Shengyang Li , Paul Dexter , Zina Ben-Miled , Malaz Boustani
{"title":"利用医疗记录中以决策为重点的内容选择预测痴呆症风险","authors":"Shengyang Li , Paul Dexter , Zina Ben-Miled , Malaz Boustani","doi":"10.1016/j.compbiomed.2024.109144","DOIUrl":null,"url":null,"abstract":"<div><p>Several general-purpose language model (LM) architectures have been proposed with demonstrated improvement in text summarization and classification. Adapting these architectures to the medical domain requires additional considerations. For instance, the medical history of the patient is documented in the Electronic Health Record (EHR) which includes many medical notes drafted by healthcare providers. Direct processing of these notes may not be possible because the computational complexity of LMs imposes a limit on the length of input text. Therefore, previous applications resorted to content selection using truncation or summarization of the text. Unfortunately, these text processing techniques may lead to information loss, redundancy or irrelevance. In the present paper, a decision-focused content selection technique is proposed. The objective of this technique is to select a subset of sentences from the medical notes of a patient that are relevant to the target outcome over a predefined observation period. This decision-focused content selection methodology is then used to develop a dementia risk prediction model based on the Longformer LM architecture. The results show that the proposed framework delivers an AUC of 78.43 when the summary is restricted to 1024 tokens, outperforming previously proposed content selection techniques. This performance is notable given that the model estimates dementia risk with a one year prediction horizon, relies on an observation period of only one year and solely uses medical notes without other EHR data modalities. Moreover, the proposed techniques overcome the limitation of machine learning models that use a tabular representation of the text by preserving contextual content, enable feature engineering from raw text and circumvent the computational complexity of language models.</p></div>","PeriodicalId":10578,"journal":{"name":"Computers in biology and medicine","volume":"182 ","pages":"Article 109144"},"PeriodicalIF":7.0000,"publicationDate":"2024-09-18","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.sciencedirect.com/science/article/pii/S0010482524012290/pdfft?md5=ddbfc06a7da2d947792411e6736de734&pid=1-s2.0-S0010482524012290-main.pdf","citationCount":"0","resultStr":"{\"title\":\"Dementia risk prediction using decision-focused content selection from medical notes\",\"authors\":\"Shengyang Li , Paul Dexter , Zina Ben-Miled , Malaz Boustani\",\"doi\":\"10.1016/j.compbiomed.2024.109144\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<div><p>Several general-purpose language model (LM) architectures have been proposed with demonstrated improvement in text summarization and classification. Adapting these architectures to the medical domain requires additional considerations. For instance, the medical history of the patient is documented in the Electronic Health Record (EHR) which includes many medical notes drafted by healthcare providers. Direct processing of these notes may not be possible because the computational complexity of LMs imposes a limit on the length of input text. Therefore, previous applications resorted to content selection using truncation or summarization of the text. Unfortunately, these text processing techniques may lead to information loss, redundancy or irrelevance. In the present paper, a decision-focused content selection technique is proposed. The objective of this technique is to select a subset of sentences from the medical notes of a patient that are relevant to the target outcome over a predefined observation period. This decision-focused content selection methodology is then used to develop a dementia risk prediction model based on the Longformer LM architecture. The results show that the proposed framework delivers an AUC of 78.43 when the summary is restricted to 1024 tokens, outperforming previously proposed content selection techniques. This performance is notable given that the model estimates dementia risk with a one year prediction horizon, relies on an observation period of only one year and solely uses medical notes without other EHR data modalities. Moreover, the proposed techniques overcome the limitation of machine learning models that use a tabular representation of the text by preserving contextual content, enable feature engineering from raw text and circumvent the computational complexity of language models.</p></div>\",\"PeriodicalId\":10578,\"journal\":{\"name\":\"Computers in biology and medicine\",\"volume\":\"182 \",\"pages\":\"Article 109144\"},\"PeriodicalIF\":7.0000,\"publicationDate\":\"2024-09-18\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.sciencedirect.com/science/article/pii/S0010482524012290/pdfft?md5=ddbfc06a7da2d947792411e6736de734&pid=1-s2.0-S0010482524012290-main.pdf\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Computers in biology and medicine\",\"FirstCategoryId\":\"5\",\"ListUrlMain\":\"https://www.sciencedirect.com/science/article/pii/S0010482524012290\",\"RegionNum\":2,\"RegionCategory\":\"医学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q1\",\"JCRName\":\"BIOLOGY\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Computers in biology and medicine","FirstCategoryId":"5","ListUrlMain":"https://www.sciencedirect.com/science/article/pii/S0010482524012290","RegionNum":2,"RegionCategory":"医学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"BIOLOGY","Score":null,"Total":0}
Dementia risk prediction using decision-focused content selection from medical notes
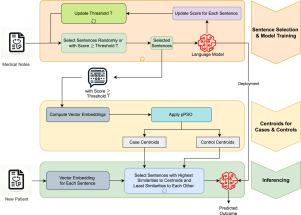
Several general-purpose language model (LM) architectures have been proposed with demonstrated improvement in text summarization and classification. Adapting these architectures to the medical domain requires additional considerations. For instance, the medical history of the patient is documented in the Electronic Health Record (EHR) which includes many medical notes drafted by healthcare providers. Direct processing of these notes may not be possible because the computational complexity of LMs imposes a limit on the length of input text. Therefore, previous applications resorted to content selection using truncation or summarization of the text. Unfortunately, these text processing techniques may lead to information loss, redundancy or irrelevance. In the present paper, a decision-focused content selection technique is proposed. The objective of this technique is to select a subset of sentences from the medical notes of a patient that are relevant to the target outcome over a predefined observation period. This decision-focused content selection methodology is then used to develop a dementia risk prediction model based on the Longformer LM architecture. The results show that the proposed framework delivers an AUC of 78.43 when the summary is restricted to 1024 tokens, outperforming previously proposed content selection techniques. This performance is notable given that the model estimates dementia risk with a one year prediction horizon, relies on an observation period of only one year and solely uses medical notes without other EHR data modalities. Moreover, the proposed techniques overcome the limitation of machine learning models that use a tabular representation of the text by preserving contextual content, enable feature engineering from raw text and circumvent the computational complexity of language models.
期刊介绍:
Computers in Biology and Medicine is an international forum for sharing groundbreaking advancements in the use of computers in bioscience and medicine. This journal serves as a medium for communicating essential research, instruction, ideas, and information regarding the rapidly evolving field of computer applications in these domains. By encouraging the exchange of knowledge, we aim to facilitate progress and innovation in the utilization of computers in biology and medicine.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


