Natalia Zurek , Yi Zhang , Dermot P.B. McGovern , Ann E. Walts , Arkadiusz Gertych
{"title":"免疫组化注释增强了炎症性肠病数字化 H&E 切片中淋巴细胞和中性粒细胞的 AI 识别能力","authors":"Natalia Zurek , Yi Zhang , Dermot P.B. McGovern , Ann E. Walts , Arkadiusz Gertych","doi":"10.1016/j.cmpb.2024.108423","DOIUrl":null,"url":null,"abstract":"<div><h3>Background and Objective</h3><p>Histologic assessment of the immune infiltrate in H&E slides is vital in diagnosing and managing inflammatory bowel diseases, but these assessments are subjective and time-consuming even for those with expertise. The development of deep learning models to aid in these assessments has been limited by the paucity of image data with reliably annotated immune cells available for training.</p></div><div><h3>Methods</h3><p>To address these challenges, we developed a pipeline that automates the neutrophil and lymphocyte labeling in ROIs from digital H&E slides. The data included ROIs extracted from 19 digitized H&E slides and the same slides restained with immunohistochemistry. Our pipeline first delineates each nucleus in H&E ROIs. Using the colorimetric features of the immunohistochemical stains (red: neutrophils, green: lymphocytes) in the immunohistochemistry ROIs, each cell was labeled as a neutrophil, a lymphocyte, or another cell. The labels were then transferred to the corresponding H&E ROIs by image registration, and the ROI registration accuracy was assessed by the median target registration error resulting in a labeled dataset. The newly formed dataset (NeuLy-IHC) comprising 519 ROIs with 235,256 labeled cells (74,339 lymphocytes, 16,326 neutrophils and 144,591 other cells) was used to train the HoVer-Net<sup>(NeuLy)</sup> model. The performance of HoVer-Net<sup>(NeuLy)</sup> measured by DICE coefficient (segmentation accuracy) and F1-scores (classification accuracy), was compared to those achieved by HoVer-Net<sup>(MoNuSAC)</sup> and SMILE<sup>(MoNuSAC)</sup> publicly available models trained on cancer-containing ROIs from the MoNuSAC dataset with manual cell labeling and pathologists’ annotations.</p></div><div><h3>Results</h3><p>The 1.0 μm median target registration error of ROIs observed was low demonstrating robust transferring of cellular labels from immunohistochemistry ROIs to H&E ROIs. In the test set comprising 76 NeuLy-IHC and 78 MoNuSAC ROIs, the HoVer-Net<sup>(NeuLy)</sup> achieved a DICE coefficient of 0.861 and F1-sores of 0.827, 0.838, and 0.828, for neutrophils, lymphocytes, and other cells, respectively, outperforming the HoVer-Net<sup>(MoNuSAC)</sup>'s and SMILE<sup>(MoNuSAC)</sup>’s DICE coefficient and F1 scores for each cell category.</p></div><div><h3>Conclusions</h3><p>We attribute the improved performance of HoVer-Net<sup>(NeuLy)</sup> to the larger number of immune cells in the NeuLy-IHC dataset (in total 5x more, including 21x more neutrophils) than in the MoNuSAC dataset. Despite being trained on data from inflammatory bowel disease specimens, our model maintained robust performance when tested on previously unseen data derived from cancer specimens. The NeuLy-IHC set provides opportunities for training accurate models to quantify the inflammatory infiltrate in digital histologic slides.</p></div>","PeriodicalId":10624,"journal":{"name":"Computer methods and programs in biomedicine","volume":"257 ","pages":"Article 108423"},"PeriodicalIF":4.9000,"publicationDate":"2024-09-13","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":"{\"title\":\"Immunohistochemistry annotations enhance AI identification of lymphocytes and neutrophils in digitized H&E slides from inflammatory bowel disease\",\"authors\":\"Natalia Zurek , Yi Zhang , Dermot P.B. McGovern , Ann E. Walts , Arkadiusz Gertych\",\"doi\":\"10.1016/j.cmpb.2024.108423\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<div><h3>Background and Objective</h3><p>Histologic assessment of the immune infiltrate in H&E slides is vital in diagnosing and managing inflammatory bowel diseases, but these assessments are subjective and time-consuming even for those with expertise. The development of deep learning models to aid in these assessments has been limited by the paucity of image data with reliably annotated immune cells available for training.</p></div><div><h3>Methods</h3><p>To address these challenges, we developed a pipeline that automates the neutrophil and lymphocyte labeling in ROIs from digital H&E slides. The data included ROIs extracted from 19 digitized H&E slides and the same slides restained with immunohistochemistry. Our pipeline first delineates each nucleus in H&E ROIs. Using the colorimetric features of the immunohistochemical stains (red: neutrophils, green: lymphocytes) in the immunohistochemistry ROIs, each cell was labeled as a neutrophil, a lymphocyte, or another cell. The labels were then transferred to the corresponding H&E ROIs by image registration, and the ROI registration accuracy was assessed by the median target registration error resulting in a labeled dataset. The newly formed dataset (NeuLy-IHC) comprising 519 ROIs with 235,256 labeled cells (74,339 lymphocytes, 16,326 neutrophils and 144,591 other cells) was used to train the HoVer-Net<sup>(NeuLy)</sup> model. The performance of HoVer-Net<sup>(NeuLy)</sup> measured by DICE coefficient (segmentation accuracy) and F1-scores (classification accuracy), was compared to those achieved by HoVer-Net<sup>(MoNuSAC)</sup> and SMILE<sup>(MoNuSAC)</sup> publicly available models trained on cancer-containing ROIs from the MoNuSAC dataset with manual cell labeling and pathologists’ annotations.</p></div><div><h3>Results</h3><p>The 1.0 μm median target registration error of ROIs observed was low demonstrating robust transferring of cellular labels from immunohistochemistry ROIs to H&E ROIs. In the test set comprising 76 NeuLy-IHC and 78 MoNuSAC ROIs, the HoVer-Net<sup>(NeuLy)</sup> achieved a DICE coefficient of 0.861 and F1-sores of 0.827, 0.838, and 0.828, for neutrophils, lymphocytes, and other cells, respectively, outperforming the HoVer-Net<sup>(MoNuSAC)</sup>'s and SMILE<sup>(MoNuSAC)</sup>’s DICE coefficient and F1 scores for each cell category.</p></div><div><h3>Conclusions</h3><p>We attribute the improved performance of HoVer-Net<sup>(NeuLy)</sup> to the larger number of immune cells in the NeuLy-IHC dataset (in total 5x more, including 21x more neutrophils) than in the MoNuSAC dataset. Despite being trained on data from inflammatory bowel disease specimens, our model maintained robust performance when tested on previously unseen data derived from cancer specimens. The NeuLy-IHC set provides opportunities for training accurate models to quantify the inflammatory infiltrate in digital histologic slides.</p></div>\",\"PeriodicalId\":10624,\"journal\":{\"name\":\"Computer methods and programs in biomedicine\",\"volume\":\"257 \",\"pages\":\"Article 108423\"},\"PeriodicalIF\":4.9000,\"publicationDate\":\"2024-09-13\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Computer methods and programs in biomedicine\",\"FirstCategoryId\":\"5\",\"ListUrlMain\":\"https://www.sciencedirect.com/science/article/pii/S0169260724004164\",\"RegionNum\":2,\"RegionCategory\":\"医学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q1\",\"JCRName\":\"COMPUTER SCIENCE, INTERDISCIPLINARY APPLICATIONS\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Computer methods and programs in biomedicine","FirstCategoryId":"5","ListUrlMain":"https://www.sciencedirect.com/science/article/pii/S0169260724004164","RegionNum":2,"RegionCategory":"医学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"COMPUTER SCIENCE, INTERDISCIPLINARY APPLICATIONS","Score":null,"Total":0}
引用次数: 0
摘要
背景和目的对 H&E 切片中的免疫浸润进行组织学评估对于诊断和管理炎症性肠病至关重要,但这些评估既主观又耗时,即使是对具有专业知识的人来说也是如此。为了应对这些挑战,我们开发了一个管道,可以自动对数字 H&E 切片 ROI 中的中性粒细胞和淋巴细胞进行标记。数据包括从 19 张数字化 H&E 切片中提取的 ROI,以及经免疫组化染色的相同切片。我们的工作流程首先在 H&E ROI 中划分出每个细胞核。利用免疫组化 ROI 中免疫组化染色的比色特征(红色:中性粒细胞,绿色:淋巴细胞),将每个细胞标记为中性粒细胞、淋巴细胞或其他细胞。然后通过图像配准将标签转移到相应的 H&E ROI 上,并通过目标配准误差的中位数评估 ROI 配对的准确性,最后得到一个已标记的数据集。新形成的数据集(NeuLy-IHC)包括 519 个 ROI 和 235,256 个标记细胞(74,339 个淋巴细胞、16,326 个中性粒细胞和 144,591 个其他细胞),用于训练 HoVer-Net(NeuLy)模型。用 DICE 系数(分割准确率)和 F1 分数(分类准确率)来衡量 HoVer-Net(NeuLy) 的性能,并将其与 HoVer-Net(MoNuSAC) 和 SMILE(MoNuSAC) 公开发布的模型的性能进行比较。结果 观察到的 ROI 的 1.0 μm 中位目标注册误差很低,这表明细胞标签从免疫组化 ROI 转移到 H&E ROI 的能力很强。在由 76 个 NeuLy-IHC 和 78 个 MoNuSAC ROI 组成的测试集中,HoVer-Net(NeuLy) 的中性粒细胞、淋巴细胞和其他细胞的 DICE 系数为 0.861,F1 值分别为 0.827、0.838 和 0.828,优于 HoVer-Net(MoNuSAC) 和 SMILE(MoNuSAC) 的每个细胞类别的 DICE 系数和 F1 值。结论我们认为,HoVer-Net(NeuLy) 性能的提高是由于 NeuLy-IHC 数据集中的免疫细胞数量比 MoNuSAC 数据集中的免疫细胞数量多(总共多 5 倍,其中中性粒细胞多 21 倍)。尽管我们的模型是在炎症性肠病标本数据的基础上进行训练的,但在对以前未见过的癌症标本数据进行测试时,我们的模型仍然保持了强劲的性能。NeuLy-IHC 数据集提供了训练精确模型的机会,以量化数字组织学切片中的炎症浸润。
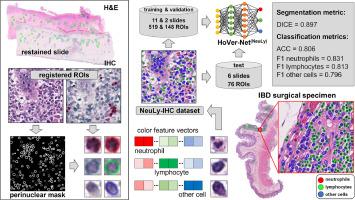
Immunohistochemistry annotations enhance AI identification of lymphocytes and neutrophils in digitized H&E slides from inflammatory bowel disease
Background and Objective
Histologic assessment of the immune infiltrate in H&E slides is vital in diagnosing and managing inflammatory bowel diseases, but these assessments are subjective and time-consuming even for those with expertise. The development of deep learning models to aid in these assessments has been limited by the paucity of image data with reliably annotated immune cells available for training.
Methods
To address these challenges, we developed a pipeline that automates the neutrophil and lymphocyte labeling in ROIs from digital H&E slides. The data included ROIs extracted from 19 digitized H&E slides and the same slides restained with immunohistochemistry. Our pipeline first delineates each nucleus in H&E ROIs. Using the colorimetric features of the immunohistochemical stains (red: neutrophils, green: lymphocytes) in the immunohistochemistry ROIs, each cell was labeled as a neutrophil, a lymphocyte, or another cell. The labels were then transferred to the corresponding H&E ROIs by image registration, and the ROI registration accuracy was assessed by the median target registration error resulting in a labeled dataset. The newly formed dataset (NeuLy-IHC) comprising 519 ROIs with 235,256 labeled cells (74,339 lymphocytes, 16,326 neutrophils and 144,591 other cells) was used to train the HoVer-Net(NeuLy) model. The performance of HoVer-Net(NeuLy) measured by DICE coefficient (segmentation accuracy) and F1-scores (classification accuracy), was compared to those achieved by HoVer-Net(MoNuSAC) and SMILE(MoNuSAC) publicly available models trained on cancer-containing ROIs from the MoNuSAC dataset with manual cell labeling and pathologists’ annotations.
Results
The 1.0 μm median target registration error of ROIs observed was low demonstrating robust transferring of cellular labels from immunohistochemistry ROIs to H&E ROIs. In the test set comprising 76 NeuLy-IHC and 78 MoNuSAC ROIs, the HoVer-Net(NeuLy) achieved a DICE coefficient of 0.861 and F1-sores of 0.827, 0.838, and 0.828, for neutrophils, lymphocytes, and other cells, respectively, outperforming the HoVer-Net(MoNuSAC)'s and SMILE(MoNuSAC)’s DICE coefficient and F1 scores for each cell category.
Conclusions
We attribute the improved performance of HoVer-Net(NeuLy) to the larger number of immune cells in the NeuLy-IHC dataset (in total 5x more, including 21x more neutrophils) than in the MoNuSAC dataset. Despite being trained on data from inflammatory bowel disease specimens, our model maintained robust performance when tested on previously unseen data derived from cancer specimens. The NeuLy-IHC set provides opportunities for training accurate models to quantify the inflammatory infiltrate in digital histologic slides.
期刊介绍:
To encourage the development of formal computing methods, and their application in biomedical research and medical practice, by illustration of fundamental principles in biomedical informatics research; to stimulate basic research into application software design; to report the state of research of biomedical information processing projects; to report new computer methodologies applied in biomedical areas; the eventual distribution of demonstrable software to avoid duplication of effort; to provide a forum for discussion and improvement of existing software; to optimize contact between national organizations and regional user groups by promoting an international exchange of information on formal methods, standards and software in biomedicine.
Computer Methods and Programs in Biomedicine covers computing methodology and software systems derived from computing science for implementation in all aspects of biomedical research and medical practice. It is designed to serve: biochemists; biologists; geneticists; immunologists; neuroscientists; pharmacologists; toxicologists; clinicians; epidemiologists; psychiatrists; psychologists; cardiologists; chemists; (radio)physicists; computer scientists; programmers and systems analysts; biomedical, clinical, electrical and other engineers; teachers of medical informatics and users of educational software.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


