Soumajit Pramanik , Jesujoba Alabi , Rishiraj Saha Roy , Gerhard Weikum
{"title":"Uniqorn:通过 RDF 知识图谱和自然语言文本进行统一问题解答","authors":"Soumajit Pramanik , Jesujoba Alabi , Rishiraj Saha Roy , Gerhard Weikum","doi":"10.1016/j.websem.2024.100833","DOIUrl":null,"url":null,"abstract":"<div><p>Question answering over RDF data like knowledge graphs has been greatly advanced, with a number of good systems providing crisp answers for natural language questions or telegraphic queries. Some of these systems incorporate textual sources as additional evidence for the answering process, but cannot compute answers that are present in text alone. Conversely, the IR and NLP communities have addressed QA over text, but such systems barely utilize semantic data and knowledge. This paper presents a method for <em>complex questions</em> that can seamlessly operate over a mixture of RDF datasets and text corpora, or individual sources, in a unified framework. Our method, called <span>Uniqorn</span>, builds a context graph on-the-fly, by retrieving question-relevant evidences from the RDF data and/or a text corpus, using fine-tuned BERT models. The resulting graph typically contains all question-relevant evidences but also a lot of noise. <span>Uniqorn</span> copes with this input by a graph algorithm for Group Steiner Trees, that identifies the best answer candidates in the context graph. Experimental results on several benchmarks of complex questions with multiple entities and relations, show that <span>Uniqorn</span> significantly outperforms state-of-the-art methods for <em>heterogeneous QA</em> – in a full training mode, as well as in zero-shot settings. The graph-based methodology provides user-interpretable evidence for the complete answering process.</p></div>","PeriodicalId":49951,"journal":{"name":"Journal of Web Semantics","volume":"83 ","pages":"Article 100833"},"PeriodicalIF":3.1000,"publicationDate":"2024-09-10","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.sciencedirect.com/science/article/pii/S1570826824000192/pdfft?md5=1b3a7cdd704527ca28fe0609b32bbd44&pid=1-s2.0-S1570826824000192-main.pdf","citationCount":"0","resultStr":"{\"title\":\"Uniqorn: Unified question answering over RDF knowledge graphs and natural language text\",\"authors\":\"Soumajit Pramanik , Jesujoba Alabi , Rishiraj Saha Roy , Gerhard Weikum\",\"doi\":\"10.1016/j.websem.2024.100833\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<div><p>Question answering over RDF data like knowledge graphs has been greatly advanced, with a number of good systems providing crisp answers for natural language questions or telegraphic queries. Some of these systems incorporate textual sources as additional evidence for the answering process, but cannot compute answers that are present in text alone. Conversely, the IR and NLP communities have addressed QA over text, but such systems barely utilize semantic data and knowledge. This paper presents a method for <em>complex questions</em> that can seamlessly operate over a mixture of RDF datasets and text corpora, or individual sources, in a unified framework. Our method, called <span>Uniqorn</span>, builds a context graph on-the-fly, by retrieving question-relevant evidences from the RDF data and/or a text corpus, using fine-tuned BERT models. The resulting graph typically contains all question-relevant evidences but also a lot of noise. <span>Uniqorn</span> copes with this input by a graph algorithm for Group Steiner Trees, that identifies the best answer candidates in the context graph. Experimental results on several benchmarks of complex questions with multiple entities and relations, show that <span>Uniqorn</span> significantly outperforms state-of-the-art methods for <em>heterogeneous QA</em> – in a full training mode, as well as in zero-shot settings. The graph-based methodology provides user-interpretable evidence for the complete answering process.</p></div>\",\"PeriodicalId\":49951,\"journal\":{\"name\":\"Journal of Web Semantics\",\"volume\":\"83 \",\"pages\":\"Article 100833\"},\"PeriodicalIF\":3.1000,\"publicationDate\":\"2024-09-10\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.sciencedirect.com/science/article/pii/S1570826824000192/pdfft?md5=1b3a7cdd704527ca28fe0609b32bbd44&pid=1-s2.0-S1570826824000192-main.pdf\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Journal of Web Semantics\",\"FirstCategoryId\":\"94\",\"ListUrlMain\":\"https://www.sciencedirect.com/science/article/pii/S1570826824000192\",\"RegionNum\":3,\"RegionCategory\":\"计算机科学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q3\",\"JCRName\":\"COMPUTER SCIENCE, ARTIFICIAL INTELLIGENCE\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Journal of Web Semantics","FirstCategoryId":"94","ListUrlMain":"https://www.sciencedirect.com/science/article/pii/S1570826824000192","RegionNum":3,"RegionCategory":"计算机科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q3","JCRName":"COMPUTER SCIENCE, ARTIFICIAL INTELLIGENCE","Score":null,"Total":0}
Uniqorn: Unified question answering over RDF knowledge graphs and natural language text
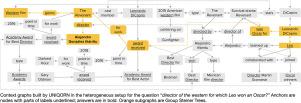
Question answering over RDF data like knowledge graphs has been greatly advanced, with a number of good systems providing crisp answers for natural language questions or telegraphic queries. Some of these systems incorporate textual sources as additional evidence for the answering process, but cannot compute answers that are present in text alone. Conversely, the IR and NLP communities have addressed QA over text, but such systems barely utilize semantic data and knowledge. This paper presents a method for complex questions that can seamlessly operate over a mixture of RDF datasets and text corpora, or individual sources, in a unified framework. Our method, called Uniqorn, builds a context graph on-the-fly, by retrieving question-relevant evidences from the RDF data and/or a text corpus, using fine-tuned BERT models. The resulting graph typically contains all question-relevant evidences but also a lot of noise. Uniqorn copes with this input by a graph algorithm for Group Steiner Trees, that identifies the best answer candidates in the context graph. Experimental results on several benchmarks of complex questions with multiple entities and relations, show that Uniqorn significantly outperforms state-of-the-art methods for heterogeneous QA – in a full training mode, as well as in zero-shot settings. The graph-based methodology provides user-interpretable evidence for the complete answering process.
期刊介绍:
The Journal of Web Semantics is an interdisciplinary journal based on research and applications of various subject areas that contribute to the development of a knowledge-intensive and intelligent service Web. These areas include: knowledge technologies, ontology, agents, databases and the semantic grid, obviously disciplines like information retrieval, language technology, human-computer interaction and knowledge discovery are of major relevance as well. All aspects of the Semantic Web development are covered. The publication of large-scale experiments and their analysis is also encouraged to clearly illustrate scenarios and methods that introduce semantics into existing Web interfaces, contents and services. The journal emphasizes the publication of papers that combine theories, methods and experiments from different subject areas in order to deliver innovative semantic methods and applications.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


