{"title":"基于机器学习的高血糖预测:加强未确诊人群的风险评估。","authors":"Kolapo Oyebola, Funmilayo Ligali, Afolabi Owoloye, Blessing Erinwusi, Yetunde Alo, Adesola Z Musa, Oluwagbemiga Aina, Babatunde Salako","doi":"10.2196/56993","DOIUrl":null,"url":null,"abstract":"<p><strong>Background: </strong>Noncommunicable diseases continue to pose a substantial health challenge globally, with hyperglycemia serving as a prominent indicator of diabetes.</p><p><strong>Objective: </strong>This study employed machine learning algorithms to predict hyperglycemia in a cohort of individuals who were asymptomatic and unraveled crucial predictors contributing to early risk identification.</p><p><strong>Methods: </strong>This dataset included an extensive array of clinical and demographic data obtained from 195 adults who were asymptomatic and residing in a suburban community in Nigeria. The study conducted a thorough comparison of multiple machine learning algorithms to ascertain the most effective model for predicting hyperglycemia. Moreover, we explored feature importance to pinpoint correlates of high blood glucose levels within the cohort.</p><p><strong>Results: </strong>Elevated blood pressure and prehypertension were recorded in 8 (4.1%) and 18 (9.2%) of the 195 participants, respectively. A total of 41 (21%) participants presented with hypertension, of which 34 (83%) were female. However, sex adjustment showed that 34 of 118 (28.8%) female participants and 7 of 77 (9%) male participants had hypertension. Age-based analysis revealed an inverse relationship between normotension and age (r=-0.88; P=.02). Conversely, hypertension increased with age (r=0.53; P=.27), peaking between 50-59 years. Of the 195 participants, isolated systolic hypertension and isolated diastolic hypertension were recorded in 16 (8.2%) and 15 (7.7%) participants, respectively, with female participants recording a higher prevalence of isolated systolic hypertension (11/16, 69%) and male participants reporting a higher prevalence of isolated diastolic hypertension (11/15, 73%). Following class rebalancing, the random forest classifier gave the best performance (accuracy score 0.89; receiver operating characteristic-area under the curve score 0.89; F1-score 0.89) of the 26 model classifiers. The feature selection model identified uric acid and age as important variables associated with hyperglycemia.</p><p><strong>Conclusions: </strong>The random forest classifier identified significant clinical correlates associated with hyperglycemia, offering valuable insights for the early detection of diabetes and informing the design and deployment of therapeutic interventions. However, to achieve a more comprehensive understanding of each feature's contribution to blood glucose levels, modeling additional relevant clinical features in larger datasets could be beneficial.</p>","PeriodicalId":73558,"journal":{"name":"JMIRx med","volume":"5 ","pages":"e56993"},"PeriodicalIF":0.0000,"publicationDate":"2024-09-11","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC11441453/pdf/","citationCount":"0","resultStr":"{\"title\":\"Machine Learning-Based Hyperglycemia Prediction: Enhancing Risk Assessment in a Cohort of Undiagnosed Individuals.\",\"authors\":\"Kolapo Oyebola, Funmilayo Ligali, Afolabi Owoloye, Blessing Erinwusi, Yetunde Alo, Adesola Z Musa, Oluwagbemiga Aina, Babatunde Salako\",\"doi\":\"10.2196/56993\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><strong>Background: </strong>Noncommunicable diseases continue to pose a substantial health challenge globally, with hyperglycemia serving as a prominent indicator of diabetes.</p><p><strong>Objective: </strong>This study employed machine learning algorithms to predict hyperglycemia in a cohort of individuals who were asymptomatic and unraveled crucial predictors contributing to early risk identification.</p><p><strong>Methods: </strong>This dataset included an extensive array of clinical and demographic data obtained from 195 adults who were asymptomatic and residing in a suburban community in Nigeria. The study conducted a thorough comparison of multiple machine learning algorithms to ascertain the most effective model for predicting hyperglycemia. Moreover, we explored feature importance to pinpoint correlates of high blood glucose levels within the cohort.</p><p><strong>Results: </strong>Elevated blood pressure and prehypertension were recorded in 8 (4.1%) and 18 (9.2%) of the 195 participants, respectively. A total of 41 (21%) participants presented with hypertension, of which 34 (83%) were female. However, sex adjustment showed that 34 of 118 (28.8%) female participants and 7 of 77 (9%) male participants had hypertension. Age-based analysis revealed an inverse relationship between normotension and age (r=-0.88; P=.02). Conversely, hypertension increased with age (r=0.53; P=.27), peaking between 50-59 years. Of the 195 participants, isolated systolic hypertension and isolated diastolic hypertension were recorded in 16 (8.2%) and 15 (7.7%) participants, respectively, with female participants recording a higher prevalence of isolated systolic hypertension (11/16, 69%) and male participants reporting a higher prevalence of isolated diastolic hypertension (11/15, 73%). Following class rebalancing, the random forest classifier gave the best performance (accuracy score 0.89; receiver operating characteristic-area under the curve score 0.89; F1-score 0.89) of the 26 model classifiers. The feature selection model identified uric acid and age as important variables associated with hyperglycemia.</p><p><strong>Conclusions: </strong>The random forest classifier identified significant clinical correlates associated with hyperglycemia, offering valuable insights for the early detection of diabetes and informing the design and deployment of therapeutic interventions. However, to achieve a more comprehensive understanding of each feature's contribution to blood glucose levels, modeling additional relevant clinical features in larger datasets could be beneficial.</p>\",\"PeriodicalId\":73558,\"journal\":{\"name\":\"JMIRx med\",\"volume\":\"5 \",\"pages\":\"e56993\"},\"PeriodicalIF\":0.0000,\"publicationDate\":\"2024-09-11\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC11441453/pdf/\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"JMIRx med\",\"FirstCategoryId\":\"1085\",\"ListUrlMain\":\"https://doi.org/10.2196/56993\",\"RegionNum\":0,\"RegionCategory\":null,\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"\",\"JCRName\":\"\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"JMIRx med","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.2196/56993","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"","JCRName":"","Score":null,"Total":0}
Machine Learning-Based Hyperglycemia Prediction: Enhancing Risk Assessment in a Cohort of Undiagnosed Individuals.
Background: Noncommunicable diseases continue to pose a substantial health challenge globally, with hyperglycemia serving as a prominent indicator of diabetes.
Objective: This study employed machine learning algorithms to predict hyperglycemia in a cohort of individuals who were asymptomatic and unraveled crucial predictors contributing to early risk identification.
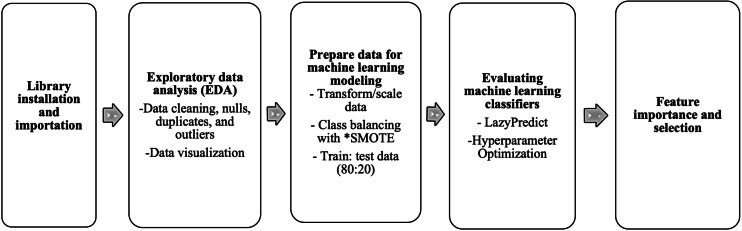
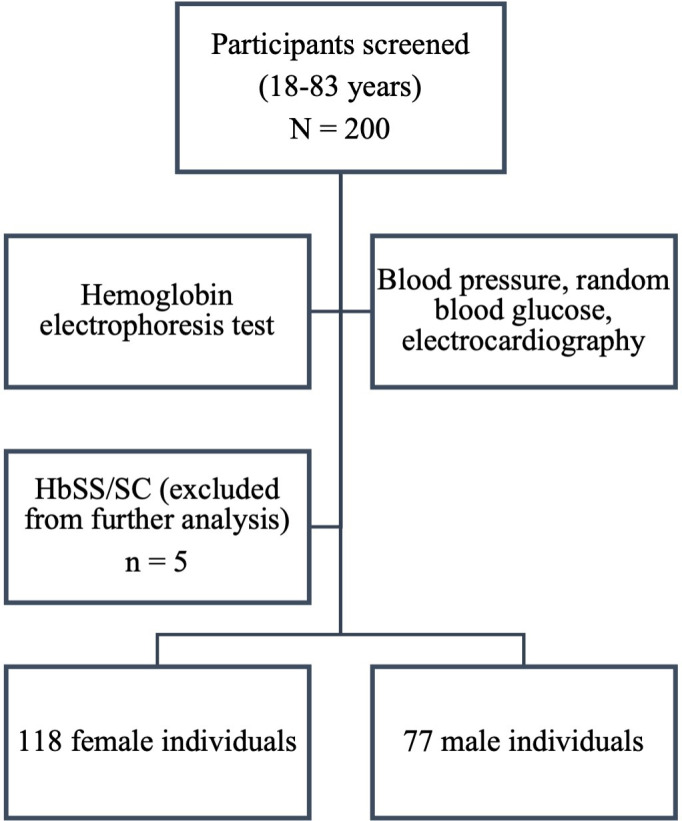
Methods: This dataset included an extensive array of clinical and demographic data obtained from 195 adults who were asymptomatic and residing in a suburban community in Nigeria. The study conducted a thorough comparison of multiple machine learning algorithms to ascertain the most effective model for predicting hyperglycemia. Moreover, we explored feature importance to pinpoint correlates of high blood glucose levels within the cohort.
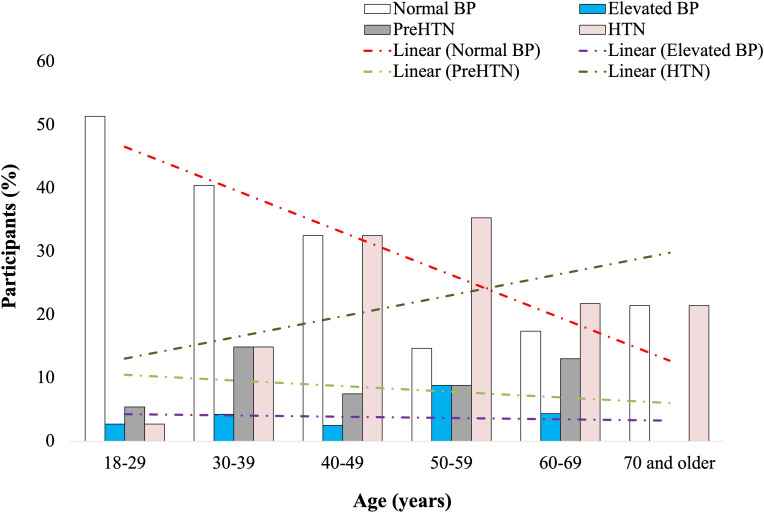
Results: Elevated blood pressure and prehypertension were recorded in 8 (4.1%) and 18 (9.2%) of the 195 participants, respectively. A total of 41 (21%) participants presented with hypertension, of which 34 (83%) were female. However, sex adjustment showed that 34 of 118 (28.8%) female participants and 7 of 77 (9%) male participants had hypertension. Age-based analysis revealed an inverse relationship between normotension and age (r=-0.88; P=.02). Conversely, hypertension increased with age (r=0.53; P=.27), peaking between 50-59 years. Of the 195 participants, isolated systolic hypertension and isolated diastolic hypertension were recorded in 16 (8.2%) and 15 (7.7%) participants, respectively, with female participants recording a higher prevalence of isolated systolic hypertension (11/16, 69%) and male participants reporting a higher prevalence of isolated diastolic hypertension (11/15, 73%). Following class rebalancing, the random forest classifier gave the best performance (accuracy score 0.89; receiver operating characteristic-area under the curve score 0.89; F1-score 0.89) of the 26 model classifiers. The feature selection model identified uric acid and age as important variables associated with hyperglycemia.
Conclusions: The random forest classifier identified significant clinical correlates associated with hyperglycemia, offering valuable insights for the early detection of diabetes and informing the design and deployment of therapeutic interventions. However, to achieve a more comprehensive understanding of each feature's contribution to blood glucose levels, modeling additional relevant clinical features in larger datasets could be beneficial.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


