{"title":"利用模糊均值聚类提高深度学习模型的性能","authors":"Saumya Singh, Smriti Srivastava","doi":"10.1007/s10115-024-02211-6","DOIUrl":null,"url":null,"abstract":"<p>Deep learning models (DLMs), such as recurrent neural networks (RNN), long short-term memory (LSTM), bidirectional long short-term memory (Bi-LSTM), and gated recurrent unit (GRU), are superior for sequential data analysis due to their ability to learn complex patterns. This paper proposes enhancing performance of these models by applying fuzzy c-means (FCM) clustering on sequential data from a nonlinear plant and the stock market. FCM clustering helps to organize the data into clusters based on similarity, which improves the performance of the models. Thus, the proposed fuzzy c-means recurrent neural network (FCM-RNN), fuzzy c-means long short-term memory (FCM-LSTM), fuzzy c-means bidirectional long short-term memory (FCM-Bi-LSTM), and fuzzy c-means gated recurrent unit (FCM-GRU) models showed enhanced prediction results than RNN, LSTM, Bi-LSTM, and GRU models, respectively. This enhancement is validated using performance metrics such as root-mean-square error and mean absolute error and is further illustrated by scatter plots comparing actual versus predicted values for training, validation, and testing data. The experiment results confirm that integrating FCM clustering with DLMs shows the superiority of the proposed models.</p>","PeriodicalId":54749,"journal":{"name":"Knowledge and Information Systems","volume":"36 1","pages":""},"PeriodicalIF":3.1000,"publicationDate":"2024-08-24","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":"{\"title\":\"Enhancing the performance of deep learning models with fuzzy c-means clustering\",\"authors\":\"Saumya Singh, Smriti Srivastava\",\"doi\":\"10.1007/s10115-024-02211-6\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p>Deep learning models (DLMs), such as recurrent neural networks (RNN), long short-term memory (LSTM), bidirectional long short-term memory (Bi-LSTM), and gated recurrent unit (GRU), are superior for sequential data analysis due to their ability to learn complex patterns. This paper proposes enhancing performance of these models by applying fuzzy c-means (FCM) clustering on sequential data from a nonlinear plant and the stock market. FCM clustering helps to organize the data into clusters based on similarity, which improves the performance of the models. Thus, the proposed fuzzy c-means recurrent neural network (FCM-RNN), fuzzy c-means long short-term memory (FCM-LSTM), fuzzy c-means bidirectional long short-term memory (FCM-Bi-LSTM), and fuzzy c-means gated recurrent unit (FCM-GRU) models showed enhanced prediction results than RNN, LSTM, Bi-LSTM, and GRU models, respectively. This enhancement is validated using performance metrics such as root-mean-square error and mean absolute error and is further illustrated by scatter plots comparing actual versus predicted values for training, validation, and testing data. The experiment results confirm that integrating FCM clustering with DLMs shows the superiority of the proposed models.</p>\",\"PeriodicalId\":54749,\"journal\":{\"name\":\"Knowledge and Information Systems\",\"volume\":\"36 1\",\"pages\":\"\"},\"PeriodicalIF\":3.1000,\"publicationDate\":\"2024-08-24\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Knowledge and Information Systems\",\"FirstCategoryId\":\"94\",\"ListUrlMain\":\"https://doi.org/10.1007/s10115-024-02211-6\",\"RegionNum\":4,\"RegionCategory\":\"计算机科学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q3\",\"JCRName\":\"COMPUTER SCIENCE, ARTIFICIAL INTELLIGENCE\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Knowledge and Information Systems","FirstCategoryId":"94","ListUrlMain":"https://doi.org/10.1007/s10115-024-02211-6","RegionNum":4,"RegionCategory":"计算机科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q3","JCRName":"COMPUTER SCIENCE, ARTIFICIAL INTELLIGENCE","Score":null,"Total":0}
Enhancing the performance of deep learning models with fuzzy c-means clustering
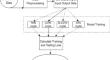
Deep learning models (DLMs), such as recurrent neural networks (RNN), long short-term memory (LSTM), bidirectional long short-term memory (Bi-LSTM), and gated recurrent unit (GRU), are superior for sequential data analysis due to their ability to learn complex patterns. This paper proposes enhancing performance of these models by applying fuzzy c-means (FCM) clustering on sequential data from a nonlinear plant and the stock market. FCM clustering helps to organize the data into clusters based on similarity, which improves the performance of the models. Thus, the proposed fuzzy c-means recurrent neural network (FCM-RNN), fuzzy c-means long short-term memory (FCM-LSTM), fuzzy c-means bidirectional long short-term memory (FCM-Bi-LSTM), and fuzzy c-means gated recurrent unit (FCM-GRU) models showed enhanced prediction results than RNN, LSTM, Bi-LSTM, and GRU models, respectively. This enhancement is validated using performance metrics such as root-mean-square error and mean absolute error and is further illustrated by scatter plots comparing actual versus predicted values for training, validation, and testing data. The experiment results confirm that integrating FCM clustering with DLMs shows the superiority of the proposed models.
期刊介绍:
Knowledge and Information Systems (KAIS) provides an international forum for researchers and professionals to share their knowledge and report new advances on all topics related to knowledge systems and advanced information systems. This monthly peer-reviewed archival journal publishes state-of-the-art research reports on emerging topics in KAIS, reviews of important techniques in related areas, and application papers of interest to a general readership.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


