{"title":"使用具有记忆增强状态空间的大型语言模型进行视频驱动的音乐创作","authors":"Wan-He Kai, Kai-Xin Xing","doi":"10.1007/s00371-024-03606-w","DOIUrl":null,"url":null,"abstract":"<p>The current landscape of research leveraging large language models (LLMs) is experiencing a surge. Many works harness the powerful reasoning capabilities of these models to comprehend various modalities, such as text, speech, images, videos, etc. However, the research work on LLms for music inspiration is still in its infancy. To fill the gap in this field and break through the dilemma that LLMs can only understand short videos with limited frames, we propose a large language model with state space for long-term video-to-music generation. To capture long-range dependency and maintaining high performance, while further decrease the computing cost, our overall network includes the Enhanced Video Mamba, which incorporates continuous moving window partitioning and local feature augmentation, and a long-term memory bank that captures and aggregates historical video information to mitigate information loss in long sequences. This framework achieves both subquadratic-time computation and near-linear memory complexity, enabling effective long-term video-to-music generation. We conduct a thorough evaluation of our proposed framework. The experimental results demonstrate that our model achieves or surpasses the performance of the current state-of-the-art models. Our code released on https://github.com/kai211233/S2L2-V2M.</p>","PeriodicalId":501186,"journal":{"name":"The Visual Computer","volume":"26 1","pages":""},"PeriodicalIF":0.0000,"publicationDate":"2024-09-18","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":"{\"title\":\"Video-driven musical composition using large language model with memory-augmented state space\",\"authors\":\"Wan-He Kai, Kai-Xin Xing\",\"doi\":\"10.1007/s00371-024-03606-w\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p>The current landscape of research leveraging large language models (LLMs) is experiencing a surge. Many works harness the powerful reasoning capabilities of these models to comprehend various modalities, such as text, speech, images, videos, etc. However, the research work on LLms for music inspiration is still in its infancy. To fill the gap in this field and break through the dilemma that LLMs can only understand short videos with limited frames, we propose a large language model with state space for long-term video-to-music generation. To capture long-range dependency and maintaining high performance, while further decrease the computing cost, our overall network includes the Enhanced Video Mamba, which incorporates continuous moving window partitioning and local feature augmentation, and a long-term memory bank that captures and aggregates historical video information to mitigate information loss in long sequences. This framework achieves both subquadratic-time computation and near-linear memory complexity, enabling effective long-term video-to-music generation. We conduct a thorough evaluation of our proposed framework. The experimental results demonstrate that our model achieves or surpasses the performance of the current state-of-the-art models. Our code released on https://github.com/kai211233/S2L2-V2M.</p>\",\"PeriodicalId\":501186,\"journal\":{\"name\":\"The Visual Computer\",\"volume\":\"26 1\",\"pages\":\"\"},\"PeriodicalIF\":0.0000,\"publicationDate\":\"2024-09-18\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"The Visual Computer\",\"FirstCategoryId\":\"1085\",\"ListUrlMain\":\"https://doi.org/10.1007/s00371-024-03606-w\",\"RegionNum\":0,\"RegionCategory\":null,\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"\",\"JCRName\":\"\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"The Visual Computer","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.1007/s00371-024-03606-w","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"","JCRName":"","Score":null,"Total":0}
引用次数: 0
摘要
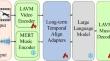
目前,利用大型语言模型(LLMs)的研究正在蓬勃发展。许多作品利用这些模型强大的推理能力来理解各种模式,如文本、语音、图像、视频等。然而,针对音乐灵感的大语言模型研究工作仍处于起步阶段。为了填补这一领域的空白,突破 LLM 只能理解帧数有限的短视频的窘境,我们提出了一种具有状态空间的大型语言模型,用于从视频到音乐的长期生成。为了捕捉长距离依赖性并保持高性能,同时进一步降低计算成本,我们的整体网络包括增强型视频曼巴(Enhanced Video Mamba),它集成了连续移动窗口分割和局部特征增强功能,以及一个长期记忆库(用于捕捉和聚合历史视频信息,以减少长序列中的信息丢失)。该框架可实现亚二次方时间计算和近线性内存复杂性,从而实现有效的长期视频到音乐生成。我们对所提出的框架进行了全面评估。实验结果表明,我们的模型达到或超过了当前最先进模型的性能。我们的代码发布于 https://github.com/kai211233/S2L2-V2M。
Video-driven musical composition using large language model with memory-augmented state space
The current landscape of research leveraging large language models (LLMs) is experiencing a surge. Many works harness the powerful reasoning capabilities of these models to comprehend various modalities, such as text, speech, images, videos, etc. However, the research work on LLms for music inspiration is still in its infancy. To fill the gap in this field and break through the dilemma that LLMs can only understand short videos with limited frames, we propose a large language model with state space for long-term video-to-music generation. To capture long-range dependency and maintaining high performance, while further decrease the computing cost, our overall network includes the Enhanced Video Mamba, which incorporates continuous moving window partitioning and local feature augmentation, and a long-term memory bank that captures and aggregates historical video information to mitigate information loss in long sequences. This framework achieves both subquadratic-time computation and near-linear memory complexity, enabling effective long-term video-to-music generation. We conduct a thorough evaluation of our proposed framework. The experimental results demonstrate that our model achieves or surpasses the performance of the current state-of-the-art models. Our code released on https://github.com/kai211233/S2L2-V2M.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


