Jihong Ouyang, Zhengjie Zhang, Qingyi Meng, Ximing Li, Jinjin Chi
{"title":"利用多层次一致性学习实现无源域适应","authors":"Jihong Ouyang, Zhengjie Zhang, Qingyi Meng, Ximing Li, Jinjin Chi","doi":"10.1007/s00530-024-01444-3","DOIUrl":null,"url":null,"abstract":"<p>Due to data privacy concerns, a more practical task known as Source-free Unsupervised Domain Adaptation (SFUDA) has gained significant attention recently. SFUDA adapts a pre-trained source model to the target domain without access to the source domain data. Existing SFUDA methods typically rely on per-class cluster structure to refine labels. However, these clusters often contain samples with different ground truth labels, leading to label noise. To address this issue, we propose a novel Multi-level Consistency Learning (MLCL) method. MLCL focuses on learning discriminative class-wise target feature representations, resulting in more accurate cluster structures. Specifically, at the inter-domain level, we construct pseudo-source domain data based on the entropy criterion. We align pseudo-labeled target domain sample with corresponding pseudo-source domain prototype by introducing a prototype contrastive loss. This loss ensures that our model can learn discriminative class-wise feature representations effectively. At the intra-domain level, we enforce consistency among different views of the same image by employing consistency-based self-training. The self-training further enhances the feature representation ability of our model. Additionally, we apply information maximization regularization to facilitate target sample clustering and promote diversity. Our extensive experiments conducted on four benchmark datasets for classification demonstrate the superior performance of the proposed MLCL method. The code is here.</p>","PeriodicalId":51138,"journal":{"name":"Multimedia Systems","volume":"58 1","pages":""},"PeriodicalIF":3.1000,"publicationDate":"2024-08-16","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":"{\"title\":\"Exploiting multi-level consistency learning for source-free domain adaptation\",\"authors\":\"Jihong Ouyang, Zhengjie Zhang, Qingyi Meng, Ximing Li, Jinjin Chi\",\"doi\":\"10.1007/s00530-024-01444-3\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p>Due to data privacy concerns, a more practical task known as Source-free Unsupervised Domain Adaptation (SFUDA) has gained significant attention recently. SFUDA adapts a pre-trained source model to the target domain without access to the source domain data. Existing SFUDA methods typically rely on per-class cluster structure to refine labels. However, these clusters often contain samples with different ground truth labels, leading to label noise. To address this issue, we propose a novel Multi-level Consistency Learning (MLCL) method. MLCL focuses on learning discriminative class-wise target feature representations, resulting in more accurate cluster structures. Specifically, at the inter-domain level, we construct pseudo-source domain data based on the entropy criterion. We align pseudo-labeled target domain sample with corresponding pseudo-source domain prototype by introducing a prototype contrastive loss. This loss ensures that our model can learn discriminative class-wise feature representations effectively. At the intra-domain level, we enforce consistency among different views of the same image by employing consistency-based self-training. The self-training further enhances the feature representation ability of our model. Additionally, we apply information maximization regularization to facilitate target sample clustering and promote diversity. Our extensive experiments conducted on four benchmark datasets for classification demonstrate the superior performance of the proposed MLCL method. The code is here.</p>\",\"PeriodicalId\":51138,\"journal\":{\"name\":\"Multimedia Systems\",\"volume\":\"58 1\",\"pages\":\"\"},\"PeriodicalIF\":3.1000,\"publicationDate\":\"2024-08-16\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Multimedia Systems\",\"FirstCategoryId\":\"94\",\"ListUrlMain\":\"https://doi.org/10.1007/s00530-024-01444-3\",\"RegionNum\":3,\"RegionCategory\":\"计算机科学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q2\",\"JCRName\":\"COMPUTER SCIENCE, INFORMATION SYSTEMS\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Multimedia Systems","FirstCategoryId":"94","ListUrlMain":"https://doi.org/10.1007/s00530-024-01444-3","RegionNum":3,"RegionCategory":"计算机科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q2","JCRName":"COMPUTER SCIENCE, INFORMATION SYSTEMS","Score":null,"Total":0}
Exploiting multi-level consistency learning for source-free domain adaptation
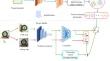
Due to data privacy concerns, a more practical task known as Source-free Unsupervised Domain Adaptation (SFUDA) has gained significant attention recently. SFUDA adapts a pre-trained source model to the target domain without access to the source domain data. Existing SFUDA methods typically rely on per-class cluster structure to refine labels. However, these clusters often contain samples with different ground truth labels, leading to label noise. To address this issue, we propose a novel Multi-level Consistency Learning (MLCL) method. MLCL focuses on learning discriminative class-wise target feature representations, resulting in more accurate cluster structures. Specifically, at the inter-domain level, we construct pseudo-source domain data based on the entropy criterion. We align pseudo-labeled target domain sample with corresponding pseudo-source domain prototype by introducing a prototype contrastive loss. This loss ensures that our model can learn discriminative class-wise feature representations effectively. At the intra-domain level, we enforce consistency among different views of the same image by employing consistency-based self-training. The self-training further enhances the feature representation ability of our model. Additionally, we apply information maximization regularization to facilitate target sample clustering and promote diversity. Our extensive experiments conducted on four benchmark datasets for classification demonstrate the superior performance of the proposed MLCL method. The code is here.
期刊介绍:
This journal details innovative research ideas, emerging technologies, state-of-the-art methods and tools in all aspects of multimedia computing, communication, storage, and applications. It features theoretical, experimental, and survey articles.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


