{"title":"支持普适应用的数据和资源感知增量 ML 训练","authors":"Thanasis Moustakas, Athanasios Tziouvaras, Kostas Kolomvatsos","doi":"10.1007/s00607-024-01338-2","DOIUrl":null,"url":null,"abstract":"<p>Nowadays, the use of Artificial Intelligence (AI) and Machine Learning (ML) algorithms is increasingly affecting the performance of innovative systems. At the same time, the advent of the Internet of Things (IoT) and the Edge Computing (EC) as means to place computational resources close to users create the need for new models in the training process of ML schemes due to the limited computational capabilities of the devices/nodes placed there. In any case, we should not forget that IoT devices or EC nodes exhibit less capabilities than the Cloud back end that could be adopted for a more complex training upon vast volumes of data. The ideal case is to have, at least, basic training capabilities at the IoT-EC ecosystem in order to reduce the latency and face the needs of near real time applications. In this paper, we are motivated by this need and propose a model that tries to save time in the training process by focusing on the training dataset and its statistical description. We do not dive into the architecture of any ML model as we target to provide a more generic scheme that can be applied upon any ML module. We monitor the statistics of the training dataset and the loss during the process and identify if there is a potential to stop it when not significant contribution is foreseen for the data not yet adopted in the model. We argue that our approach can be applied only when a negligibly decreased accuracy is acceptable by the application gaining time and resources from the training process. We provide two algorithms for applying this approach and an extensive experimental evaluation upon multiple supervised ML models to reveal the benefits of the proposed scheme and its constraints.</p>","PeriodicalId":10718,"journal":{"name":"Computing","volume":"21 1","pages":""},"PeriodicalIF":2.8000,"publicationDate":"2024-08-16","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":"{\"title\":\"Data and resource aware incremental ML training in support of pervasive applications\",\"authors\":\"Thanasis Moustakas, Athanasios Tziouvaras, Kostas Kolomvatsos\",\"doi\":\"10.1007/s00607-024-01338-2\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p>Nowadays, the use of Artificial Intelligence (AI) and Machine Learning (ML) algorithms is increasingly affecting the performance of innovative systems. At the same time, the advent of the Internet of Things (IoT) and the Edge Computing (EC) as means to place computational resources close to users create the need for new models in the training process of ML schemes due to the limited computational capabilities of the devices/nodes placed there. In any case, we should not forget that IoT devices or EC nodes exhibit less capabilities than the Cloud back end that could be adopted for a more complex training upon vast volumes of data. The ideal case is to have, at least, basic training capabilities at the IoT-EC ecosystem in order to reduce the latency and face the needs of near real time applications. In this paper, we are motivated by this need and propose a model that tries to save time in the training process by focusing on the training dataset and its statistical description. We do not dive into the architecture of any ML model as we target to provide a more generic scheme that can be applied upon any ML module. We monitor the statistics of the training dataset and the loss during the process and identify if there is a potential to stop it when not significant contribution is foreseen for the data not yet adopted in the model. We argue that our approach can be applied only when a negligibly decreased accuracy is acceptable by the application gaining time and resources from the training process. We provide two algorithms for applying this approach and an extensive experimental evaluation upon multiple supervised ML models to reveal the benefits of the proposed scheme and its constraints.</p>\",\"PeriodicalId\":10718,\"journal\":{\"name\":\"Computing\",\"volume\":\"21 1\",\"pages\":\"\"},\"PeriodicalIF\":2.8000,\"publicationDate\":\"2024-08-16\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Computing\",\"FirstCategoryId\":\"94\",\"ListUrlMain\":\"https://doi.org/10.1007/s00607-024-01338-2\",\"RegionNum\":3,\"RegionCategory\":\"计算机科学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q2\",\"JCRName\":\"COMPUTER SCIENCE, THEORY & METHODS\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Computing","FirstCategoryId":"94","ListUrlMain":"https://doi.org/10.1007/s00607-024-01338-2","RegionNum":3,"RegionCategory":"计算机科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q2","JCRName":"COMPUTER SCIENCE, THEORY & METHODS","Score":null,"Total":0}
引用次数: 0
摘要
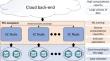
如今,人工智能(AI)和机器学习(ML)算法的使用正日益影响创新系统的性能。同时,物联网(IoT)和边缘计算(EC)作为将计算资源放置在用户附近的手段,由于放置在那里的设备/节点的计算能力有限,因此在 ML 方案的训练过程中需要新的模型。无论如何,我们都不应忘记,物联网设备或 EC 节点的能力不如云后端,而云后端可用于对海量数据进行更复杂的训练。理想的情况是,物联网-EC 生态系统至少具备基本的训练能力,以减少延迟并满足近实时应用的需求。在本文中,我们正是基于这一需求,提出了一个模型,该模型试图通过关注训练数据集及其统计描述来节省训练过程中的时间。我们没有深入研究任何 ML 模型的架构,因为我们的目标是提供一种可应用于任何 ML 模块的通用方案。我们监控训练数据集的统计信息和过程中的损失,并确定在模型中尚未采用的数据预计不会有重大贡献时,是否有可能停止训练。我们认为,我们的方法只有在精确度下降到可以忽略不计的程度,并且应用程序可以从训练过程中获得时间和资源的情况下才能使用。我们提供了两种应用这种方法的算法,并对多个有监督的 ML 模型进行了广泛的实验评估,以揭示所提方案的优势及其限制因素。
Data and resource aware incremental ML training in support of pervasive applications
Nowadays, the use of Artificial Intelligence (AI) and Machine Learning (ML) algorithms is increasingly affecting the performance of innovative systems. At the same time, the advent of the Internet of Things (IoT) and the Edge Computing (EC) as means to place computational resources close to users create the need for new models in the training process of ML schemes due to the limited computational capabilities of the devices/nodes placed there. In any case, we should not forget that IoT devices or EC nodes exhibit less capabilities than the Cloud back end that could be adopted for a more complex training upon vast volumes of data. The ideal case is to have, at least, basic training capabilities at the IoT-EC ecosystem in order to reduce the latency and face the needs of near real time applications. In this paper, we are motivated by this need and propose a model that tries to save time in the training process by focusing on the training dataset and its statistical description. We do not dive into the architecture of any ML model as we target to provide a more generic scheme that can be applied upon any ML module. We monitor the statistics of the training dataset and the loss during the process and identify if there is a potential to stop it when not significant contribution is foreseen for the data not yet adopted in the model. We argue that our approach can be applied only when a negligibly decreased accuracy is acceptable by the application gaining time and resources from the training process. We provide two algorithms for applying this approach and an extensive experimental evaluation upon multiple supervised ML models to reveal the benefits of the proposed scheme and its constraints.
期刊介绍:
Computing publishes original papers, short communications and surveys on all fields of computing. The contributions should be written in English and may be of theoretical or applied nature, the essential criteria are computational relevance and systematic foundation of results.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


