{"title":"CSDNet:针对细粒度图像标题网络的交叉草图与双重门控注意力","authors":"Md. Shamim Hossain, Shamima Aktar, Md. Bipul Hossen, Mohammad Alamgir Hossain, Naijie Gu, Zhangjin Huang","doi":"10.1007/s11042-024-20220-z","DOIUrl":null,"url":null,"abstract":"<p>In the realm of extracting inter and intra-modal interactions, contemporary models often face challenges such as reduced computational efficiency, particularly when dealing with lengthy visual sequences. To address these issues, this study introduces an innovative model, the Cross-Sketch with Dual Gated Attention Network (CSDNet), designed to handle second-order intra- and inter-modal interactions by integrating a couple of attention modules. Leveraging bilinear pooling to effectively capture these second-order interactions typically requires substantial computational resources due to the processing of large-dimensional tensors. Due to these resource demands, the first module Cross-Sketch Attention (CSA) is proposed, which employs Cross-Tensor Sketch Pooling on attention features to reduce dimensionality while preserving crucial information without sacrificing caption quality. Furthermore, to enhance caption by integrating another novel attention module, Dual Gated Attention (DGA), which contributes additional spatial and channel-wise attention distributions to improve caption generation performance. Our method demonstrates significant computational efficiency improvements, reducing computation time per epoch by an average of 13.54% compared to the base model, which leads to expedited convergence and improved performance metrics. Additionally, we observe a 0.07% enhancement in the METEOR score compared to the base model. Through the application of reinforcement learning optimization, our model achieves a remarkable CIDEr-D score of 132.2% on the MS-COCO dataset. This consistently outperforms baseline performance across a comprehensive range of evaluation metrics.</p>","PeriodicalId":18770,"journal":{"name":"Multimedia Tools and Applications","volume":"5 1","pages":""},"PeriodicalIF":3.0000,"publicationDate":"2024-09-16","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":"{\"title\":\"CSDNet: cross-sketch with dual gated attention for fine-grained image captioning network\",\"authors\":\"Md. Shamim Hossain, Shamima Aktar, Md. Bipul Hossen, Mohammad Alamgir Hossain, Naijie Gu, Zhangjin Huang\",\"doi\":\"10.1007/s11042-024-20220-z\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p>In the realm of extracting inter and intra-modal interactions, contemporary models often face challenges such as reduced computational efficiency, particularly when dealing with lengthy visual sequences. To address these issues, this study introduces an innovative model, the Cross-Sketch with Dual Gated Attention Network (CSDNet), designed to handle second-order intra- and inter-modal interactions by integrating a couple of attention modules. Leveraging bilinear pooling to effectively capture these second-order interactions typically requires substantial computational resources due to the processing of large-dimensional tensors. Due to these resource demands, the first module Cross-Sketch Attention (CSA) is proposed, which employs Cross-Tensor Sketch Pooling on attention features to reduce dimensionality while preserving crucial information without sacrificing caption quality. Furthermore, to enhance caption by integrating another novel attention module, Dual Gated Attention (DGA), which contributes additional spatial and channel-wise attention distributions to improve caption generation performance. Our method demonstrates significant computational efficiency improvements, reducing computation time per epoch by an average of 13.54% compared to the base model, which leads to expedited convergence and improved performance metrics. Additionally, we observe a 0.07% enhancement in the METEOR score compared to the base model. Through the application of reinforcement learning optimization, our model achieves a remarkable CIDEr-D score of 132.2% on the MS-COCO dataset. This consistently outperforms baseline performance across a comprehensive range of evaluation metrics.</p>\",\"PeriodicalId\":18770,\"journal\":{\"name\":\"Multimedia Tools and Applications\",\"volume\":\"5 1\",\"pages\":\"\"},\"PeriodicalIF\":3.0000,\"publicationDate\":\"2024-09-16\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Multimedia Tools and Applications\",\"FirstCategoryId\":\"94\",\"ListUrlMain\":\"https://doi.org/10.1007/s11042-024-20220-z\",\"RegionNum\":4,\"RegionCategory\":\"计算机科学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q2\",\"JCRName\":\"COMPUTER SCIENCE, INFORMATION SYSTEMS\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Multimedia Tools and Applications","FirstCategoryId":"94","ListUrlMain":"https://doi.org/10.1007/s11042-024-20220-z","RegionNum":4,"RegionCategory":"计算机科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q2","JCRName":"COMPUTER SCIENCE, INFORMATION SYSTEMS","Score":null,"Total":0}
CSDNet: cross-sketch with dual gated attention for fine-grained image captioning network
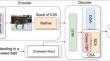
In the realm of extracting inter and intra-modal interactions, contemporary models often face challenges such as reduced computational efficiency, particularly when dealing with lengthy visual sequences. To address these issues, this study introduces an innovative model, the Cross-Sketch with Dual Gated Attention Network (CSDNet), designed to handle second-order intra- and inter-modal interactions by integrating a couple of attention modules. Leveraging bilinear pooling to effectively capture these second-order interactions typically requires substantial computational resources due to the processing of large-dimensional tensors. Due to these resource demands, the first module Cross-Sketch Attention (CSA) is proposed, which employs Cross-Tensor Sketch Pooling on attention features to reduce dimensionality while preserving crucial information without sacrificing caption quality. Furthermore, to enhance caption by integrating another novel attention module, Dual Gated Attention (DGA), which contributes additional spatial and channel-wise attention distributions to improve caption generation performance. Our method demonstrates significant computational efficiency improvements, reducing computation time per epoch by an average of 13.54% compared to the base model, which leads to expedited convergence and improved performance metrics. Additionally, we observe a 0.07% enhancement in the METEOR score compared to the base model. Through the application of reinforcement learning optimization, our model achieves a remarkable CIDEr-D score of 132.2% on the MS-COCO dataset. This consistently outperforms baseline performance across a comprehensive range of evaluation metrics.
期刊介绍:
Multimedia Tools and Applications publishes original research articles on multimedia development and system support tools as well as case studies of multimedia applications. It also features experimental and survey articles. The journal is intended for academics, practitioners, scientists and engineers who are involved in multimedia system research, design and applications. All papers are peer reviewed.
Specific areas of interest include:
- Multimedia Tools:
- Multimedia Applications:
- Prototype multimedia systems and platforms

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


