Md Mushfiqur Rahman , Mohammad Sabik Irbaz , Kai North, Michelle S. Williams, Marcos Zampieri, Kevin Lybarger
{"title":"健康文本简化:用于消化系统癌症教育的注释语料库和新的强化学习策略","authors":"Md Mushfiqur Rahman , Mohammad Sabik Irbaz , Kai North, Michelle S. Williams, Marcos Zampieri, Kevin Lybarger","doi":"10.1016/j.jbi.2024.104727","DOIUrl":null,"url":null,"abstract":"<div><h3>Objective:</h3><p>The reading level of health educational materials significantly influences the understandability and accessibility of the information, particularly for minoritized populations. Many patient educational resources surpass widely accepted standards for reading level and complexity. There is a critical need for high-performing text simplification models for health information to enhance dissemination and literacy. This need is particularly acute in cancer education, where effective prevention and screening education can substantially reduce morbidity and mortality.</p></div><div><h3>Methods:</h3><p>We introduce <em>Simplified Digestive Cancer</em> (SimpleDC), a parallel corpus of cancer education materials tailored for health text simplification research, comprising educational content from the American Cancer Society, Centers for Disease Control and Prevention, and National Cancer Institute. The corpus includes 31 web pages with the corresponding manually simplified versions. It consists of 1183 annotated sentence pairs (361 train, 294 development, and 528 test). Utilizing SimpleDC and the existing Med-EASi corpus, we explore Large Language Model (LLM)-based simplification methods, including fine-tuning, reinforcement learning (RL), reinforcement learning with human feedback (RLHF), domain adaptation, and prompt-based approaches. Our experimentation encompasses Llama 2, Llama 3, and GPT-4. We introduce a novel RLHF reward function featuring a lightweight model adept at distinguishing between original and simplified texts when enables training on unlabeled data.</p></div><div><h3>Results:</h3><p>Fine-tuned Llama models demonstrated high performance across various metrics. Our RLHF reward function outperformed existing RL text simplification reward functions. The results underscore that RL/RLHF can achieve performance comparable to fine-tuning and improve the performance of fine-tuned models. Additionally, these methods effectively adapt out-of-domain text simplification models to a target domain. The best-performing RL-enhanced Llama models outperformed GPT-4 in both automatic metrics and manual evaluation by subject matter experts.</p></div><div><h3>Conclusion:</h3><p>The newly developed SimpleDC corpus will serve as a valuable asset to the research community, particularly in patient education simplification. The RL/RLHF methodologies presented herein enable effective training of simplification models on unlabeled text and the utilization of out-of-domain simplification corpora.</p></div>","PeriodicalId":15263,"journal":{"name":"Journal of Biomedical Informatics","volume":"158 ","pages":"Article 104727"},"PeriodicalIF":4.0000,"publicationDate":"2024-09-16","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":"{\"title\":\"Health text simplification: An annotated corpus for digestive cancer education and novel strategies for reinforcement learning\",\"authors\":\"Md Mushfiqur Rahman , Mohammad Sabik Irbaz , Kai North, Michelle S. Williams, Marcos Zampieri, Kevin Lybarger\",\"doi\":\"10.1016/j.jbi.2024.104727\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<div><h3>Objective:</h3><p>The reading level of health educational materials significantly influences the understandability and accessibility of the information, particularly for minoritized populations. Many patient educational resources surpass widely accepted standards for reading level and complexity. There is a critical need for high-performing text simplification models for health information to enhance dissemination and literacy. This need is particularly acute in cancer education, where effective prevention and screening education can substantially reduce morbidity and mortality.</p></div><div><h3>Methods:</h3><p>We introduce <em>Simplified Digestive Cancer</em> (SimpleDC), a parallel corpus of cancer education materials tailored for health text simplification research, comprising educational content from the American Cancer Society, Centers for Disease Control and Prevention, and National Cancer Institute. The corpus includes 31 web pages with the corresponding manually simplified versions. It consists of 1183 annotated sentence pairs (361 train, 294 development, and 528 test). Utilizing SimpleDC and the existing Med-EASi corpus, we explore Large Language Model (LLM)-based simplification methods, including fine-tuning, reinforcement learning (RL), reinforcement learning with human feedback (RLHF), domain adaptation, and prompt-based approaches. Our experimentation encompasses Llama 2, Llama 3, and GPT-4. We introduce a novel RLHF reward function featuring a lightweight model adept at distinguishing between original and simplified texts when enables training on unlabeled data.</p></div><div><h3>Results:</h3><p>Fine-tuned Llama models demonstrated high performance across various metrics. Our RLHF reward function outperformed existing RL text simplification reward functions. The results underscore that RL/RLHF can achieve performance comparable to fine-tuning and improve the performance of fine-tuned models. Additionally, these methods effectively adapt out-of-domain text simplification models to a target domain. The best-performing RL-enhanced Llama models outperformed GPT-4 in both automatic metrics and manual evaluation by subject matter experts.</p></div><div><h3>Conclusion:</h3><p>The newly developed SimpleDC corpus will serve as a valuable asset to the research community, particularly in patient education simplification. The RL/RLHF methodologies presented herein enable effective training of simplification models on unlabeled text and the utilization of out-of-domain simplification corpora.</p></div>\",\"PeriodicalId\":15263,\"journal\":{\"name\":\"Journal of Biomedical Informatics\",\"volume\":\"158 \",\"pages\":\"Article 104727\"},\"PeriodicalIF\":4.0000,\"publicationDate\":\"2024-09-16\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Journal of Biomedical Informatics\",\"FirstCategoryId\":\"3\",\"ListUrlMain\":\"https://www.sciencedirect.com/science/article/pii/S153204642400145X\",\"RegionNum\":2,\"RegionCategory\":\"医学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q2\",\"JCRName\":\"COMPUTER SCIENCE, INTERDISCIPLINARY APPLICATIONS\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Journal of Biomedical Informatics","FirstCategoryId":"3","ListUrlMain":"https://www.sciencedirect.com/science/article/pii/S153204642400145X","RegionNum":2,"RegionCategory":"医学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q2","JCRName":"COMPUTER SCIENCE, INTERDISCIPLINARY APPLICATIONS","Score":null,"Total":0}
Health text simplification: An annotated corpus for digestive cancer education and novel strategies for reinforcement learning
Objective:
The reading level of health educational materials significantly influences the understandability and accessibility of the information, particularly for minoritized populations. Many patient educational resources surpass widely accepted standards for reading level and complexity. There is a critical need for high-performing text simplification models for health information to enhance dissemination and literacy. This need is particularly acute in cancer education, where effective prevention and screening education can substantially reduce morbidity and mortality.
Methods:
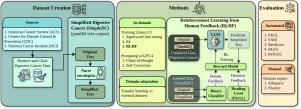
We introduce Simplified Digestive Cancer (SimpleDC), a parallel corpus of cancer education materials tailored for health text simplification research, comprising educational content from the American Cancer Society, Centers for Disease Control and Prevention, and National Cancer Institute. The corpus includes 31 web pages with the corresponding manually simplified versions. It consists of 1183 annotated sentence pairs (361 train, 294 development, and 528 test). Utilizing SimpleDC and the existing Med-EASi corpus, we explore Large Language Model (LLM)-based simplification methods, including fine-tuning, reinforcement learning (RL), reinforcement learning with human feedback (RLHF), domain adaptation, and prompt-based approaches. Our experimentation encompasses Llama 2, Llama 3, and GPT-4. We introduce a novel RLHF reward function featuring a lightweight model adept at distinguishing between original and simplified texts when enables training on unlabeled data.
Results:
Fine-tuned Llama models demonstrated high performance across various metrics. Our RLHF reward function outperformed existing RL text simplification reward functions. The results underscore that RL/RLHF can achieve performance comparable to fine-tuning and improve the performance of fine-tuned models. Additionally, these methods effectively adapt out-of-domain text simplification models to a target domain. The best-performing RL-enhanced Llama models outperformed GPT-4 in both automatic metrics and manual evaluation by subject matter experts.
Conclusion:
The newly developed SimpleDC corpus will serve as a valuable asset to the research community, particularly in patient education simplification. The RL/RLHF methodologies presented herein enable effective training of simplification models on unlabeled text and the utilization of out-of-domain simplification corpora.
期刊介绍:
The Journal of Biomedical Informatics reflects a commitment to high-quality original research papers, reviews, and commentaries in the area of biomedical informatics methodology. Although we publish articles motivated by applications in the biomedical sciences (for example, clinical medicine, health care, population health, and translational bioinformatics), the journal emphasizes reports of new methodologies and techniques that have general applicability and that form the basis for the evolving science of biomedical informatics. Articles on medical devices; evaluations of implemented systems (including clinical trials of information technologies); or papers that provide insight into a biological process, a specific disease, or treatment options would generally be more suitable for publication in other venues. Papers on applications of signal processing and image analysis are often more suitable for biomedical engineering journals or other informatics journals, although we do publish papers that emphasize the information management and knowledge representation/modeling issues that arise in the storage and use of biological signals and images. System descriptions are welcome if they illustrate and substantiate the underlying methodology that is the principal focus of the report and an effort is made to address the generalizability and/or range of application of that methodology. Note also that, given the international nature of JBI, papers that deal with specific languages other than English, or with country-specific health systems or approaches, are acceptable for JBI only if they offer generalizable lessons that are relevant to the broad JBI readership, regardless of their country, language, culture, or health system.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


