) a regression analysis of the bulk modulus, and (ii) a classification analysis based on glass-forming ability. The Bayesian-optimized regression model trained for the prediction of bulk modulus achieved an <i>R</i><sup>2</sup> of 0.969, an mean absolute error (MAE) of 3.958 GPa, and an root mean square error (RMSE) of 5.411 GPa, while our classification model for predicting glass-forming ability achieved an F1-score of 0.91, an area-under-the-curve of the receiver-operating-characteristic curve of 0.98, and an accuracy of 0.91. Furthermore, by leveraging a wide array of chemical data from diverse literature sources, we have successfully predicted a broad range of properties. This success underscores the efficacy of our modeling approach and emphasizes the importance of a comprehensive feature analysis and judicious feature selection strategy over a mere reliance on complex modeling techniques.</p>\",\"PeriodicalId\":44,\"journal\":{\"name\":\"Journal of Chemical Information and Modeling \",\"volume\":\" \",\"pages\":\"7313-7336\"},\"PeriodicalIF\":5.3000,\"publicationDate\":\"2024-10-14\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC11480990/pdf/\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Journal of Chemical Information and Modeling \",\"FirstCategoryId\":\"92\",\"ListUrlMain\":\"https://doi.org/10.1021/acs.jcim.4c00873\",\"RegionNum\":2,\"RegionCategory\":\"化学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"2024/10/1 0:00:00\",\"PubModel\":\"Epub\",\"JCR\":\"Q1\",\"JCRName\":\"CHEMISTRY, MEDICINAL\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Journal of Chemical Information and Modeling ","FirstCategoryId":"92","ListUrlMain":"https://doi.org/10.1021/acs.jcim.4c00873","RegionNum":2,"RegionCategory":"化学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2024/10/1 0:00:00","PubModel":"Epub","JCR":"Q1","JCRName":"CHEMISTRY, MEDICINAL","Score":null,"Total":0}
Predictive Modeling of High-Entropy Alloys and Amorphous Metallic Alloys Using Machine Learning.
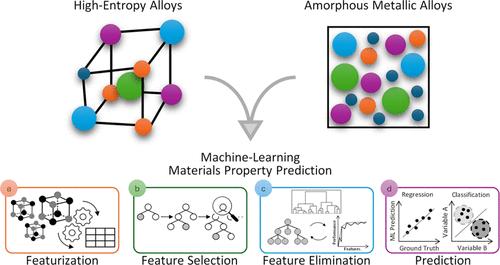
High entropy alloys and amorphous metallic alloys represent two distinct classes of advanced alloy materials, each with unique structural characteristics. Their emergence has garnered considerable interest across the materials science and engineering communities, driven by their promising properties, including exceptional strength. However, their extensive compositional diversity poses substantial challenges for systematic exploration, as traditional experimental approaches and high-throughput calculations struggle to efficiently navigate this vast space. While the recent development in data-driven materials discovery could potentially help, such efforts are hindered by the scarcity of comprehensive data and the lack of robust predictive tools that can effectively link alloy composition with specific properties. To address these challenges, we have deployed a machine-learning-based workflow for feature selection and statistical analysis to afford predictive models that accelerate the data-driven discovery and optimization of these advanced materials. Our methodology is validated through two case studies: (i) a regression analysis of the bulk modulus, and (ii) a classification analysis based on glass-forming ability. The Bayesian-optimized regression model trained for the prediction of bulk modulus achieved an R2 of 0.969, an mean absolute error (MAE) of 3.958 GPa, and an root mean square error (RMSE) of 5.411 GPa, while our classification model for predicting glass-forming ability achieved an F1-score of 0.91, an area-under-the-curve of the receiver-operating-characteristic curve of 0.98, and an accuracy of 0.91. Furthermore, by leveraging a wide array of chemical data from diverse literature sources, we have successfully predicted a broad range of properties. This success underscores the efficacy of our modeling approach and emphasizes the importance of a comprehensive feature analysis and judicious feature selection strategy over a mere reliance on complex modeling techniques.
期刊介绍:
The Journal of Chemical Information and Modeling publishes papers reporting new methodology and/or important applications in the fields of chemical informatics and molecular modeling. Specific topics include the representation and computer-based searching of chemical databases, molecular modeling, computer-aided molecular design of new materials, catalysts, or ligands, development of new computational methods or efficient algorithms for chemical software, and biopharmaceutical chemistry including analyses of biological activity and other issues related to drug discovery.
Astute chemists, computer scientists, and information specialists look to this monthly’s insightful research studies, programming innovations, and software reviews to keep current with advances in this integral, multidisciplinary field.
As a subscriber you’ll stay abreast of database search systems, use of graph theory in chemical problems, substructure search systems, pattern recognition and clustering, analysis of chemical and physical data, molecular modeling, graphics and natural language interfaces, bibliometric and citation analysis, and synthesis design and reactions databases.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


